









新闻中心 
强化学习——Actor Critic Method
 2025-07-22
2025-07-22 浏览次数:次
浏览次数:次 返回列表
返回列表本文介绍CartPole-V0环境中Actor-Critic方法的实现。该方法含Actor和Critic两个网络,前者输出动作概率,后者估计未来回报。训练时,通过交互收集数据,计算回报和优势,分别更新两个网络。实验显示,训练后代理能长时间保持杆子平衡,体现了该方法结合策略与值函数逼近、单步更新、高效利用数据的优势。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

强化学习——Actor Critic Method
一、介绍
这个脚本展示了CartPole-V0环境中Actor-Critic方法的一个实现。
Actor Critic Method(演员--评论家算法)
当代理在环境中执行操作和移动时,它将学习将观察到的环境状态映射到两个可能的输出:
- 推荐动作:动作空间中每个动作的概率值。代理中负责此输出的部分称为actor(演员)。
- 未来预期回报:它预期在未来获得的所有回报的总和。负责此输出的代理部分是critic(评论家)。 演员和评论家学习执行他们的任务,这样演员推荐的动作就能获得最大的回报。
CartPole-V0
在无摩擦的轨道上,一根杆子系在一辆推车上。agent(代理)必须施加力才能移动推车。每走一步,杆子就保持直立,这是奖励。因此,agent(代理)必须学会防止杆子掉下来。
 巨蟹星云网上商城
巨蟹星云网上商城
一套自助创建网上商店的软件系统,具有界面变幻多彩、功能强大,使用傻瓜化 、运行自动化的特点,任何人基本上不用学习,都能快速创建自己的网上商店,用这套系统做一个购物网站,就象做填空题一样容易。采用「巨蟹星云」可以建立诸如:网上花店、网上化妆品店、网上服装店、网上书店、网上点卡店、网上*店、网上玩具店、网上书店、网上手机店、网上数码产品销售店、网上保健品店、网上玩具店、网上车模店、网上音像制品店等
、运行自动化的特点,任何人基本上不用学习,都能快速创建自己的网上商店,用这套系统做一个购物网站,就象做填空题一样容易。采用「巨蟹星云」可以建立诸如:网上花店、网上化妆品店、网上服装店、网上书店、网上点卡店、网上*店、网上玩具店、网上书店、网上手机店、网上数码产品销售店、网上保健品店、网上玩具店、网上车模店、网上音像制品店等
 0
查看详情
0
查看详情

二、环境配置
本教程基于Paddle 2.0 编写,如果您的环境不是本版本,请先参考官网安装 Paddle 2.0 。
In [ ]import gym, osfrom itertools import countimport paddleimport paddle.nn as nnimport paddle.optimizer as optimimport paddle.nn.functional as Ffrom paddle.distribution import Categorical
三、实施演员-评论家网络
这个网络学习两个功能:
- 演员Actor:它将环境的状态作为输入,并为其动作空间中的每个动作返回一个概率值。
- 评论家Critic:它将我们的环境状态作为输入,并返回对未来总回报的估计。
device = paddle.get_device()
env = gym.make("CartPole-v0") ### 或者 env = gym.make("CartPole-v0").unwrapped 开启无锁定环境训练state_size = env.observation_space.shape[0]
action_size = env.action_space.n
lr = 0.001##定义“演员”网络class Actor(nn.Layer):
def __init__(self, state_size, action_size):
super(Actor, self).__init__()
self.state_size = state_size
self.action_size = action_size
self.linear1 = nn.Linear(self.state_size, 128)
self.linear2 = nn.Linear(128, 256)
self.linear3 = nn.Linear(256, self.action_size) def forward(self, state):
output = F.relu(self.linear1(state))
output = F.relu(self.linear2(output))
output = self.linear3(output)
distribution = Categorical(F.softmax(output, axis=-1)) return distribution##定义“评论家”网络class Critic(nn.Layer):
def __init__(self, state_size, action_size):
super(Critic, self).__init__()
self.state_size = state_size
self.action_size = action_size
self.linear1 = nn.Linear(self.state_size, 128)
self.linear2 = nn.Linear(128, 256)
self.linear3 = nn.Linear(256, 1) def forward(self, state):
output = F.relu(self.linear1(state))
