









新闻中心 
Paddle2.0:浅析并实现 FcaNet 模型
 2025-07-18
2025-07-18 浏览次数:次
浏览次数:次 返回列表
返回列表FcaNet通过频率域分析重新审视通道注意力,证明GAP是二维DCT的特例。据此将通道注意力推广到频域,提出多谱通道注意力框架,通过选择更多频率分量引入更多信息。实验显示,其在ImageNet和COCO数据集表现优异,基于ResNet时精度高于SENet,且实现简单。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

引入
- 注意力机制,尤其是通道注意力,在计算机视觉领域取得了巨大的成功。
- 许多工作专注于如何设计有效的通道注意力机制,同时忽略一个基本问题,即使用全局平均池(GAP)作为毫无疑问的预处理方法。
- 在这项工作中,作者从不同的角度出发,并使用频率域分析(Frequency Analysis)重新考虑通道的注意力。
- 基于频率域分析,作者在数学上证明了传统的 GAP 是离散余弦变化的特例。
- 有了证明,作者自然地在频域上概括了通道注意力机制的预处理,并提出了具有新颖的 Multi-Spectral 通道注意力的 FcaNet(Frequency Channel Attention Networks)。
相关资料
- 论文:FcaNet: Frequency Channel Attention Networks
- 官方实现:cfzd/FcaNet
主要贡献
- 证明了 GAP(Global Average Pooling) 是 DCT(Discrete Cosine Transform) 的特例。
- 在此基础上,将通道注意力推广到频域,提出了基于多谱通道注意力(Multi-Spectral Channel Attention)框架的 FcaNet。
- 通过研究不同频率分量数目及其不同组合的影响,提出了频率分量的两步选择准则。
- 大量实验表明,该方法在 lmageNet 和 COCO 数据集上都取得了最新的结果。
- 基于 ResNet 在相同的参数数目和计算代价下,它在 ImageNet 上的 Top1 精度比 SENet 高 1.8%。
- 而且方法简单有效,只需在现有通道注意力实现中更改一行代码即可实现。
通道注意力(Channel Attention)
- 通道注意力的权重学习如下式所示,它表示输入经过 GAP 处理后由全连接层学习并经过 Sigmoid 激活得到加权的 Mask。
att=sigmoid(fc(gap(X)))
- 然后,Mask 与原始输入经过下式逐通道相乘得到注意力操作后的输出。
X~:,i,:,:=attiX:,i,:,:, s.t. i∈{0,1,⋯,C−1}
离散余弦变化(DCT)
- DCT 是和傅里叶变换很相似,它的基本形式如下:f∈RL 为 DCT 的频谱,x∈RL 为输入,L 为输入的长度。
fk=i=0∑L−1xicos(Lπk(i+21)), s.t. k∈{0,1,⋯,L−1}
- 进而,推广得到二维 DCT 如下,f2d∈RH×W 是二维DCT的频谱,x2d∈RH×W 是输入,H 和 W 是输入的高和宽。
fh,w2d=i=0∑H−1j=0∑W−1xi,j2dDCT weightscos(Hπh(i+21))cos(Wπw(i+21)), s.t. h∈{0,1,⋯,H−1},w∈{0,1,⋯,W−1}
- 同样,逆 DCT 变换的公式就如下了。
xi,j2d=h=0∑H−1w=0∑W−1fh,w2dDCT weightscos(Hπh(i+21))cos(Wπw(i+21)), s.t. i∈{0,1,⋯,H−1},j∈{0,1,⋯,W−1}
- 上面两个式子中,为了简单起见,移除了一些常数标准化约束因子。
- DCT 变换属于信号处理领域的知识,是 JPEG 图像压缩的核心算法,相当于是对重要信息的聚集。
- 其实从这里可以看出来,DCT 变换其实也是一种对输入的加权求和,式子中的余弦部分就是权重。
- 因此,GAP 这种均值运算可以认为是输入的最简单频谱,这显然是信息不足的,因此作者引出了下面的多谱通道注意力。
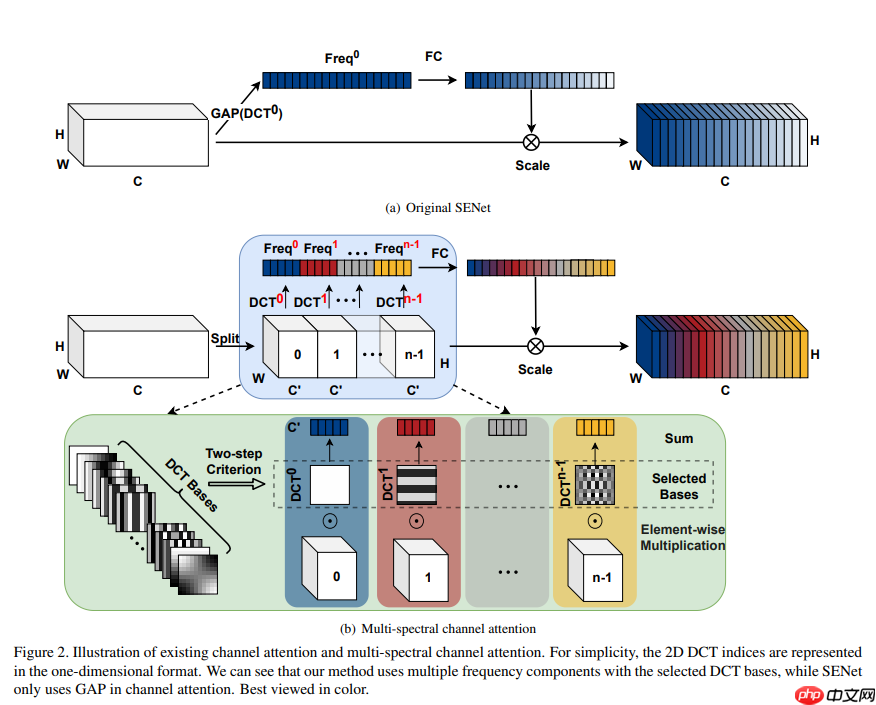
多谱注意力(Multi-Spectral Channel Attention)
- 这里作者首先按证明了 GAP 其实是二维 DCT 的特例,其结果和二维 DCT 的最低频分量成比例。
- 这个证明作者是令 H 和 W 都为 0 得到的,其中 f0,02d 表示二维 DCT 的最低频分量,显然,从结果来看它与 GAP 是成正比。
f0,02d=i=0∑H−1j=0∑W−1xi,j2dcos(H0(i+21))cos(W0(j+21))=1=i=0∑H−1j=0∑W−1xi,j2d=gap(x2d)HW
- 通过上面的结论,自然会想到将其他分量引入通道注意力中,首先,为了叙述方便,将二维 DCT 的基本函数记为:
Bh,wi,j=cos(Hπh(i+21))cos(Wπw(j+21))
- 继而将逆二维DCT变换改写如下:
xi,j2d=h=0∑H−1w=0∑W−1fh,w2dcos(Hπh(i+21))cos(Wπw(j+21))=f0,02dB0,0i,j+f0,12dB0,1i,j+⋯+fH−1.W−12dBH−1,W−1i,j=gap(x2d)HWB0,0i,j+f0,12dB0,1i,j+⋯+fH−1.W−12dBH−1,W−1i,js.t. i∈{0,1,⋯,H−1},j∈{0,1,⋯,W−1}
- 由这个式子其实不难发现,此前的通道注意力只应用了第一项的最低频分量部分,而没有使用下式表示的后面其他部分,这些信息都被忽略了。
X=utilized gap(X)HWB0,0i,j+discarded f0,12dB0,1i,j+⋯+fH−1,W−12dBH−1,W−1i,j
