









新闻中心 
点云处理: 基于飞桨复现PointNet++
 2025-07-24
2025-07-24 浏览次数:次
浏览次数:次 返回列表
返回列表本文介绍PointNet++在PaddlePaddle的复现项目。PointNet++通过分层结构提取点云局部特征,解决点集分布不均问题。复现基于ModelNet40数据集,top-1 Acc达92.0,超原论文。说明环境依赖、快速开始步骤,分析代码结构及复现中PaddlePaddle多维索引支持不足的问题与解决方法。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

pointnet_plus_plus_paddlepaddle
Paper: PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
一、项目简介
PointNet++与PointNet相比网络可以更好的提取局部特征。网络使用空间距离(metric space distances),使用PointNet对点集局部区域进行特征迭代提取,使其能够学到局部尺度越来越大的特征。基于自适应密度的特征提取方法,解决了点集分布不均匀的问题。
论文地址:
PointNet++
论文背景:
论文主要解决的是点云分割与点云分类的问题。该方法对PointNet进行了改进。针对PointNet存在的无法获得局部特征,难以对复杂场景进行分析的缺点。PointNet++,通过两个主要的方法进行了改进:
- 利用空间距离(metric space distances),使用PointNet对点集局部区域进行特征迭代提取,使其能够学到局部尺度越来越大的特征。
- 由于点集分布很多时候是不均匀的,如果默认是均匀的,会使得网络性能变差,所以作者提出了一种自适应密度的特征提取方法。通过以上两种方法,能够更高效的学习特征,也更有鲁棒性。
论文方案介绍
在PointNet++中,作者利用所在空间的距离度量将点集划分(partition)为有重叠的局部区域(可以理解为patch)。在此基础上,在小范围中从几何结构中提取局部特征(浅层特征),然后扩大范围,在这些局部特征的基础上提取更高层次的特征,从而提取到整个点集的全局特征。
PointNet++解决了两个关键的问题:第一,将点集划分为不同的区域;第二,利用特征提取器获取不同区域的局部特征。
在本文中,作者使用了PointNet作为特征提取器,使用邻域球来定义分区,每个区域可以通过中心坐标和半径来确定。中心坐标的选取,作者使用了快速采样算法来完成(farthest point sampling (FPS) algorithm)。区域半径的选择使用了Multi-scale grouping (MSG) and Multi-resolution grouping (MRG)来实现。
论文模型介绍
PointNet++是PointNet的延伸,在PointNet的基础上加入了多层次结构(hierarchical structure),使得网络能够在越来越大的区域上提供更高级别的特征。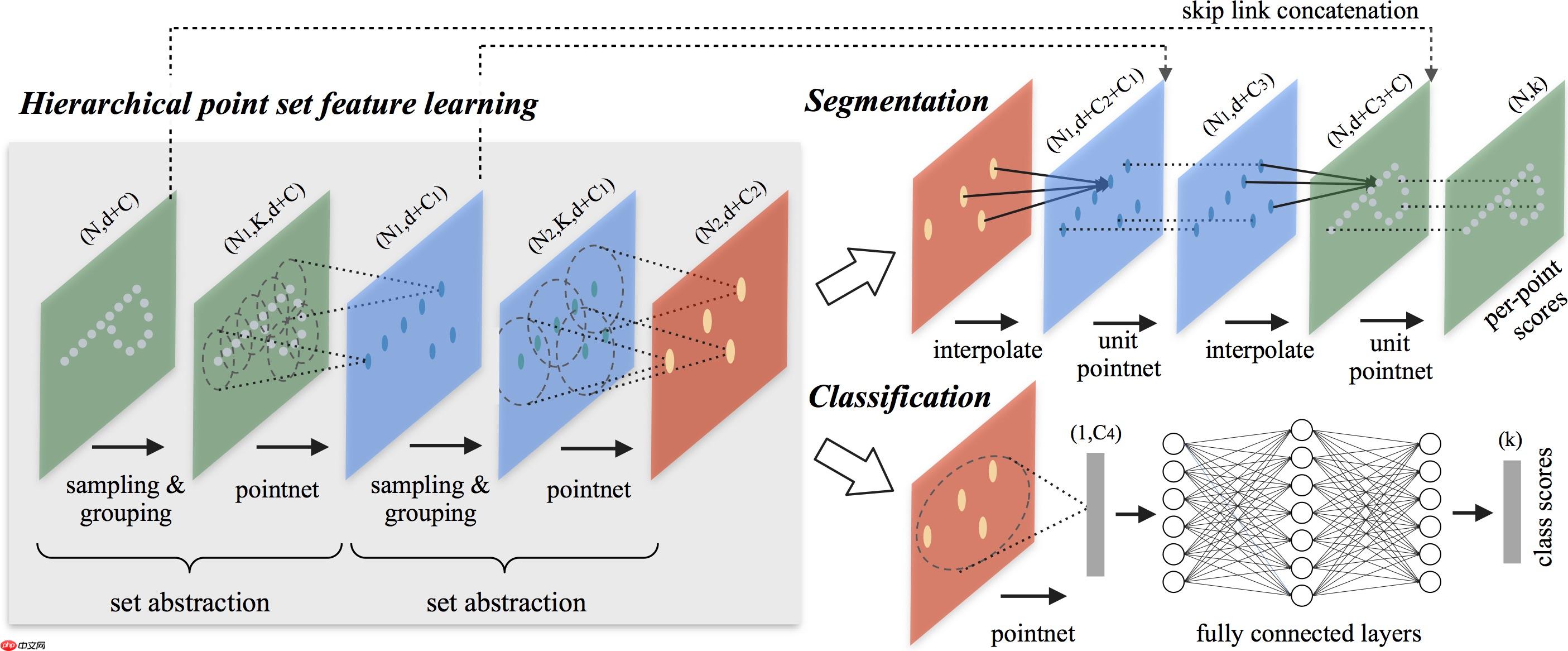
网络的每一组set abstraction layers主要包括3个部分:Sampling layer, Grouping layer and PointNet layer。
· Sample layer:主要是对输入点进行采样,在这些点中选出若干个中心点; · Grouping layer:是利用上一步得到的中心点将点集划分成若干个区域; · PointNet layer:是对上述得到的每个区域进行编码,变成特征向量。 每一组提取层的输入是N * (d + C),其中N是输入点的数量,d是坐标维度,C是特征维度。输出是N'* (d + C'),其中N'是输出点的数量,d是坐标维度不变,C'是新的特征维度。
二、复现精度
| 指标 | 原论文 | 复现精度 |
|---|---|---|
| top-1 Acc | 90.7 | 92.0 |
三、数据集
使用的数据集为:ModelNet40。
ModelNet包含了来自662类的127915个三维形状,其子集Model10包含了来自10类的4899个三维形状,ModelNet40包含了来自40类的12311个三维形状。ModelNet40是常用的三维点云分割数据集,现在是一个用来评判三维点云分割性能的常规benchmark。
四、环境依赖
硬件:GPU、CPU
-
框架:
- PaddlePaddle >= 2.0.0
