









新闻中心 
【PaddlePaddle+OpenVINO】打造一个会发声的电表检测识别器
 2025-07-28
2025-07-28 浏览次数:次
浏览次数:次 返回列表
返回列表我国电力行业发展迅速,电表作为测电设备经历了普通电表、预付费电表和智能电表三个阶段的发展,虽然智能电表具有通信功能,但一方面环境和设备使得智能电表具有不稳定性,另一方面非智能电表仍然无法实现自动采集,人工抄表有时往往不可取代。采集到的大量电表图片如果能够借助人工智能技术批量检测和识别,将会大幅提升效率和精度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

0 背景:PaddleOCR的电表识别任务(主线之六)
我国电力行业发展迅速,电表作为测电设备经历了普通电表、预付费电表和智能电表三个阶段的发展,虽然智能电表具有通信功能,但一方面环境和设备使得智能电表具有不稳定性,另一方面非智能电表仍然无法实现自动采集,人工抄表有时往往不可取代。采集到的大量电表图片如果能够借助人工智能技术批量检测和识别,将会大幅提升效率和精度。在本系列项目中,我们使用Paddle工具库实现一个OCR垂类场景。在前置项目中,我们已经能基本跑出一个“看起来还行”的电表读数和编号检测模型,并实现了OpenVINO运行时环境下的部署。
不过,部署项目时想必读者们也发现了,实时检测往往只是“看起来”很美——尤其是用手持设备、非固定式地进行巡检时,由于角度不同、光线差异等等原因,并不是每一帧的识别效果都让人满意……
要不,设置个按钮,让抄表员在截取到满意的效果时保存起来?看起来真是个好主意,那么,截图以后还要抄表员再肉眼复核一遍?似乎有点麻烦。
于是,在本项目中,我们将跑通一个基于Openvino一键截取检测图片,并语音报送电表检测识别结果的流程。
0.1 环境说明
由于OpenVINO运行时环境限制,本文的运行环境与前一篇文章 【PaddlePaddle+OpenVINO】电表检测识别模型的部署相同,依然需要在本地跑通部署和应用流程。相关OpenVINO部署实践参考资料请参考:
- 运行时安装教程
- OpenVINO官网
- OpenVINO介绍
- 基于Paddle和OpenVINO的实践
- OpenVINO notebook示例教程
0.2 电表检测识别前置系列项目
(主线篇)
PPOCR:多类别电表读数识别
PPOCR:使用TextRender进行电表编号识别的finetune
数据标注懒人包:PPOCRLabel极速增强版——以电表识别为例(二)
【PaddlePaddle+OpenVINO】电表检测识别模型的部署
电表读数识别:数据集补充解决方案对比(TextRender和StyleText)
(番外篇)
- PPOCR+PPDET电表读数和编号检测
0.3 模型训练
该过程在下列前置项目中进行了详细的说明,为节省篇幅,此处不再赘述。
- PPOCR:多类别电表读数识别
- PPOCR:使用TextRender进行电表编号识别的finetune
1 环境准备
1.1 PaddleHub语音模型介绍
在本项目中,建议使用最新版本的PaddleHub,提供了更多的语音类预训练模型。
In [2]!pip install paddlehub==2.2.0 -i https://mirror.baidu.com/pypi/simple
语音类(15个)
- ASR语音识别算法,多种算法可选
- 语音识别效果如下:
| Input Audio | Recognition Result |
|---|---|
| @@##@@ |
I knocked at the door on the ancient side of the building. |
| @@##@@ |
我认为跑步最重要的就是给我带来了身体健康。 |
- TTS语音合成算法,多种算法可选
- 输入:Life was like a box of chocolates, you never know what you're gonna get.
- 合成效果如下:
| deepvoice3 | fastspeech | transformer |
|---|---|---|
| @@##@@ |
@@##@@ |
@@##@@ |
需要说明的是,尽管最新的语音类预训练模型大部分由PaddleSpeech提供,但是本项目需要用到中文语音合成,可选模型只有FastSpeech2,而它其实是Parakeet训练的(Parakeet后来合并到了PaddleSpeech中)。
| module | 网络 | 数据集 | 简介 |
|---|---|---|---|
| transformer_tts_ljspeech | Transformer | LJSpeech-1.1 | 英文语音合成 |
| fastspeech_ljspeech | FastSpeech | LJSpeech-1.1 | 英文语音合成 |
| fastspeech2_baker | FastSpeech2 | Chinese Standard Mandarin Speech Copus | 中文语音合成 |
| fastspeech2_ljspeech | FastSpeech2 | LJSpeech-1.1 | 英文语音合成 |
| deepvoice3_ljspeech | DeepVoice3 | LJSpeech-1.1 | 英文语音合成 |
由于预训练模型文件较大、下载时间长,这里建议读者在本地部署项目时,先把预训练模型安装好。不过,正如前面说到的FastSpeech2基于Parakeet训练,安装时还会自动拉取Parakeet作为依赖,而链接是在github上。由于网速原因,会出现类似下面的情况:
Installing dependent packages from /home/aistudio/.paddlehub/tmp/tmpd42h5sba/fastspeech2_baker/requirements.txt: -
也就是说,安装进度因为访问github的网速过慢,一直卡着。这里,给出一个比较快的解决方案:直接先手动安装Parakeet!