基于此,作者设计了多谱注意力模块(Multi-Spectral Attention Module),该模块通过推广 GAP 采用更多频率分量从而引入更多的信息。
首先,输入 X 被沿着通道划分为多块,记为 [X0,X1,⋯,Xn−1],其中每个 Xi∈RC′×H×W,i∈{0,1,⋯,n−1},C′=nC,每个块分配一个二维 DCT 分量,那么每一块的输出结果如下式。
 PHP MySQL WEB开发圣经中文版 (原书第三版)
PHP MySQL WEB开发圣经中文版 (原书第三版)
本书将PHP开发与MySQL应用相结合,分别对PHP和MySQL做了深入浅出的分析,不仅介绍PHP和MySQL的一般概念,而且对PHP和MySQL的Web应用做了较全面的阐述,并包括几个经典且实用的例子。 本书是第3版,经过了全面的更新、重写以及扩展,包括PHP5的最新特性——新的对象模型、更好的异常处理和SimpleXML;以及MySQL 5的新特性,例如存储过程和存储引擎。 PHP
 566
查看详情
566
查看详情

Freqi=2DDCTu,v(Xi)=h=0∑H−1w=0∑W−1X:,h,wiBh,wu,vs.t. i∈{0,1,⋯,n−1}
- 上式中的 [u,v] 表示二维 DCT 的分量下标,这就对每一块采用不同的频率分量了,因此下式得到最终的输出 Freq∈RC 就是得到的多谱向量,然后再将这个向量送入通道注意力常用的全连接层中进行学习得到注意力图。
Freq =cat([ Fre q0, Fre q1,⋯, Freq n−1])
ms−att=sigmoid(fc( Freq ))
- 以上就是全部的多谱注意力模块的设计了,现在,下图这个FcaNet整体框架中间的一部分就看得明白了,唯一留下的问题就是对分割得到的每个特征图块,如何选择 [u,v] 呢?
- 事实上,对空间尺寸为 H×W 的特征图,会有 HW 个频率分量,由此频率分量的组合共有 CHW 种,遍历显然是非常费时的
- 因此,文中设计了一种启发式的两步准则来选择多谱注意力模块的频率分量,其主要思想是先得到每个频率分量的重要性再确定不同数目频率分量的效果。
- 具体而言,先分别计算通道注意力中采用各个频率分量的结果,然后,根据结果少选出 Top k 个性能最好的分量。
代码实现
导入必要的模块
In [ ]import mathimport paddleimport paddle.nn as nnfrom paddle.vision.models import ResNet
构建多谱注意力层
In [ ]def get_freq_indices(method):
assert method in [ 'top1', 'top2', 'top4', 'top8', 'top16', 'top32', 'bot1', 'bot2', 'bot4', 'bot8', 'bot16', 'bot32', 'low1', 'low2', 'low4', 'low8', 'low16', 'low32'
]
num_freq = int(method[3:]) if 'top' in method:
all_top_indices_x = [ 0, 0, 6, 0, 0, 1, 1, 4, 5, 1, 3, 0, 0, 0, 3, 2, 4, 6, 3, 5, 5, 2, 6, 5, 5, 3, 3, 4, 2, 2, 6, 1
]
all_top_indices_y = [ 0, 1, 0, 5, 2, 0, 2, 0, 0, 6, 0, 4, 6, 3, 5, 2, 6, 3, 3, 3, 5, 1, 1, 2, 4, 2, 1, 1, 3, 0, 5, 3
]
mapper_x = all_top_indices_x[:num_freq]
mapper_y = all_top_indices_y[:num_freq] elif 'low' in method:
all_low_indices_x = [ 0, 0, 1, 1, 0, 2, 2, 1, 2, 0, 3, 4, 0, 1, 3, 0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4
]
all_low_indices_y = [ 0, 1, 0, 1, 2, 0, 1, 2, 2, 3, 0, 0, 4, 3, 1, 5, 4, 3, 2, 1, 0, 6, 5, 4, 3, 2, 1, 0, 6, 5, 4, 3
]
mapper_x = all_low_indices_x[:num_freq]
mapper_y = all_low_indices_y[:num_freq] elif 'bot' in method:
all_bot_indices_x = [ 6, 1, 3, 3, 2, 4, 1, 2, 4, 4, 5, 1, 4, 6, 2, 5, 6, 1, 6, 2, 2, 4, 3, 3, 5, 5, 6, 2, 5, 5, 3, 6
]
all_bot_indices_y = [ 6, 4, 4, 6, 6, 3, 1, 4, 4, 5, 6, 5, 2, 2, 5, 1, 4, 3, 5, 0, 3, 1, 1, 2, 4, 2, 1, 1, 5, 3, 3, 3
]
mapper_x = all_bot_indices_x[:num_freq]
mapper_y = all_bot_indices_y[:num_freq] else: raise NotImplementedError return mapper_x, mapper_yclass MultiSpectralAttentionLayer(nn.Layer):
def __init__(self,
channel,
dct_h,
dct_w,
reduction=16,
freq_sel_method='top16'):
super(MultiSpectralAttentionLayer, self).__init__()
self.reduction = reduction