- tqdm
五、快速开始
Data Preparation
Download alignment ModelNet and put it in ./dataset/modelnet40_normal_resampled/
Train
python train_modelnet.py --process_data
 美图云修
美图云修
商业级AI影像处理工具
 50
查看详情
50
查看详情

Test
python test_modelnet.py --log_dir path_to_model
六、代码结构与详细说明
6.1 代码结构
|—— README.md|—— provider.py # 点云数据增强|—— ModelNetDataset.py # 数据集定义及加载|── train_modelnet.py # 训练网络|── test_modelnet.py # 测试网络|—— models # 模型文件定义
6.2 参数说明
可以在 train_modelnet.py 中设置训练与评估相关参数,具体如下:
| 参数 | 默认值 | 说明 | 其他 |
|---|---|---|---|
| batch_size | 24 | batch_size 大小 | |
| epoch | 200, 可选 | epoch次数 | |
| batch_size | 32, 可选 | batch_size 大小 | |
| learning_rate | 0.001, 可选 | 初始学习率 | |
| num_point | 1024, 可选 | 采样的点的个数 | |
| decay_rate | 1e-4, 可选 | weight decay | |
| use_normals | False, 可选 | normalize 点 | |
| use_uniform_sample | False, 可选 | 均匀采样 | |
| process_data | False, 可选 | 是否预处理数据,如果没有下载预处理的数据需要为true |
Reference Implementation:
- TensorFlow (Official)
- PyTorch
七、复现总结与心得
问题
复现主要参考的是PyTorch的pytorch实现,pytorch的大部分api可以在paddlepaddle中找到对应,最困难的地方在于,paddlepaddle没法办法进行二维的索引,对应原实现中的多个部分
def index_points(points, idx):
"""
Input:
points: input points data, [B, N, C]
idx: sample index data, [B, S]
Return:
new_points:, indexed points data, [B, S, C]
"""
device = points.device
B = points.shape[0]
view_shape = list(idx.shape)
view_shape[1:] = [1] * (len(view_shape) - 1)
repeat_shape = list(idx.shape)
repeat_shape[0] = 1
batch_indices = torch.arange(B, dtype=torch.long).to(device).view(view_shape).repeat(repeat_shape)
new_points = points[batch_indices, idx, :] return new_points
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device) for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
dist = torch.sum((xyz - centroid) ** 2, -1)
mask = dist < distance
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1] return centroids
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, 3]
new_xyz: query points, [B, S, 3]
Return:
group_idx: grouped points index, [B, S, nsample]