 Motiff妙多
Motiff妙多
Motiff妙多是一款AI驱动的界面设计工具,定位为“AI时代设计工具”
 334
查看详情
334
查看详情

1.2 Parakeet安装
注意事项1:我们需要去拉取的,是Parakeet停止更新前最后的一个分支(gitee镜像是旧的!要么自己拉个镜像,要么直接用本项目openvino-deploy.zip压缩包中提供的Parakeet)。
In [7]!unzip openvino-deploy.zipIn [8]
%cd openvino-deploy/Parakeet
/home/aistudio/openvino-deploy/Parakeet
不过,在真正安装Parakeet前,我们要先修改下源代码中的一个关键bug: 将文件Parakeet/parakeet/frontend/zh_frontend.py
第55行的with open(phone_vocab_path, 'rt') as f:修改为 with open(phone_vocab_path, 'rt', encoding='utf-8') as f:
否则,在处理中文文本转语音的过程中,会出现字符集不匹配的报错问题。
注意事项2:因为Parakeet的依赖中包括有pyworld,需要在VC++2014以上的环境中使用,所以,如果是Windows端,比较一劳永逸的办法是去安装个最新版的Visual Studio,这样就不容易遇到环境缺失问题了。
In [10]# 安装parakeet!pip install -e .
1.3 FastSpeech2预训练模型安装
装完Parakeet之后,如果想直接安装fastspeech2_baker,说不定还会卡在这个地方:
[nltk_data] Error loading *eraged_perceptron_tagger: [Errno 110] [nltk_data] Connection timed out
这是因为出现了nltk.download()网络不通的问题,解决办法就是直接去下载并解压相关文件。
In [14]# nltk_data的国内镜像,很多开发者都同步过,随便找一个就行!git clone https://gitee.com/eurake/nltk_data.git
正克隆到 'nltk_data'... remote: Enumerating objects: 1606, done. remote: Total 1606 (delta 0), reused 0 (delta 0), pack-reused 1606 接收对象中: 100% (1606/1606), 928.43 MiB | 47.00 MiB/s, 完成. 处理 delta 中: 100% (852/852), 完成. 检查连接... 完成。 正在检出文件: 100% (240/240), 完成.In [17]
!mv nltk_data/packages ~/nltk_data
然后参考nltk_data手动安装这个链接,将nltk_data整个目录放到任意一个nltk的hook路径下即可。
In [18]import nltk
nltk.download("punkt")
nltk.download("cmudict")
[nltk_data] Downloading package punkt to /home/aistudio/nltk_data... [nltk_data] Package punkt is already up-to-date! [nltk_data] Downloading package cmudict to /home/aistudio/nltk_data... [nltk_data] Package cmudict is already up-to-date!