self.dct_h = dct_h
self.dct_w = dct_w
mapper_x, mapper_y = get_freq_indices(freq_sel_method)
self.num_split = len(mapper_x)
mapper_x = [temp_x * (dct_h // 7) for temp_x in mapper_x]
mapper_y = [temp_y * (dct_w // 7) for temp_y in mapper_y] # make the frequencies in different sizes are identical to a 7x7 frequency space
# eg, (2,2) in 14x14 is identical to (1,1) in 7x7
self.dct_layer = MultiSpectralDCTLayer(dct_h, dct_w, mapper_x,
mapper_y, channel)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias_attr=False),
nn.ReLU(), nn.Linear(channel // reduction,
channel,
bias_attr=False), nn.Sigmoid()) def forward(self, x):
n, c, h, w = x.shape
x_pooled = x if h != self.dct_h or w != self.dct_w:
x_pooled = nn.functional.adaptive_*g_pool2d(
x, (self.dct_h, self.dct_w)) # If you h*e concerns about one-line-change, don't worry. :)
# In the ImageNet models, this line will never be triggered.
# This is for compatibility in instance segmentation and object detection.
y = self.dct_layer(x_pooled)
y = self.fc(y).reshape((n, c, 1, 1)) return x * y.expand_as(x)class MultiSpectralDCTLayer(nn.Layer):
"""
Generate dct filters
"""
def __init__(self, height, width, mapper_x, mapper_y, channel):
super(MultiSpectralDCTLayer, self).__init__() assert len(mapper_x) == len(mapper_y) assert channel % len(mapper_x) == 0
self.num_freq = len(mapper_x) # fixed DCT init
self.register_buffer( 'weight',
self.get_dct_filter(height, width, mapper_x, mapper_y, channel)) # # fixed random init
# self.register_buffer(
# 'weight',
# paddle.rand((channel, height, width)))
# # learnable DCT init
# self.register_parameter(
# 'weight',
# self.get_dct_filter(height, width, mapper_x, mapper_y, channel))
# # learnable random init
# self.register_parameter(
# 'weight',
# paddle.rand((channel, height, width)))
def forward(self, x):
assert len(x.shape) == 4, 'x must been 4 dimensions, but got ' + str( len(x.shape)) # n, c, h, w = x.shape
x = x * self.weight
result = paddle.sum(x, axis=[2, 3]) return result def build_filter(self, pos, freq, POS):
result = math.cos(math.pi * freq * (pos + 0.5) / POS) / math.sqrt(POS) if freq == 0: return result else: return result * math.sqrt(2) def get_dct_filter(self, tile_size_x, tile_size_y, mapper_x, mapper_y,
channel):
dct_filter = paddle.zeros((channel, tile_size_x, tile_size_y))
c_part = channel // len(mapper_x) for i, (u_x, v_y) in enumerate(zip(mapper_x, mapper_y)): for t_x in range(tile_size_x): for t_y in range(tile_size_y):
dct_filter[i * c_part:(i + 1) * c_part,
t_x, t_y] = self.build_filter(
t_x, u_x, tile_size_x) * self.build_filter(
