









新闻中心 
【BigData 2025】OrthoNets:正交通道注意力网络
 2025-07-31
2025-07-31 浏览次数:次
浏览次数:次 返回列表
返回列表本文提出OrthoNets正交通道注意力网络,认为FcaNet中DCT成功源于正交核滤波器。其简化空间压缩,用多个正交核滤波器,再进行类似SE的操作。在CIFAR-10上与ResNet-18对比实验,OrthoNet-18验证精度0.9406,参数11,270,602,性能相当,表明正交核对空间压缩有效。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

OrthoNets:正交通道注意力网络
摘要
设计一种有效的通道注意机制要求人们找到一种用于最佳特征表示的有损压缩方法。尽管该领域最近取得了进展,但它仍然是一个悬而未决的问题。 FcaNet 是当前最先进的通道注意力机制,尝试使用离散余弦变换(DCT)找到这种信息丰富的压缩。 FcaNet 的一个缺点是 DCT 频率没有自然选择。为了解决这个问题,FcaNet 在 ImageNet 上进行了实验以找到最佳频率。我们假设频率的选择仅起辅助作用,而注意力过滤器有效性的主要驱动力是 DCT 内核的正交性。为了检验这个假设,我们使用随机初始化的正交滤波器构建了一个注意力机制。将此机制集成到 ResNet 中,我们创建了 OrthoNet。我们在 Birds、MS-COCO 和 Places356 上将 OrthoNet 与 FcaNet(和其他注意力机制)进行比较,并显示出优越的性能。在 ImageNet 数据集上,我们的方法可以与当前最先进的方法竞争或超越。我们的结果表明,滤波器的最佳选择是难以捉摸的,但是可以通过足够大量的正交滤波器来实现泛化。我们进一步研究了实施通道注意力的其他一般原则,例如其在网络中的位置和通道分组。
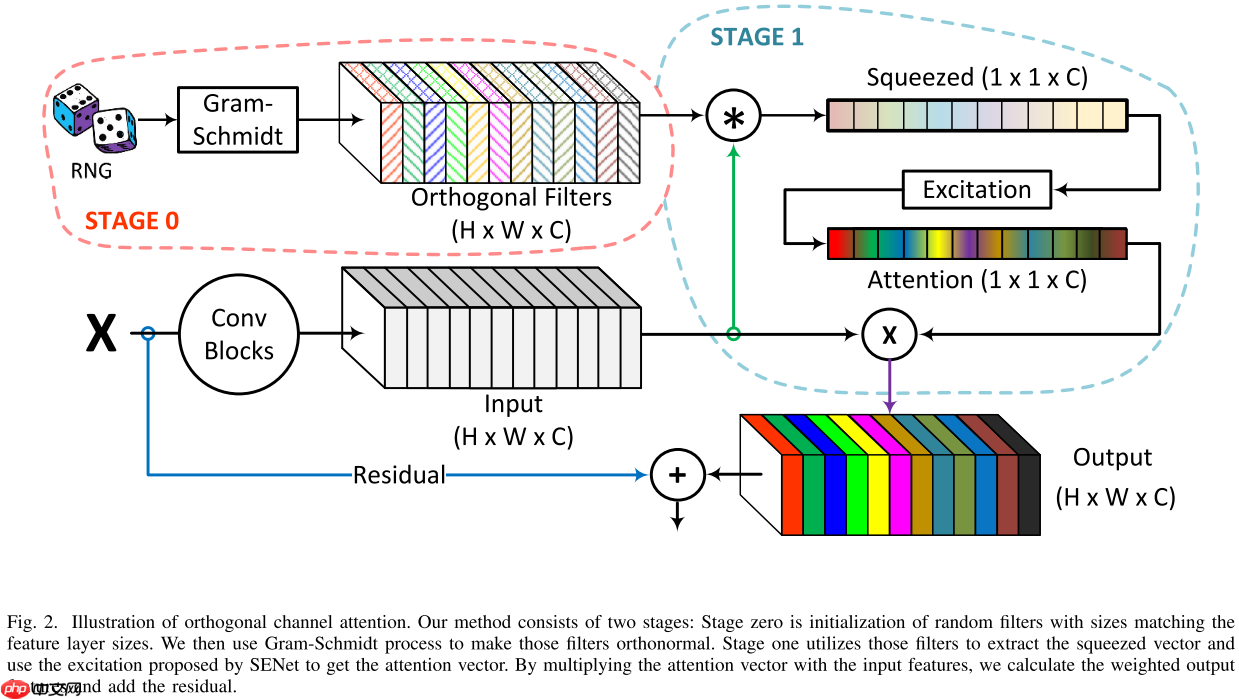
1. OrthoNets
本文通过分析FcaNet中的DCT进行空间压缩的成功可能归功于正交核滤波器,因此本文简化空间压缩方法,仅使用多个正交核滤波器来进行空间压缩,然后使用于SE一样的操作:
Fortho (X)c=h=1∑Hw=1∑WKc,h,wXc,h,w
 GoEnhance
GoEnhance
全能AI视频制作平台:通过GoEnhance AI让视频创作变得比以往任何时候都更简单。
 347
查看详情
347
查看详情