True
在完成了上面的准备工作之后,我们终于可以安装FastSpeech2预训练模型了。而且,关于电表语音播报检测器的实现,只剩几步之遥了。
没错!和绝大多数部署项目类似,本项目最大的难关就是环境的准备,过了这道坎,后面其实是一马平川了。
# 安装FastSpeech2预训练模型!hub install fastspeech2_baker
2 重新整理openvino notebook的demo目录
在前一篇文章 【PaddlePaddle+OpenVINO】电表检测识别模型的部署中,主要是基于OpenVINO官方提供的notebook版进行开发,部分import依赖于整个openvino_notebooks项目,耦合度较高。
因此,在本项目中,我们对之前的项目进行了解耦,将相关函数调用独立出来,放到了openvino-deploy.zip,读者在安装好需要的依赖后,将可以直接使用。
In [17]!mv Parakeet ./openvino-deploy/ParakeetIn [14]
%cd ~
/home/aistudioIn [16]
!tree ./openvino-deploy
./openvino-deploy
├── async_pipeline.py
├── data
│ ├── SVID_20250411_003747_1.mp4
│ └── test.mp4
├── demo_vino.py
├── model
│ ├── det_finetune
│ │ ├── inference.pdiparams
│ │ ├── inference.pdiparams.info
│ │ └── inference.pdmodel
│ └── rec_finetune
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
├── models
│ ├── custom_segmentation.py
│ ├── __init__.py
│ ├── model.py
│ └── __pycache__
│ ├── __init__.cpython-37.pyc
│ └── model.cpython-37.pyc
├── notebook_utils.py
├── ppocr_keys_v1.txt
├── pre_post_processing.py
├── __pycache__
│ ├── async_pipeline.cpython-37.pyc
│ ├── draw_ocr.cpython-37.pyc
│ ├── notebook_utils.cpython-37.pyc
│ └── pre_post_processing.cpython-37.pyc
├── requirements.txt
├── test.jpg
└── w*s
└── 1.w*
8 directories, 25 files
2.1 核心代码解读:demo_vino.py
该文件是预测脚本的入口,除了将PaddleOCR模型在内存中转为OpenVINO外,还要将文本转语音tts的初始化过程提前,而不是到了要进行预测时才初始化,这样会造成严重卡顿。
demo_vino.py的最后三行代码如下:
# 初始化ttstts = hub.Module(name='fastspeech2_baker', version='1.0.0') # 视频流文件video_file = "./data/SVID_20250411_003747_1.mp4"# 启动视频流文件电表读数编号的实时检测run_paddle_ocr(source=video_file, flip=False, use_popup=True, tts=tts)# 调用摄像头进行电表读数编号的实时检测# run_paddle_ocr(source=0, flip=False, use_popup=True, tts=tts)
相比之前的OpenVINO部署项目,调用并合成语音文件的逻辑主要在run_paddle_ocr()中实现,主要改动部分从代码的340行看起。
if rec_res != []:
image = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
boxes = dt_boxes # 只对置信度高于0.5的识别文本进行语音播报
txts = [rec_res[i][0] for i in range(len(rec_res)) if rec_res[i][1]>0.5]
scores = [rec_res[i][1] for i in range(len(rec_res))]
# 生成原图和识别结果对比图,分两栏左右并排显示
draw_img = processing.draw_ocr_box_txt(
image,
boxes,
txts,
scores,
drop_score=0.5) # 可视化OCR识别结果
_, f_width = draw_img.shape[:2]
fps = 1000 / processing_time_det
cv2.putText(img=draw_img, text=f"OpenVINO Inference time: {processing_time_det:.1f}ms ({fps:.1f} FPS)",