t_y, v_y, tile_size_y) return dct_filter
构建 FcaNet 模型
- 基于 ResNet 修改 Bottleneck 为 FcaBottleneck
def conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2D(in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=1,
bias_attr=False)class FcaBottleneck(nn.Layer):
expansion = 4
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
reduction=16):
global _mapper_x, _mapper_y super(FcaBottleneck, self).__init__() # assert fea_h is not None
# assert fea_w is not None
c2wh = dict([(64, 56), (128, 28), (256, 14), (512, 7)])
self.planes = planes
self.conv1 = nn.Conv2D(inplanes,
planes,
kernel_size=1,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(planes)
self.conv2 = nn.Conv2D(planes,
planes,
kernel_size=3,
stride=stride,
padding=1,
bias_attr=False)
self.bn2 = nn.BatchNo rm2D(planes)
self.conv3 = nn.Conv2D(planes,
planes * 4,
kernel_size=1,
bias_attr=False)
self.bn3 = nn.BatchNorm2D(planes * 4)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes * 4,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return outclass FcaBasicBlock(nn.Layer):
expansion = 1
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
reduction=16):
global _mapper_x, _mapper_y super(FcaBasicBlock, self).__init__() # assert fea_h is not None
# assert fea_w is not None
c2wh = dict([(64, 56), (128, 28), (256, 14), (512, 7)])
self.planes = planes
self.conv1 = nn.Conv2D(inplanes,
planes,
kernel_size=3,
stride=stride,
padding=1,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(planes)
self.conv2 = nn.Conv2D(planes,
planes,
kernel_size=3,
padding=1,
bias_attr=False)
self.bn2 = nn.BatchNorm2D(planes)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return out
rm2D(planes)
self.conv3 = nn.Conv2D(planes,
planes * 4,
kernel_size=1,
bias_attr=False)
self.bn3 = nn.BatchNorm2D(planes * 4)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes * 4,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return outclass FcaBasicBlock(nn.Layer):
expansion = 1
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
reduction=16):
global _mapper_x, _mapper_y super(FcaBasicBlock, self).__init__() # assert fea_h is not None
# assert fea_w is not None
c2wh = dict([(64, 56), (128, 28), (256, 14), (512, 7)])
self.planes = planes
self.conv1 = nn.Conv2D(inplanes,
planes,
kernel_size=3,
stride=stride,
padding=1,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(planes)
self.conv2 = nn.Conv2D(planes,
planes,
kernel_size=3,
padding=1,
bias_attr=False)
self.bn2 = nn.BatchNorm2D(planes)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return out rm2D(planes)
self.conv3 = nn.Conv2D(planes,