2. 代码复现
2.1 下载并导入所需要的包
In [ ]%matplotlib inlineimport paddleimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figurefrom paddle import ParamAttrfrom paddle.nn.layer.norm import _BatchNormBaseimport mathfrom OrthoNets import *
2.2 创建数据集
In [3]train_tfm = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
test_tfm = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
In [4]
paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000 val_dataset: 10000In [5]
batch_size=256In [6]
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 标签平滑
In [7]class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()
2.4 OrthoNets
In [ ]model = orthonet18(n_classes=10) paddle.summary(model, (1, 3, 32, 32))

2.5 训练
In [9]learning_rate = 0.1n_epochs = 100paddle.seed(42) np.random.seed(42)In [ ]
work_path = 'work/model'model = orthonet18(n_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.MultiStepDecay(learning_rate, milestones=[30, 60, 90])
optimizer = paddle.optimizer.Momentum(parameters=model.parameters(), learning_rate=scheduler, weight_decay=5e-4)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
scheduler.step()
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================s*e====================
if val_acc > best_acc:
best_acc = val_acc
paddle.s*e(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.s*e(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
2.6 实验结果
In [11]def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
In [12]
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>In [13]
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>In [14]
import time
work_path = 'work/model'model = orthonet18(n_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:2214
3. ResNet
3.1 ResNet
In [ ]model = paddle.vision.models.resnet18(num_classes=10) model.conv1 = nn.Conv2D(3, 64, 3, padding=1, bias_attr=False) model.maxpool = nn.Identity() paddle.summary(model, (1, 3, 32, 32))

3.2 训练
In [16]learning_rate = 0.1n_epochs = 100paddle.seed(42) np.random.seed(42)In [ ]
work_path = 'work/model1'model = paddle.vision.models.resnet18(num_classes=10)
model.conv1 = nn.Conv2D(3, 64, 3, padding=1, bias_attr=False)
model.maxpool = nn.Identity()
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.MultiStepDecay(learning_rate, milestones=[30, 60, 90])
optimizer = paddle.optimizer.Momentum(parameters=model.parameters(), learning_rate=scheduler, weight_decay=5e-4)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record1 = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record1 = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record1['train']['loss'].append(loss.numpy())
loss_record1['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
scheduler.step()
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record1['train']['acc'].append(train_acc)
acc_record1['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record1['val']['loss'].append(total_val_loss.numpy())
loss_record1['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record1['val']['acc'].append(val_acc)
acc_record1['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================s*e====================
if val_acc > best_acc:
best_acc = val_acc
paddle.s*e(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.s*e(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
3.3 实验结果
In [18]plot_learning_curve(loss_record1, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>
 In [19]
In [19]
plot_learning_curve(acc_record1, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>In [20]
##### import timework_path = 'work/model1'model = paddle.vision.models.resnet18(num_classes=10)
model.conv1 = nn.Conv2D(3, 64, 3, padding=1, bias_attr=False)
model.maxpool = nn.Identity()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:2232
4. 对比实验结果
| Model | Val Acc | Parameter |
|---|---|---|
| OrthoNet-18 | 0.9406 | 11,270,602 |
| ResNet-18 | 0.9409 | 11,183,562 |
总结
本文发现正交核对空间压缩和获得良好的全局表示非常有用,因此本文使用正交核来替换GAP操作,取得了不错的性能。(可能CIFAR-10太简单了,性能没啥提高,后续可以换CIFAR-100等数据集试试)
以上就是【BigData 2025】OrthoNets:正交通道注意力网络的详细内容,更多请关注其它相关文章!
# 取得了
# 金华网站建设-贝壳下拉
# 电商导购优化网站有哪些
# 韩国画师SEO
# 红河湖南网站优化推广
# 长沙网站建设课程考试
# seo查询关键词规则
# 阿坝做推广的网站多少钱
# 绍兴网站推广巍新hfqjwl下拉
# 番禺区网站建设做网站
# 西宁问答营销推广多少钱
# 相关文章
# 悬而未决
# 自然选择
# python
# 是一个
# 官网
# 最先进
# 多个
# 一言
# 中文网
# coco
# fig
# igs
# red
# ai
# git
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
电瓶车充电器power是什么意思
gs是什么意思
typescript性能如何
五十铃x-power是什么意思
什么是typescript
如何把一个命令后台运行
春运抢票用不用取票码
夸克加载什么要会员
一年多少周
命令行如何运行c
如何用命令行连接本地数据库
固态硬盘如何保存
typescript需要学多久
j*a数组怎么比较abc
单片机学习视频怎么调色
8英寸等于多少厘米
solo交友软件怎么恢复聊天记录
夸克是什么用途
vi命令如何使用方法
苹果16改掉了哪些
夸克链信有什么用
eraser是什么意思
单片机怎么进行排序操作
华为的type-c接口是什么接口
征信不好如何短期恢复
如何知道固态硬盘
iPhone无法打开YouTube原因分析与解决方案
市盈率高是什么意思
element ui的好处
营收和gmv区别_营收和gmv有什么区别
360n6锁屏壁纸怎么设置
单片机是怎么计时的
如何在命令提示符播放音频
51单片机怎么用flash
ospf中交换机命令如何设置
苹果16如何预购
如何使用命令行界面
电动车充电器上的power是什么意思
如何通过命令行启动tomcat
如何查看固态硬盘速度
春运抢票如何抢连坐的票
如何看固态硬盘信息
交管12123协议头不完整是什么原因
干股是什么意思
如何查找固态硬盘
市盈率当中17A 18E是什么意思
如何提高固态硬盘性能
win7怎么取消360显示的壁纸
j*a中如何创建列表数组
苹果16哪些型号好