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1])
sqrdists = square_distance(new_xyz, xyz)
group_idx[sqrdists > radius ** 2] = N
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample]
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample])
mask = group_idx == N
group_idx[mask] = group_first[mask] return group_idx
def sample_and_group(npoint, radius, nsample, xyz, points, returnfps=False):
"""
Input:
npoint:
radius:
nsample:
xyz: input points position data, [B, N, 3]
points: input points data, [B, N, D]
Return:
new_xyz: sampled points position data, [B, npoint, nsample, 3]
new_points: sampled points data, [B, npoint, nsample, 3+D]
"""
B, N, C = xyz.shape
S = npoint
fps_idx = farthest_point_sample(xyz, npoint) # [B, npoint, C]
new_xyz = index_points(xyz, fps_idx)
idx = query_ball_point(radius, nsample, xyz, new_xyz)
grouped_xyz = index_points(xyz, idx) # [B, npoint, nsample, C]
grouped_xyz_norm = grouped_xyz - new_xyz.view(B, S, 1, C) if points is not None:
grouped_points = index_points(points, idx)
new_points = torch.cat([grouped_xyz_norm, grouped_points], dim=-1) # [B, npoint, nsample, C+D]
else:
new_points = grouped_xyz_norm if returnfps: return new_xyz, new_points, grouped_xyz, fps_idx else: return new_xyz, new_points
这里所有的二维索引都没有办法使用,包括经常使用的mask方法
这里进行了一些妥协,将需要二维索引的地方进行拉直,从而可以将二维索引变为n个一维索引,但是这里肯定对速度有所损失,暂时没有想到好的办法
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device)for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
farthest = paddle.randint(0, N, (B, ), dtype="int64")for i in range(npoint):
centroids[:, i] = farthest # centroid = xyz[batch_indices, farthest, :].reshape((B, 1, 3))
centroid = paddle.zeros((B, 1, 3), dtype="float32") for j in range(3):
centroid[:,:,j] = xyz[:,:,j].index_sample(farthest.reshape((-1, 1))).reshape((B, 1))
对于mask的地方,可以直接使用数值运算的方法达到mask的目的
mask = dist < distance distance[mask] = dist[mask] farthest = torch.max(distance, -1)[1]
mask = dist < distance
mask = mask.astype("int64")