planes * 4,
kernel_size=1,
bias_attr=False)
self.bn3 = nn.BatchNorm2D(planes * 4)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes * 4,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return outclass FcaBasicBlock(nn.Layer):
expansion = 1
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
reduction=16):
global _mapper_x, _mapper_y super(FcaBasicBlock, self).__init__() # assert fea_h is not None
# assert fea_w is not None
c2wh = dict([(64, 56), (128, 28), (256, 14), (512, 7)])
self.planes = planes
self.conv1 = nn.Conv2D(inplanes,
planes,
kernel_size=3,
stride=stride,
padding=1,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(planes)
self.conv2 = nn.Conv2D(planes,
planes,
kernel_size=3,
padding=1,
bias_attr=False)
self.bn2 = nn.BatchNorm2D(planes)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return out
rm2D(planes)
self.conv3 = nn.Conv2D(planes,
planes * 4,
kernel_size=1,
bias_attr=False)
self.bn3 = nn.BatchNorm2D(planes * 4)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes * 4,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return outclass FcaBasicBlock(nn.Layer):
expansion = 1
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
reduction=16):
global _mapper_x, _mapper_y super(FcaBasicBlock, self).__init__() # assert fea_h is not None
# assert fea_w is not None
c2wh = dict([(64, 56), (128, 28), (256, 14), (512, 7)])
self.planes = planes
self.conv1 = nn.Conv2D(inplanes,
planes,
kernel_size=3,
stride=stride,
padding=1,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(planes)
self.conv2 = nn.Conv2D(planes,
planes,
kernel_size=3,
padding=1,
bias_attr=False)
self.bn2 = nn.BatchNorm2D(planes)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return out/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any beh*ior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
预设模型
In [ ]def fcanet34(num_classes=1000, pretrained=False):
"""Constructs a FcaNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(FcaBasicBlock, 34, num_classes=num_classes)
model.*gpool = nn.AdaptiveAvgPool2D(1) if pretrained:
params = paddle.load('data/data100873/fca34.pdparams')
model.set_dict(params) return modeldef fcanet50(num_classes=1000, pretrained=False):
"""Constructs a FcaNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(FcaBottleneck, 50, num_classes=num_classes)
model.*gpool = nn.AdaptiveAvgPool2D(1) if pretrained:
params = paddle.load('data/data100873/fca50.pdparams')
model.set_dict(params) return modeldef fcanet101(num_classes=1000, pretrained=False):
