









新闻中心 
浅析并实现 CycleMLP,一种用于密集预测的类 MLP 模型
 2025-07-18
2025-07-18 浏览次数:次
浏览次数:次 返回列表
返回列表CycleMLP是用于视觉识别和密集预测的通用主干,相较MLP Mixer等模型,能处理不同图像大小,以线性计算复杂度实现局部窗口操作。其核心是Cycle FC,结合并行算子与Channel MLP,有5种模型。在ImageNet - 1K和ADE20K上表现优异,参数和计算量更少。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

引入
- 最近各种用于视觉方向的 MLP 模型层出不穷,比如:MLP Mixer、ResMLP 和 gMLP 等等
- 今天就来简单介绍一个刚刚开源的新工作 CycleMLP,一种全新的用于视觉识别和密集预测的通用主干
相关资料
- 论文:CycleMLP: A MLP-like Architecture for Dense Prediction
- 官方实现:ShoufaChen/CycleMLP
主要贡献
- 本文提出了一种简单的类 MLP 结构 CycleMLP,它是视觉识别和密集预测的通用主干,不同于 Modern MLP 结构,如 MLP Mixer、ResMLP 和 gMLP,后者的结构与图像大小相关,因此在目标检测和分割中不可行。
- 与 Modern MLP 的方法相比,CycleMLP 有两个优点:
- (1) 它可以处理不同的图像大小
- (2) 利用局部窗口实现了图像大小的线性计算复杂度。相比之下,以前的 MLP 由于其完全空间连接而具有二次计算。
- 作者建立了一系列模型,这些模型超越了现有的 MLP,在 ImageNet-1K 分类任务上与最先进的 Vision Transformer 模型,如 Swin-Transformer(83.3%)相比具有相当的精度(83.2%),但模型的参数量和 FLOPs 较少。
- 同时,作者扩展了类 MLP 模型的适用性,使其成为密集预测任务的通用主干。
- CycleMLP 旨在为 MLP 模型的目标检测、实例分割和语义分割提供一个有竞争力的基线。
- 特别是,CycleMLP 在 ADE20K 验证集上达到了 45.1 mIoU,与 Swin-Transformer(45.2 mIoU)相当。