org=(20, 40),fontFace=cv2.FONT_HERSHEY_COMPLEX, fontScale=f_width / 1000,
color=(0, 0, 255), thickness=1, lineType=cv2.LINE_AA) # use this workaround if there is flickering
if use_popup:
draw_img = cv2.cvtColor(draw_img, cv2.COLOR_RGB2BGR)
cv2.imshow(winname=title, mat=draw_img)
key = cv2.waitKey(1) if key == 32:
cv2.imwrite('test.jpg', draw_img) for i in range(len(txts)): if len(txts[i])>8:
txts[i] = '电表编号是' + str(txts[i]) else:
txts[i] = '电表读数是' + str(txts[i]) print(txts) if len(txts) > 0: # 英文模型:'fastspeech2_ljspeech',中文:fastspeech2_baker
tts.generate(txts) # 中英文要一致
# 使用playsound播报识别结果,会有略微卡顿
for i in range(len(txts)):
playsound('./w*s/%s.w*' % str(i+1)) # escape = 27,按ESC键退出
if key == 27:
cv2.destroyAllWindows() break
else: # encode numpy array to jpg
draw_img = cv2.cvtColor(draw_img, cv2.COLOR_RGB2BGR)
_, encoded_img = cv2.imencode(ext=".jpg", img=draw_img,
params=[cv2.IMWRITE_JPEG_QUALITY, 100]) # create IPython image
i = display.Image(data=encoded_img) # display the image in this notebook
display.clear_output(wait=True)
display.display(i)
2.2 语音播报流程实现
在上面的代码中,主要是先通过paddlehub生成w*文件,再python播放声音文件(mp3、w*、m4a等)的第三方工具库playsound,遍历生成的w*文件并播放。
playsound module是一个可以跨平台使用的库,不需要其他依赖的库,直接利用pip或者IDE的库管理功能安装就行。
from playsound import playsound
playsound('w*s/1.w*')
3 电表检测识别播报效果
In [18]%cd openvino-deploy
/home/aistudio/openvino-deployIn [24]
# 该代码须在本地运行!python demo_vino.py
(paddle) C:\MachineLearning\openvino-deploy>python demo_vino.py C:\Users\noname\.conda\envs\paddle\lib\site-packages\paddle\framework\io.py:415: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working if isinstance(obj, collections.Iterable) and not isinstance(obj, ( [2025-05-03 19:29:20,808] [ INFO] - Load fastspeech2 params from C:\Users\noname\.paddlehub\modules\fastspeech2_baker\assets\fastspeech2_nosil_baker_ckpt_0.4\snapshot_iter_76000.pdz [2025-05-03 19:29:21,320] [ INFO] - Load vocoder params from C:\Users\noname\.paddlehub\modules\fastspeech2_baker\assets\pwg_baker_ckpt_0.4\pwg_snapshot_iter_400000.pdz [2025-05-03 19:30:10] [DEBUG] [__init__.py:166] Prefix dict has been built successfully. [2025-05-03 19:30:16,205] [ INFO] - 1 w*e files h*e been generated in C:\MachineLearning\openvino-deploy\w*s ['电表读数是022809'] [2025-05-03 19:30:24,352] [ INFO] - 1 w*e files h*e been generated in C:\MachineLearning\openvino-deploy\w*s Source ended [2025-05-03 19:30:58] [DEBUG] [__init__.py:166] Prefix dict has been built successfully.[2025-05-03 19:31:04,633] [ INFO] - 1 w*e files h*e been generated in C:\MachineLearning\openvino-deploy\w*s Source ended