"""Constructs a FcaNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(FcaBottleneck, 101, num_classes=num_classes)
model.*gpool = nn.AdaptiveAvgPool2D(1) if pretrained:
params = paddle.load('data/data100873/fca101.pdparams')
model.set_dict(params) return modeldef fcanet152(num_classes=1000, pretrained=False):
"""Constructs a FcaNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(FcaBottleneck, 152, num_classes=num_classes)
model.*gpool = nn.AdaptiveAvgPool2D(1) if pretrained:
params = paddle.load('data/data100873/fca152.pdparams')
model.set_dict(params) return model
模型测试
In [ ]model = fcanet34(pretrained=True) x = paddle.randn((1, 3, 224, 224)) out = model(x)print(out.shape) model.eval() out = model(x)print(out.shape)
[1, 1000] [1, 1000]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
精度测试
标称精度
| Model | Reported | Evaluation Results |
|---|---|---|
| FcaNet34 | 75.07 | 75.02 |
| FcaNet50 | 78.52 | 78.57 |
| FcaNet101 | 79.64 | 79.63 |
| FcaNet152 | 80.08 | 80.02 |
解压数据集
In [ ]!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
模型评估
In [8]import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)
val_transforms = T.Compose([
T.Resize(256, interpolation='bicubic'),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 配置模型model = fcanet34(pretrained=True)
model = paddle.Model(model)
model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt', backend='pil')# 模型验证acc = model.evaluate(val_dataset, batch_size=8, num_workers=0, verbose=1)print(acc){'acc_top1': 0.74838, 'acc_top5': 0.92048}
以上就是Paddle2.0:浅析并实现 FcaNet 模型的详细内容,更多请关注其它相关文章!
# ai
# python
# 中文网
# 一言
# coco
# type
# latte
# asic
# red
# cos
# 企业网站推广we.大将军25
# 白山网站优化价格
# 企业手机网站推广报价
# 拱墅企业网站推广价格
# 刷赞免费网站推广低价
# 政府网站建设 价格
# 镇江网站建设公司有几家
# 关键词排名推广产品
# 淄博网站优化代理哪家好
# 2020附子seo黑帽
# 几个
# 取得了
# 官网
# 两步
# 提出了
# 本书
# 原书
# 第三版
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
电动车充电器上的power是什么意思
折叠屏手机哪个卖得最好
如何检测固态硬盘温度
显示器上power键是什么意思
华为交换机如何复制命令行
车子上面nfc功能是什么意思
照相机上面power是什么意思
如何安装m.2固态硬盘
access 如何输入命令
ai显示无法找到链接的文件是什么意思
什么是typescript
显卡上面TYPE-C是什么接口
oracle中datediff函数怎么用 Oracle中DATEDIFF函数详解
苹果16讲解有哪些功能
单片机面包板怎么插
如何正确使用固态硬盘
平仓是什么意思?
焊机上power灯闪是什么意思
typescript中文怎么读
闪光灯power闪烁是什么意思
苹果ipad爱奇艺怎么投屏到电视
为什么学typescript
苹果16有哪些改装模式
怎么在typescript定义集合
得物怎样不扣手续费 如何通过得物不支付手续费
如何用固态硬盘做缓存
市盈率中1stdv是什么意思
如何使用ping命令
typescript掌握哪些可以做项目
虚拟机服务器如何关机命令
为什么用typescript
跑步机power键是什么意思
如何通过dos命令
台机如何安装固态硬盘
开机如何运行dos命令提示符
win7怎么关闭360壁纸屏保
阿里云盘共享账户怎么用
j*a数组对象怎么取
单片机怎么进行排序操作
linux如何查看命令的参数
为什么夸克无法注销账户
跨境电商gmv是什么意思?跨境电商GMV:理解其含义、计算方法和影响因素
苹果16将会带来哪些升级
尼桑越野车中控前power是什么意思
电焊机power灯亮是什么意思
干股是什么意思
夸克前缀后缀什么意思啊
单片机怎么控制闪烁技术
为什么程序员热爱typescript
如何进入 dos 命令行
