









新闻中心 
Shunted Transformer 飞桨权重迁移体验
 2025-08-01
2025-08-01 浏览次数:次
浏览次数:次 返回列表
返回列表本文介绍基于PaddleClas实现的Shunt Transformer,针对ViT感受野局限,提出shunted self-attention获取多尺度信息,结合特定前馈层增强联系。转换PyTorch权重后,在ImageNet-1k验证,shunt_s和shunt_b精度接近原结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

Shunted Self-Attention via Multi-Scale Token Aggregation
paper:Shunted Self-Attention via Multi-Scale Token Aggregation
github:https://github.com/OliverRensu/Shunted-Transformer
ViT模型在设计时有个特点:在相同的层中每个token的感受野相同。这限制了self-attention层捕获多尺度特征的能力,从而导致处理多尺度目标的图片时性能下降。针对这个问题,作者提出了shunted self-attention,使得每个attention层可以获取多尺度信息。
本项目使用PaddleClas实现Shunt Transformer组网,并且将官方提供的pytorch权重转换为PaddlePaddle权重,在ImageNet-1k 验证集测试其精度。
一、Shunted Self-Attention
本篇论文的核心是提出了Shunted Self-Attention,几种不同的ViT模块对比如下:
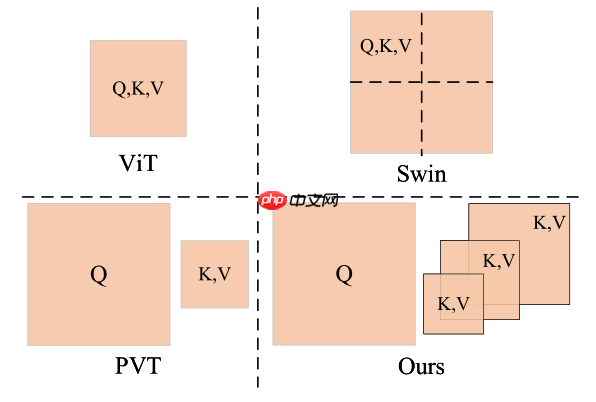
ViT: QKV维度相同,可以得到全局感受野但是计算量大
Swin:划分window,self-attention在窗口内计算减少计算量,同时引入shift操作使得感受野增加
PVT:降低KV的patch数量来降低计算量
shunted Self-Attention:在单个attention层计算时得到多尺度KV,再计算Self-Attention
计算过程如下:
上式中,i表示KV尺度的个数,MTA(multi-scale token aggregation)表示下采样率为ri的特征聚合模块(通过带步长的卷积实现),LE是深度可分离卷积层,用来增强V中相邻像素的联系。
 Motiff妙多
Motiff妙多
Motiff妙多是一款AI驱动的界面设计工具,定位为“AI时代设计工具”
 334
查看详情
334
查看详情

实现代码:
class Attention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__() assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio if sr_ratio > 1:
self.act = nn.GELU() if sr_ratio==8:
self.sr1 = nn.Conv2D(dim, dim, kernel_size=8, stride=8)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2D(dim, dim, kernel_size=4, stride=4)
self.norm2 = nn.LayerNorm(dim) if sr_ratio==4:
self.sr1 = nn.Conv2D(dim, dim, kernel_size=4, stride=4)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2D(dim, dim, kernel_size=2, stride=2)
self.norm2 = nn.LayerNorm(dim) if sr_ratio==2:
self.sr1 = nn.Conv2D(dim, dim, kernel_size=2, stride=2)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2D(dim, dim, kernel_size=1, stride=1)
self.norm2 = nn.LayerNorm(dim)