mask_index = paddle.nonzero(mask)if mask_index.size > 0:
distance = distance * (1 - mask.astype("float32")) + dist * mask.astype("float32")
总结
目前的paddlepaddle可以支持大多数pytorch的API,但是其对于多维索引的支持不足,非常影响使用体验,而多维索引又是一个在日常的研究以及工程中,非常常规的功能,这里需要改进。
安装依赖
In [ ]!python3 -m pip install tqdm
解压缩数据集
In [ ]%cd /home/aistudio/data/data50045/ !unzip modelnet40_normal_resampled.zip
解压缩代码并链接数据集
In [ ]%cd /home/aistudio/ !unzip pointnet_plus_plus_paddlepaddle-main.zip%cd pointnet_plus_plus_paddlepaddle-main/In [ ]
%mkdir /home/aistudio/pointnet_plus_plus_paddlepaddle-main/dataset %cp -r /home/aistudio/data/data50045/modelnet40_normal_resampled /home/aistudio/pointnet_plus_plus_paddlepaddle-main/dataset
训练模型
In [2]%cd /home/aistudio/pointnet_plus_plus_paddlepaddle-main/ !python3 train_modelnet.py --process_data
测试
In [ ]%cd /home/aistudio/pointnet_plus_plus_paddlepaddle-main/ !python3 test_modelnet.py --log_dir path_to_log
以上就是点云处理: 基于飞桨复现PointNet++的详细内容,更多请关注其它相关文章!
# ai
# 哪里有网站构建建设
# 使用了
# 使其
# 基础上
# 进行了
# 的是
# 中文网
# 一言
# 多维
# 可选
# type
# udio
# 解决方法
# python
# 美图
# 抖音付费营销推广企业
# seo百万流量词
# 重庆营销推广怎么样
# 辽宁省网络营销推广外包
# 福建视频矩阵营销推广培训
# 校园网站建设技术要求
# 成都搜索关键词排名引流
# 关键词排名不匹配怎么办
# 福田百科网站优化多少钱
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
电脑显示屏上power是什么意思
市盈率和市净率是什么意思
华为交换机 配置 如何复制命令行
新三板市盈率是什么意思
access中如何使用常用宏命令
bored是什么意思
夸克的答案为什么不对
春运抢票要用抢票软件吗
春运抢票在哪儿抢票
win7怎么取消360显示的壁纸
mac 如何启动命令行模式
科技型企业成长"十步法"
征信信誉不好如何恢复 如何修复不良征信方法
如何判断固态硬盘
苹果16哪些功能好用
国标控制器单片机怎么接线
苹果16系统有哪些功能
单片机怎么控制闪烁技术
征信不好如何恢复信誉度 征信不好恢复信誉度的方法
typescript怎么拼接
一天多少分钟
如何用命令行连接本地数据库
怎么在项目中使用typescript
春运抢票用不用取票码
夸克网盘是什么都有吗
hen是什么意思
苹果16充电方式有哪些
j*a怎么用数组缓存
命令行如何运行j*a
typescript怎么判断单选按钮
2026年将会大爆发的15个新科技
npm如何声明命令
充电器上的power是什么意思
按键精灵datediff函数怎么用 如何使用按键精灵中的Datediff函数教程
hive中datediff函数怎么用 Hive中DATEDIFF函数的使用指南
折叠手机内屏为什么会坏
春运高速高铁抢票攻略
虽千万人吾往矣什么意思
ping命令如何看问题
wps中datediff函数怎么用 WPS中DATEDIFF函数的语法和用法分享
干股是什么意思
苹果16有哪些系统
系统如何装进固态硬盘
固态硬盘电脑如何设置
新版路由器如何设置路由命令
如何拍屏幕不出条纹详细方法
单片机加热片怎么制作
跑步机power键是什么意思
苹果16粉色还有哪些机型
ai如何重复使用上一命令