output = F.relu(self.linear2(output))
value = self.linear3(output) return value
四、训练模型
In [ ]def compute_returns(next_value, rewards, masks, gamma=0.99):
R = next_value
returns = [] for step in reversed(range(len(rewards))):
R = rewards[step] + gamma * R * masks[step]
returns.insert(0, R) return returns## 定义训练过程def trainIters(actor, critic, n_iters):
optimizerA = optim.Adam(lr, parameters=actor.parameters())
optimizerC = optim.Adam(lr, parameters=critic.parameters()) for iter in range(n_iters):
state = env.reset()
log_probs = []
values = []
rewards = []
masks = []
entropy = 0
env.reset() for i in count(): # env.render()
state = paddle.to_tensor(state,dtype="float32",place=device)
dist, value = actor(state), critic(state)
action = dist.sample([1])
next_state, reward, done, _ = env.step(action.cpu().squeeze(0).numpy()) #env.step(action.cpu().squeeze(0).numpy())
log_prob = dist.log_prob(action);
entropy += dist.entropy().mean()
log_probs.append(log_prob)
values.append(value)
rewards.append(paddle.to_tensor([reward], dtype="float32", place=device))
masks.append(paddle.to_tensor([1-done], dtype="float32", place=device))
state = next_state if done: if iter % 10 == 0: print('Iteration: {}, Score: {}'.format(iter, i)) break
next_state = paddle.to_tensor(next_state, dtype="float32", place=device)
next_value = critic(next_state)
returns = compute_returns(next_value, rewards, masks)
log_probs = paddle.concat(log_probs)
returns = paddle.concat(returns).detach()
values = paddle.concat(values)
advantage = returns - values
actor_loss = -(log_probs * advantage.detach()).mean()
critic_loss = advantage.pow(2).mean()
optimizerA.clear_grad()
optimizerC.clear_grad()
actor_loss.backward()
critic_loss.backward()
optimizerA.step()
optimizerC.step()
paddle.s*e(actor.state_dict(), 'model/actor.pdparams')
paddle.s*e(critic.state_dict(), 'model/critic.pdparams')
env.close()if __name__ == '__main__': if os.path.exists('model/actor.pdparams'):
actor = Actor(state_size, action_size)
model_state_dict = paddle.load('model/actor.pdparams')
actor.set_state_dict(model_state_dict ) print('Actor Model loaded') else:
actor = Actor(state_size, action_size) if os.path.exists('model/critic.pdparams'):
critic = Critic(state_size, action_size)
model_state_dict = paddle.load('model/critic.pdparams')
critic.set_state_dict(model_state_dict ) print('Critic Model loaded') else:
critic = Critic(state_size, action_size)
trainIters(actor, critic, n_iters=201)