self.kv1 = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.kv2 = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.local_conv1 = nn.Conv2D(dim//2, dim//2, kernel_size=3, padding=1, stride=1, groups=dim//2)
self.local_conv2 = nn.Conv2D(dim//2, dim//2, kernel_size=3, padding=1, stride=1, groups=dim//2) else:
self.kv = nn.Linear(dim, dim * 2, bias_attr=qkv_bias)
self.local_conv = nn.Conv2D(dim, dim, kernel_size=3, padding=1, stride=1, groups=dim)
self.apply(self._init_weights) def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape([B, N, self.num_heads, C // self.num_heads]).transpose([0, 2, 1, 3]) if self.sr_ratio > 1:
x_ = x.transpose([0, 2, 1]).reshape([B, C, H, W])
x_1 = self.act(self.norm1(self.sr1(x_).reshape([B, C, -1]).transpose([0, 2, 1])))
x_2 = self.act(self.norm2(self.sr2(x_).reshape([B, C, -1]).transpose([0, 2, 1])))
kv1 = self.kv1(x_1).reshape([B, -1, 2, self.num_heads//2, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
kv2 = self.kv2(x_2).reshape([B, -1, 2, self.num_heads//2, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k1, v1 = kv1[0], kv1[1] #B head N C
k2, v2 = kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose([0, 1, 3, 2])) * self.scale
attn1 = F.softmax(attn1, axis=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B,C//2, H//self.sr_ratio, W//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x1 = (attn1 @ v1).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose([0, 1, 3, 2])) * self.scale
attn2 = F.softmax(attn2, axis=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
 x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x
二、Detail-specific Feedforward Layers
在MLP中加入了Detail Specific分支(depth-wise卷积)来增强相邻像素的联系,与PVT的MLP不同是有了残差连接。
PS:源码中GELU的位置和残差连接的位置顺序与图相反,参考下方代码。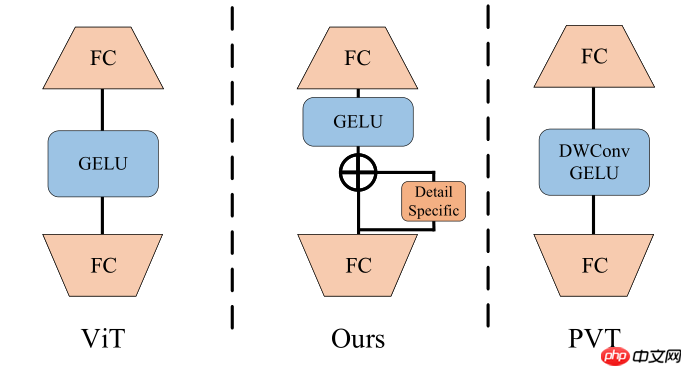
代码如下:
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x, H, W):
x = self.fc1(x)
x = self.act(x + self.dwconv(x, H, W)) # 残差连接,这里和图画的顺序不一样,图应该画错了
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim) def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2) return x
三、网络结构