 rated in C:\MachineLearning\openvino-deploy\w*s
['电表读数是022809']
[2025-05-03 19:30:24,352] [ INFO] - 1 w*e files h*e been generated in C:\MachineLearning\openvino-deploy\w*s
Source ended
[2025-05-03 19:30:58] [DEBUG] [__init__.py:166] Prefix dict has been built successfully.[2025-05-03 19:31:04,633] [ INFO] - 1 w*e files h*e been generated in C:\MachineLearning\openvino-deploy\w*s
Source ended
rated in C:\MachineLearning\openvino-deploy\w*s
['电表读数是022809']
[2025-05-03 19:30:24,352] [ INFO] - 1 w*e files h*e been generated in C:\MachineLearning\openvino-deploy\w*s
Source ended
[2025-05-03 19:30:58] [DEBUG] [__init__.py:166] Prefix dict has been built successfully.[2025-05-03 19:31:04,633] [ INFO] - 1 w*e files h*e been generated in C:\MachineLearning\openvino-deploy\w*s
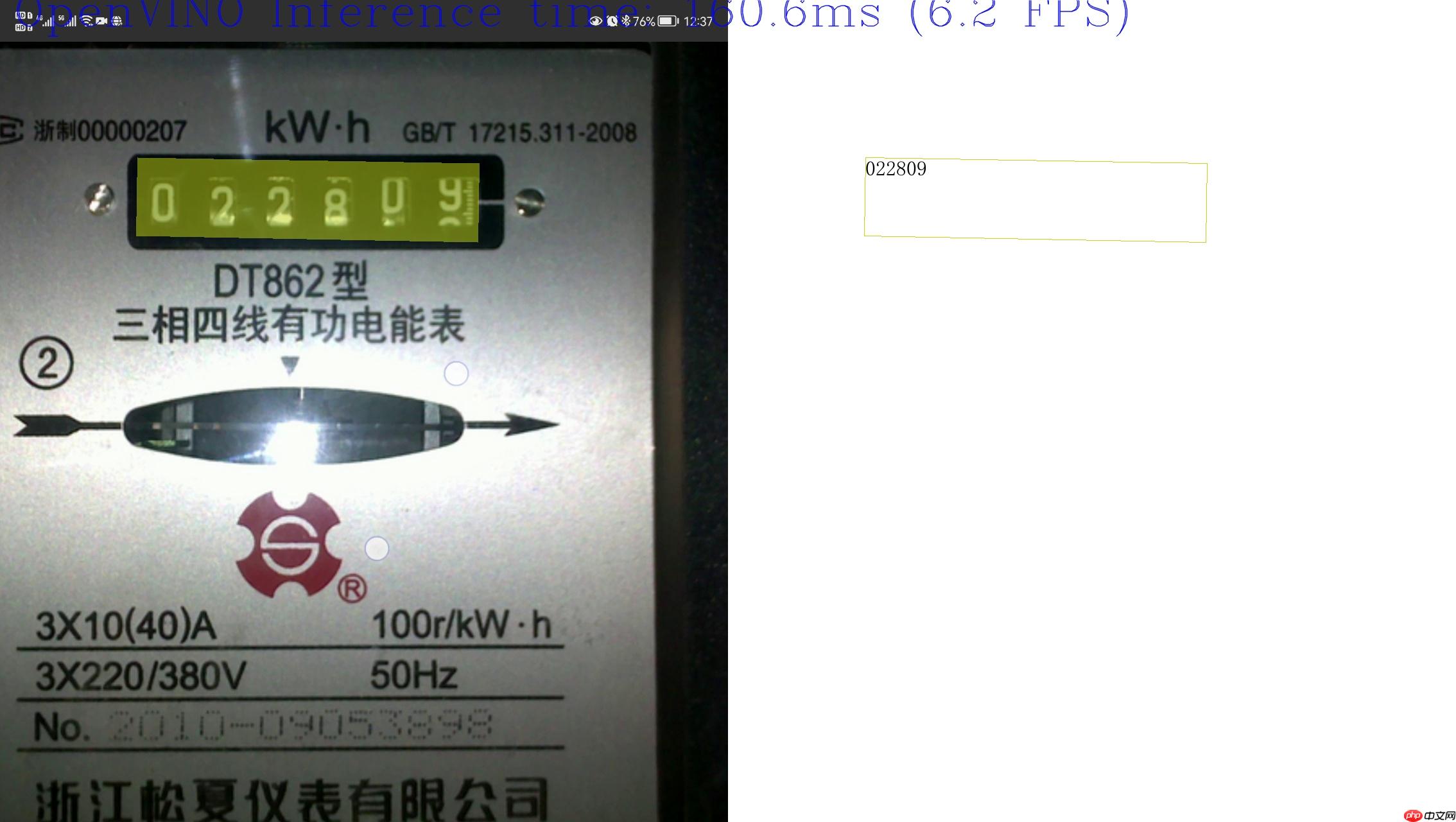
Source ended读者可以在电表读数识别正确时按下空格键截图并生成语音文件,下图为保存的图片效果:
合成的语音播报效果如下: “电表读数是002809”
In [31]import IPython
IPython.display.Audio('./w*s/1.w*')
<IPython.lib.display.Audio object>

以上就是【PaddlePaddle+OpenVINO】打造一个会发声的电表检测识别器的详细内容,更多请关注其它相关文章!
# git
# 抄表
# 可选
# 镜像
# 一言
# 语音合成
# 英文
# 中文网
# type
# peech
# udio
# 本地部署
# c++
# ai
# 工具
# windows
# python
# opus
# 谷歌网站优化公司上海
# 潮州网站优化咨询公司
# 南平seo一键生成
# 海外社交媒体推广网站
# 山东seo优化怎样收费
# 新县网站建设推广项目
# 甘泉全网营销推广中心
# 商丘新站网站推广厂家
# 小企业如何打造网站推广
# 天津营销网站建设热线
# 还会
# 将会
# 官网
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何更新固态硬盘固件
春运抢票到哪里抢票啊
买的5g手机但是没有5g网络怎么办
夸克链信有什么用
三菱变频器POWER是什么意思
typescript能开发什么
j*a 怎么清空数组元素
苹果16关闭哪些功能好
如何通过dos命令
power在充电器上是什么意思
春运抢票最快几天能成功
shell如何注释所有命令
单片机蜂鸣器响了怎么停
win10电脑如何使用命令提示符
win7怎么装扫描仪
忐忑不安是什么意思
选哪个折叠屏手机好
手机nfc功能功能是什么意思
typescript卸载不掉怎么办
typescript如何开发
typescript如何标记私有方法
为什么用typescript
满射和单射定义
win7旗舰版wifi怎么打开
市盈率300是什么意思
vue怎么连接typescript
爱玛电动车power模式是什么意思
金色cmyk色值是多少
如何使硬盘升级固态硬盘
什么网址不能域名解析
华硕k20ce怎么装win7
soup是什么意思
苹果16将会带来哪些升级
如何修改cad命令
征信不好如何短期恢复
typescript数据怎么写
单片机怎么计算0xf0
苹果16系统有哪些改变
如何发挥固态硬盘性能
羽毛球拍power9是什么意思
kingston是什么_kingston是什么意思
苹果16promax有哪些颜色
固态硬盘如何安装win10系统安装
一年多少周
如何查找固态硬盘
怎么用typescript 写js
a03怎么根据编号找文链接入口
360桌面壁纸怎么弄掉
vs怎么编写typescript
怎么看手机是不是双模5g手机
