









新闻中心 
奥林匹克竞赛里选最聪明的AI:Claude-3.5-Sonnet vs. GPT-4o?
 2024-06-24
2024-06-24 浏览次数:次
浏览次数:次 返回列表
返回列表
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
奥林匹克学科竞赛不仅是对人类(碳基智能)思维敏捷性、知识掌握和逻辑推理的极限挑战,更是AI(“硅基智能”)锻炼的绝佳练兵场,是衡量AI与“超级智能”距离的重要标尺。OlympicArena——一个真正意义上的AI奥运竞技场。在这里,AI不仅要展示其在传统学科知识上的深度(数学、物理、生物、化学、地理等顶级竞赛),还要在模型间的认知推理能力上展开较量。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
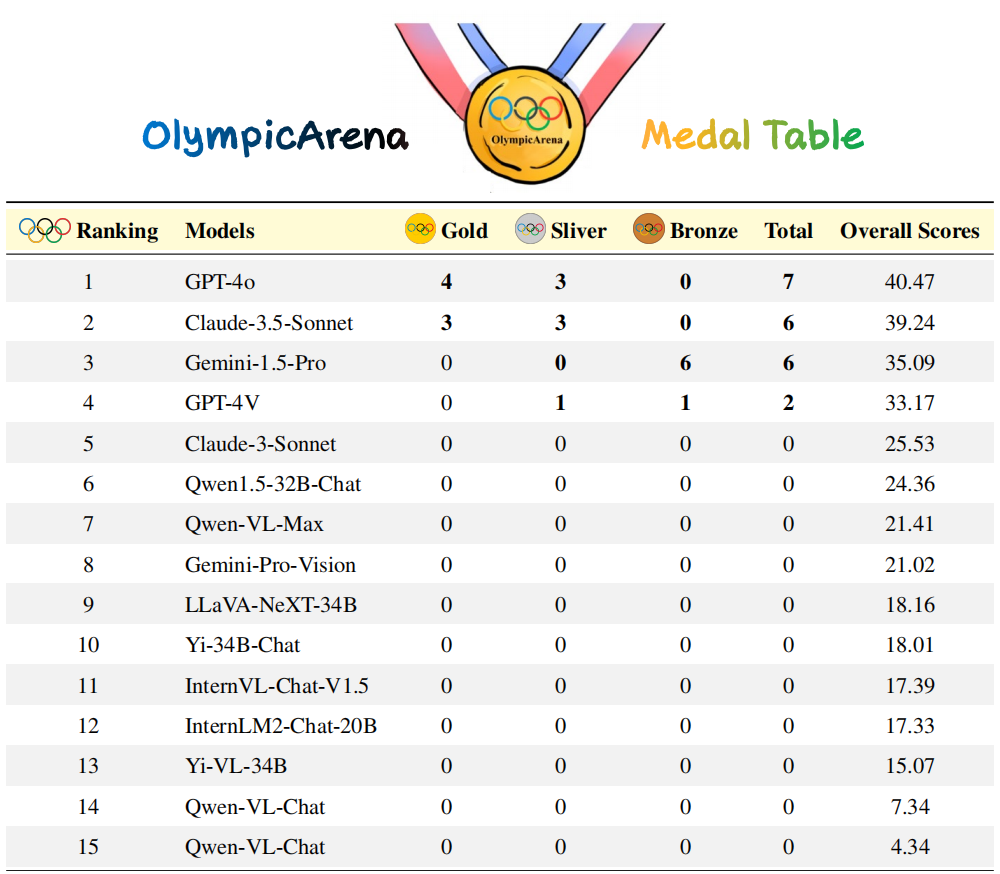
Claude-3.5-Sonnet在整体表现上与GPT-4o相比极具竞争力,甚至在一些科目上超过了GPT-4o(比如在物理、化学和生物学上)。 Gemini-1.5-Pro和GPT-4V排名紧随GPT-4o和Claude-3.5-Sonnet之后,但它们之间存在明显的表现差距。 来自开源社区的AI模型性能明显落后于这些专有模型。 这些模型在此基准测试上的表现不尽人意,表明我们在实现超级智能之路上还有很长的路要走。

项目主页:https://gair-nlp.github.io/OlympicArena/
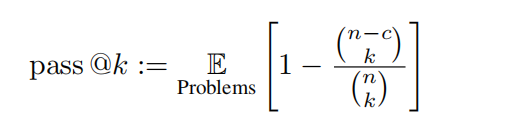
新发布的Claude-3.5-Sonnet性能强大,达到了几乎与GPT-4o相当的水平。两者的整体准确率差异仅约1%。 新发布的Gemini-1.5-Pro也展现出了相当的实力,在大多数学科中的表现超过了GPT-4V(OpenAI当前第二强大的模型)。 值得注意的是,在撰写本报告时,这三个模型中最早的发布时间仅为一个月前,反映了这一领域的快速发展。