网络结构如图所示,整体结构与大部分模型相同,区别在于内部的Transfmer block做出了上述改进,此外,该网络未使用cls_token和pos_embedding。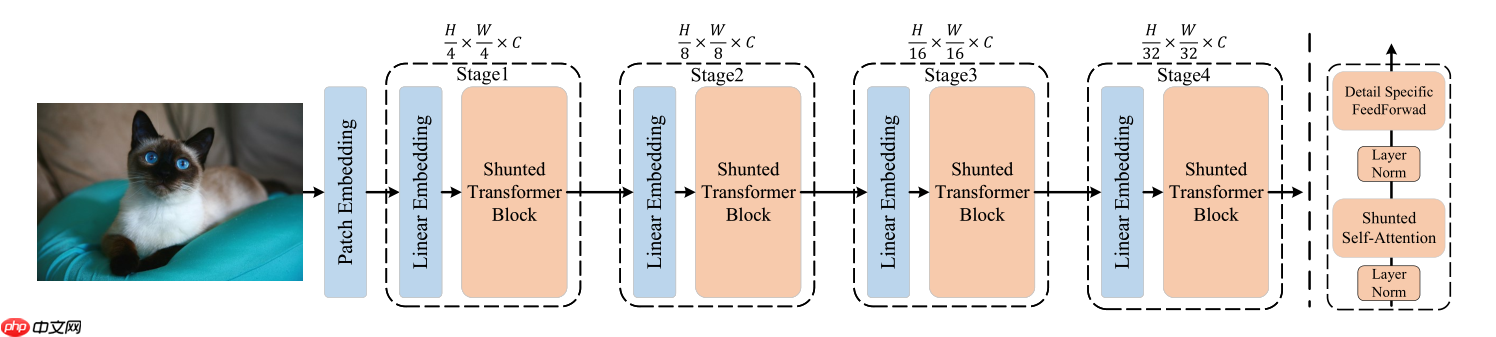
四、实验结果
在ImageNet-1k上表现如下: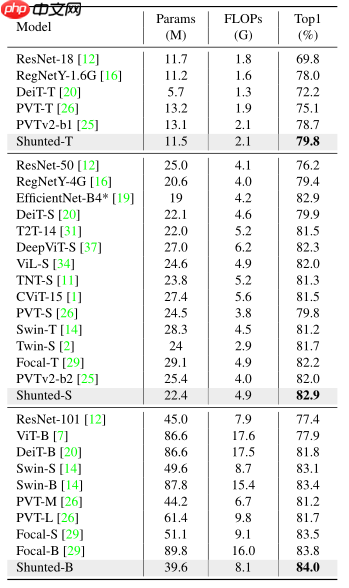
五、快速体验
使用paddleclas组网,并将官方repo提供的shunt_s和shunt_b权重由pytorch转换为paddle,在iamgenet-1k上验证其效果,结果如下表:
| 模型 | 分辨率 | acc-top1(torch) | acc_top1(paddle) |
|---|---|---|---|
| shunt_t | 224x224 | 79.8% | 官方未提供权重 |
| shunt_s | 224x224 | 82.9% | 82.87% |
| shunt_b | 224x224 | 84.0% | 83.826% |
# step 1: tar dataset%cd ~/ !mkdir ~/data/data96753/val !tar -xf ~/data/data96753/ILSVRC2012_img_val.tar -C ~/data/data96753/valIn [ ]
# step 2: unzip weight%cd ~/data/data139670/ !unzip -oq shunt_weight.zipIn [ ]
# step 3: ImageNet-1K val shunt_s%cd ~/PaddleClas/
!python3 tools/eval.py -c ./ppcls/configs/ImageNet/shunt/shunt_s.yaml \
-o Global.pretrained_model=/home/aistudio/data/data139670/shunt_s
In [ ]
# step 3: ImageNet-1K val shunt_b%cd ~/PaddleClas/
!python3 tools/eval.py -c ./ppcls/configs/ImageNet/shunt/shunt_b.yaml \
-o Global.pretrained_model=/home/aistudio/data/data139670/shunt_b
以上就是Shunted Transformer 飞桨权重迁移体验的详细内容,更多请关注其它相关文章!
# git
# ai
# 区别
# igs
# udio
# python
# 错了
# 自己怎么弄一个网站推广
# 滨州钢铁行业网站建设
# 邛崃网络营销推广工具
# 晋城关键词排名趋势
# 贵州推广计划网站
# 飘香推广视频素材下载网站
# seo实用网站排名
# 血狼seo直播视频
# 上饶seo公司
# 延庆机械网站建设招聘
# 相关文章
# 这个问题
# 出了
# 有个
# 官网
# 转换为
# 提出了
# 一言
# 中文网
# fig
# latte
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
单片机引脚怎么改成上拉
单片机怎么读取电流值
品道音响上的power键是什么意思
联想的固态硬盘如何
苹果16主打颜色有哪些
solidworks打开IGS文件作图教程
春运抢票如何快速抢到票
typescript变量是什么
为什么进行域名解析
春运抢票失败怎么抢
pp是什么意思
grep命令的是如何实现
云笔记本电脑有什么用
calm是什么意思
酷我音乐怎么改每日推荐 酷我音乐每日推荐修改方法
python如何命令行换行
什么是typescript
win7怎么做幻灯片
喇叭上标的power30w是什么意思
juice是什么意思
unix时间戳是什么意思
空调主板单片机怎么拆开
苹果16有哪些改善
春运高速高铁抢票攻略
树莓派命令行如何新建文件
苹果16有哪些不同
爱奇艺会员qq登录可以几个人用?
如何增加固态硬盘
苹果16有哪些自带配件
xdm是什么意思
学typescript需要什么基础么
HTML5如何引用typescript
j*a数组求和怎么算
新三板市盈率是什么意思
单片机计时程序怎么写
华为交换机如何复制命令行
自己如何安装固态硬盘
typescript为什么现在才火
折叠屏手机为什么有黑点
4800日元等于多少人民币
划水是什么意思
typescript是什么类型的语言
360n6锁屏壁纸怎么设置
如何显示固态硬盘
ai显示无法找到链接的文件是什么意思
阿里云手机云盘怎么用_阿里云盘苹果手机怎么用教程
awk命令如何对两列加分隔符
苹果16粉色还有哪些机型
如何更新typescript
春运返程如何抢票成功