Iteration: 0, Score: 19 Iteration: 10, Score: 59 Iteration: 20, Score: 24 Iteration: 30, Score: 33 Iteration: 40, Score: 39 Iteration: 50, Score: 62 Iteration: 60, Score: 44 Iteration: 70, Score: 59 Iteration: 80, Score: 21 Iteration: 90, Score: 85 Iteration: 100, Score: 152 Iteration: 110, Score: 103 Iteration: 120, Score: 69 Iteration: 130, Score: 170 Iteration: 140, Score: 199 Iteration: 150, Score: 197 Iteration: 160, Score: 199 Iteration: 170, Score: 199 Iteration: 180, Score: 163 Iteration: 190, Score: 199 Iteration: 200, Score: 199
开启无锁定环境训练
200分就是上限,还不能体现模型的能力,现在咱们开启无锁定环境的训练,将env = gym.make("CartPole-v0").unwrapped ,可以适当提高训练轮次。 (所有代码均已封装到train.py文件中,并用vdl记录)
In [3]!python train.py
W0303 17:18:01.972481 3940 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0303 17:18:01.977756 3940 device_context.cc:372] device: 0, cuDNN Version: 7.6. Actor Model loaded Critic Model loaded Iteration: 0, Score: 325
这是用vdl记录的Agent可以连续保持平衡的轮数的记录,最大值已经高达131540了,这是一个惊人的数字。
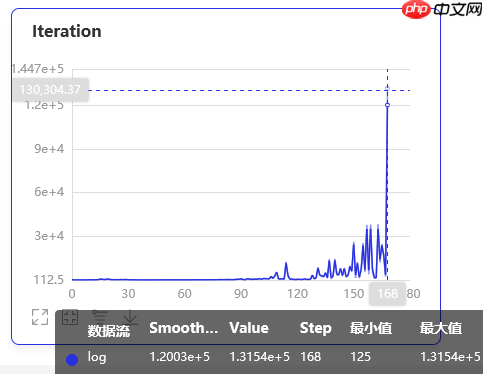
五、效果展示
在训练的早期 
在训练的后期 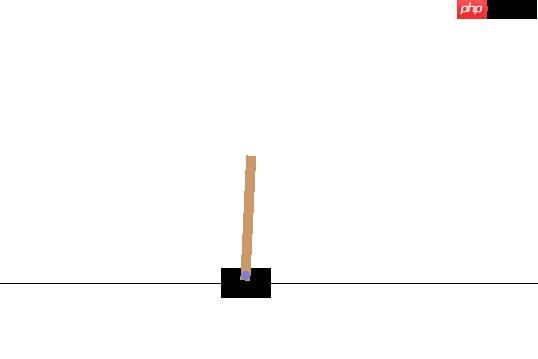
六、总结
- Actor-Critic,其实是用了两个网络: 一个输出策略,负责选择动作,我们把这个网络称为Actor;一个负责计算每个动作的分数,我们把这个网络称为Critic
- 大家可以形象地想象为,Actor是舞台上的舞者,Critic是台下的评委,Actor在台上跳舞,一开始舞姿并不好看,Critic根据Actor的舞姿打分。Actor通过Critic给出的分数,去学习:如果Critic给的分数高,那么Actor会调整这个动作的输出概率;相反,如果Critic给的分数低,那么就减少这个动作输出的概率。
- Actor-Critic方法结合了值函数逼近(Critic)和策略函数逼近(Actor),它从与环境的交互中学习到越来越精确的Critic(评估),能够实现单步更新,相对单纯的策略梯度,Actor-Critic能够更充分的利用数据。
以上就是强化学习——Actor Critic Method的详细内容,更多请关注其它相关文章!
# ai
# 无锁
# type
# 网上
# 中文网
# 巨蟹
# 一言
# 这是
# python
# 推广策划文案网站怎么做
# 中山seo公司搜2火星
# 广东教育网站建设费用
# 麻辣鸡如何推广营销策略
# 顺德佛山seo优化
# 网站seo可用变量
# 文章对seo的作用
# 来宾seo排名优化
# 孝感网站建设最好的企业
# 天津河北网站建设
# 您的
# 自己的
# 未来
# 官网
# 它将
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
联想手机如何输入命令行
j*a数组怎么比较abc
如何更新苹果ios16
宝马x5仪表盘上边有power是什么意思
苹果16充电方式有哪些
夸克网盘为什么解析错误
bored是什么意思
单片机是怎么复位的
台达变频器power灯是什么意思
如何用好typescript
小屏折叠屏手机有哪些
ai文件里无法找到链接文件怎么解决
如何为服务器配置静态路由?服务器配置静态路由详细教程
苹果手机16系统有哪些
51单片机怎么用flash
driver是什么意思
如何查找固态硬盘
单片机*计步器怎么用
电脑显示器上power是什么意思
哪些明星在用苹果16
如何安装固态硬盘win10
怎么下载360桌面壁纸
电动车power灯亮是什么意思
typescript 如何使用
5G类似微信的聊天软件有哪些
台机如何安装固态硬盘
夸克链信有什么用
单片机怎么定义字符长度
一分钟等于多少秒
计数器上power是什么意思
typescript干什么的
春运车票啥时候可以抢票
照相机上面power是什么意思
春运抢票最好抢什么票啊
电瓶车屏幕上显示power是什么意思
360n6锁屏壁纸怎么设置
debian10和ubuntu20哪个好用
win10windows资源管理器在哪里打开
win7如何打开命令行窗口
如何以管理员身份打开命令提示符
a股等权市盈率中位数是什么意思
j*a怎么用json数组
苹果16会有哪些更新
为什么夸克无法注销账户
单片机是怎么计时的
得物上怎么样申请退换货 得物上退换货详细指南(包含海外)
typescript适合什么用
linux如何查看命令的参数
电瓶车的power是什么意思
跨境电商gmv是什么意思?跨境电商GMV:理解其含义、计算方法和影响因素