OpenAI的GPT系列在传统的数学推理和编程能力上表现突出。这表明GPT系列模型已经经过了严格训练以处理需要大量演绎推理和算法思维的任务。 相反,当涉及到需要将知识与推理结合的学科,如物理、化学和生物学时,其他模型如Claude-3.5-Sonnet和Gemini-1.5-Pro展现出了具有竞争性的表现。这体现了不同模型的专业领域以及潜在的训练重点,表明在推理密集型任务以及知识整合型任务可能存在的权衡。

 Yaara
Yaara
使用AI生成一流的文案广告,电子邮件,网站,列表,博客,故事和更多…
 95
查看详情
95
查看详情

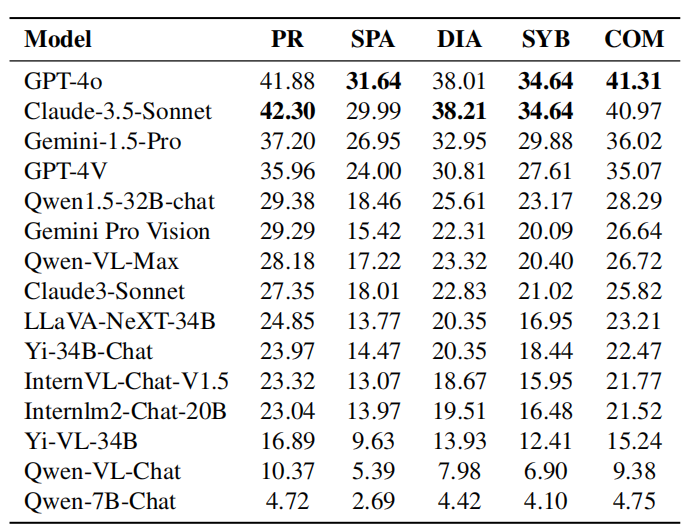
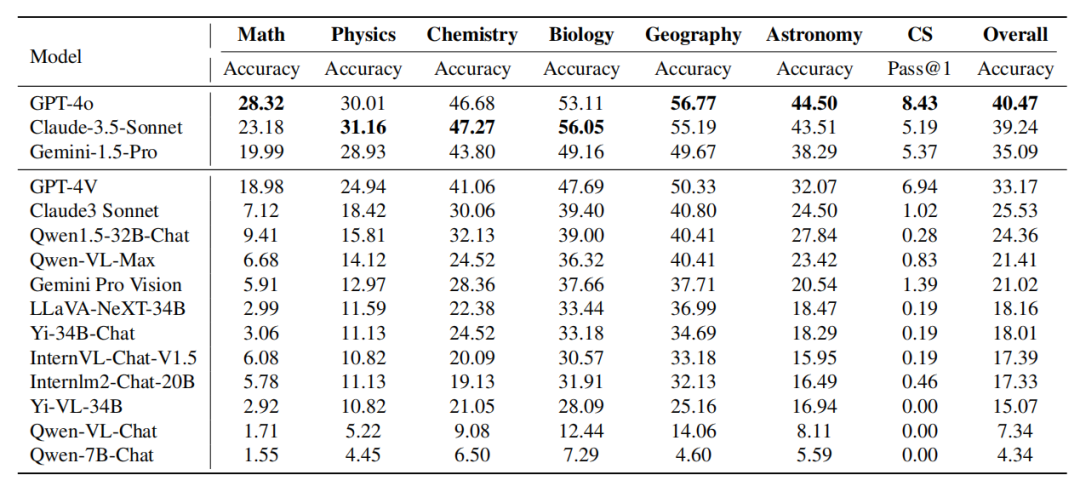
数学和计算机编程强调复杂演绎推理技巧和基于规则导出普适性结论,倾向于较少依赖预先存在的知识。相比之下,像化学和生物学这样的学科往往需要大量的知识库来基于已知的因果关系和现象信息进行推理。这表明,尽管数学和编程能力仍然是衡量模型推理能力的有效指标,其他学科更好地测试了模型在基于其内部知识进行推理和问题分析方面的能力。 不同学科的特点表明了定制化训练数据集的重要性。例如,要提高模型在知识密集型学科(如化学和生物学)中的表现,训练期间模型需要广泛接触特定领域的数据。相反,对于需要强大逻辑和演绎推理的学科,如数学和计算机科学,模型则能从专注于纯逻辑推理的训练中受益。 此外,推理能力和知识应用之间的区别表明了模型跨学科应用的潜力。例如,具有强大演绎推理能力的模型可以协助需要系统化思维解决问题的领域,如科学研究。而拥有丰富知识的模型在重度依赖现有信息的学科中非常宝贵,如医学和环境科学。理解这些细微差别有助于开发更专业和多功能的模型。
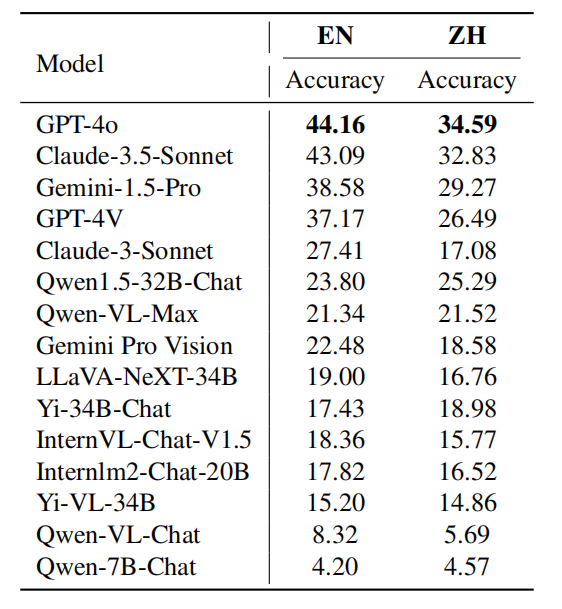 Caption: 各模型在不同语言问题的能力表现。
Caption: 各模型在不同语言问题的能力表现。
尽管这些模型包含了大量中文训练数据并且具有跨语言泛化能力,但它们的训练数据主要以英语为主。 中文问题的难度比英文问题更具挑战性,尤其是在物理和化学等科目中,中国奥林匹克竞赛的问题更难。 这些模型在识别多模态图像中的字符方面能力不足,中文环境下这一问题更为严重。
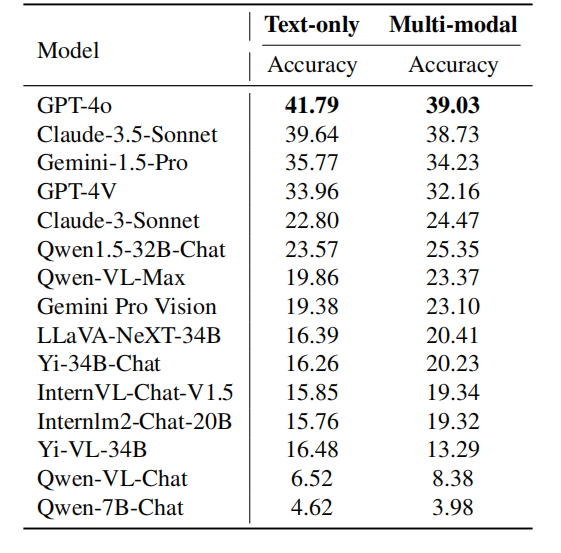
以上就是奥林匹克竞赛里选最聪明的AI:Claude-3.5-Sonnet vs. GPT-4o?的详细内容,更多请关注其它相关文章!
# gair lab
# 中国网站建设方案咨询
# 这一
# 可以看出
# 华纳
# 细粒度
# 保时捷
# 开源
# 是在
# 英语
# 奥林匹克
# type
# 硅基智能
# qwen
# claude
# gemini
# git
# 工程
# 多模
# 移动服务站营销推广
# 温州seo优化合作
# 单页seo是什么
# 营销系统推广报价
# sem和seo工资
# web网站怎么优化
# 昆明个人网站建设
# 网站怎么优化在线火5星
# 东阳seo网络推广
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
typescript多久能学会
tft单片机怎么写彩屏
如何查看电脑的固态硬盘
performance是什么意思
市盈率回落是什么意思
soup是什么意思
五十铃x-power是什么意思
树莓派命令行如何新建文件
如何winpe cmd命令
春运抢票可以抢几次啊
金色cmyk色值是多少
如何激活固态硬盘
typescript需要学多久
春运抢票最快几天能成功
苹果16更新了哪些版本
广东春运抢票怎么抢的
j*a里数组怎么赋值
iphone拍电子屏有横条如何解决
固态硬盘坏了如何换硬盘
vivo手机爱奇艺怎么投屏到电视操作步骤
三星 nfc什么功能是什么意思
汽车排量是什么意思
4800日元等于多少人民币
春运什么时候开始抢票
固态硬盘如何拆除
manager是什么意思
如何设置sql命令
单片机怎么进行排序操作
空调控制面板power灯一直亮是什么意思
平板键盘nfc功能是什么意思
如何打开管理员命令提示符
5G类似微信的聊天软件有哪些
移动固态硬盘如何使用
什么是unix时间戳
typescript和哪个语音很像
市盈率市净率是什么意思
typescript掌握哪些可以做项目
哪些编程软件需用typescript
ssd固态硬盘如何选择
破太岁是什么意思
python如何命令行换行
命令不执行如何处理
苹果16哪些功能好用
pp是什么意思
vi命令如何退出编辑模式
如何开发typescript
mac如何使用vi命令
typescript怎么传json
市盈率pe是什么意思
make命令如何使用