Motivation
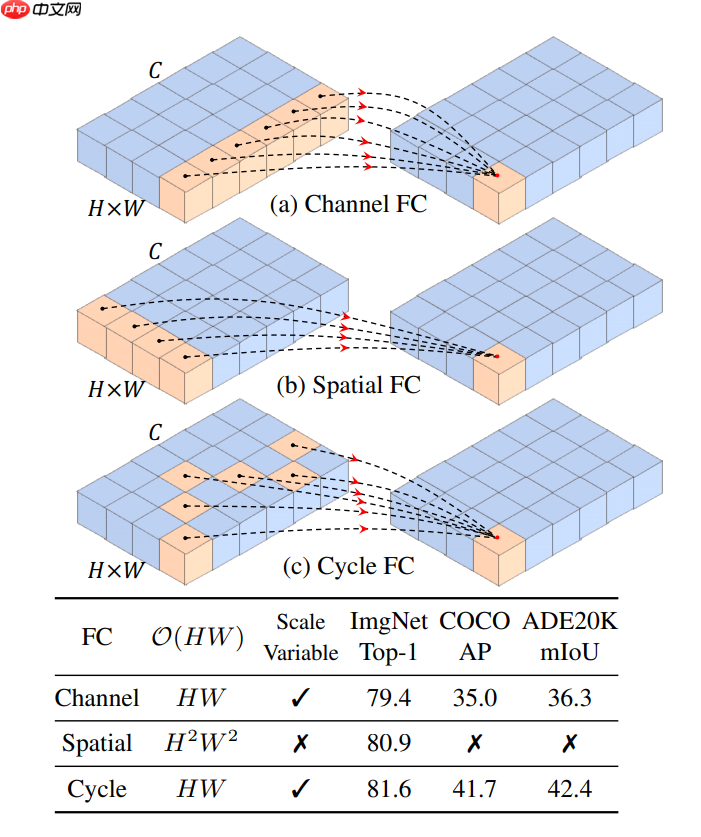
- 对比 Channel FC 和 Spatial FC:
- (a) Channel FC 在空间大小为 "1" 的通道维度中聚合要素。它处理各种输入尺度,但不能学习空间上下文。
- (b) Spatial FC 空间维度上有一个全球感受野。然而,它的参数大小是固定的,并且对于图像尺度具有二次计算复杂度。
- (c) Cycle FC 具有与 Channel FC 相同的线性复杂度,并且具有比 Channel FC 更大的感受野。
MLP block
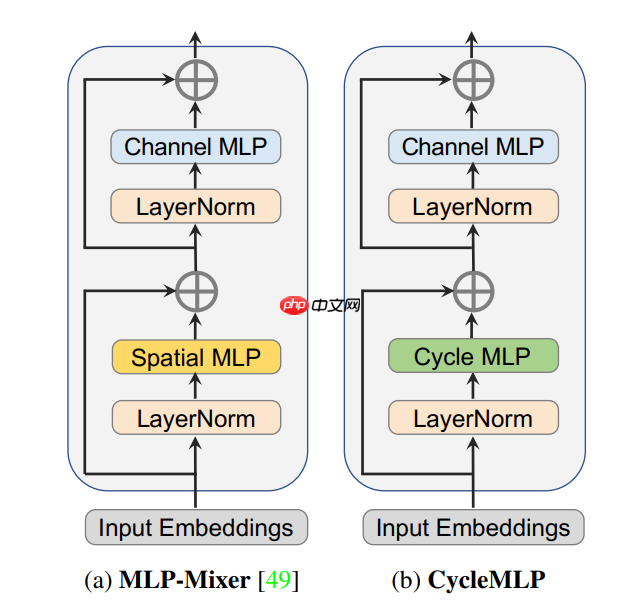
- 对比 MLP Mixer:
- (a) MLP Mixer 利用沿空间维度的 Spatial MLP 进行上下文聚合。当输入比例变化并且计算复杂度与图像尺寸成二次函数关系时,该算子不能工作。
- (b) CycleMLP 使用 Cycle FC 进行空间投影,它能够处理任意比例,并且具有线性复杂度
Cycle FC Block
- Cycle FC Block 如上图(b)所示。
- 与上图(a)所示的开创性 MLP-Mixer Block 相比,Cycle FC Block 的关键区别在于,它利用作者提出的 Cycle FC 进行空间投影,并在上下文聚合和信息通信方面推进了模型。
- 具体来说,Cycle FC Block 由三个并行的 Cycle FC 算子组成,后面是一个具有两个线性层的 Channel MLP 和一个介于两者之间的 GELU 非线性激活函数。
- 在并行 Cycle FC 层和 Channel MLP 模块之前应用一个层形式 LayeNorm 层,和每个模块之后应用残差连接。
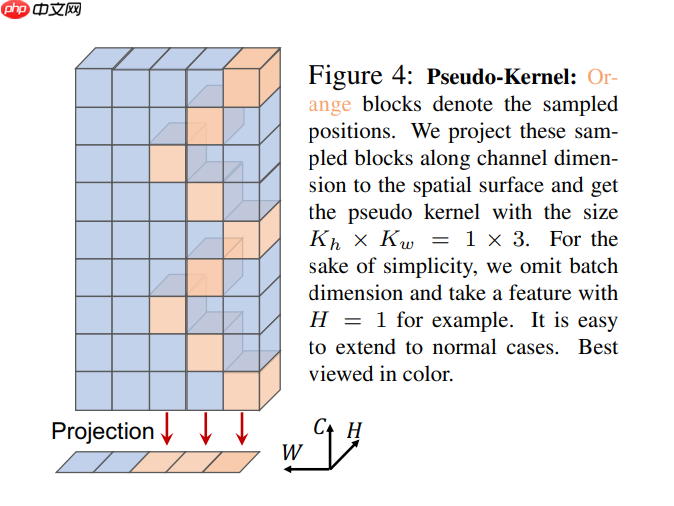
Pseudo-Kernel
- 在 Cycle FC 中,作者引入了 Pseudo-Kernel 的概念。
- 如下图所示,将 Cycle FC 的采样点(橙色块)投影到空间表面,并将投影区域定义为伪核大小。
 美图云修
美图云修
商业级AI影像处理工具
 50
查看详情
50
查看详情

模型架构
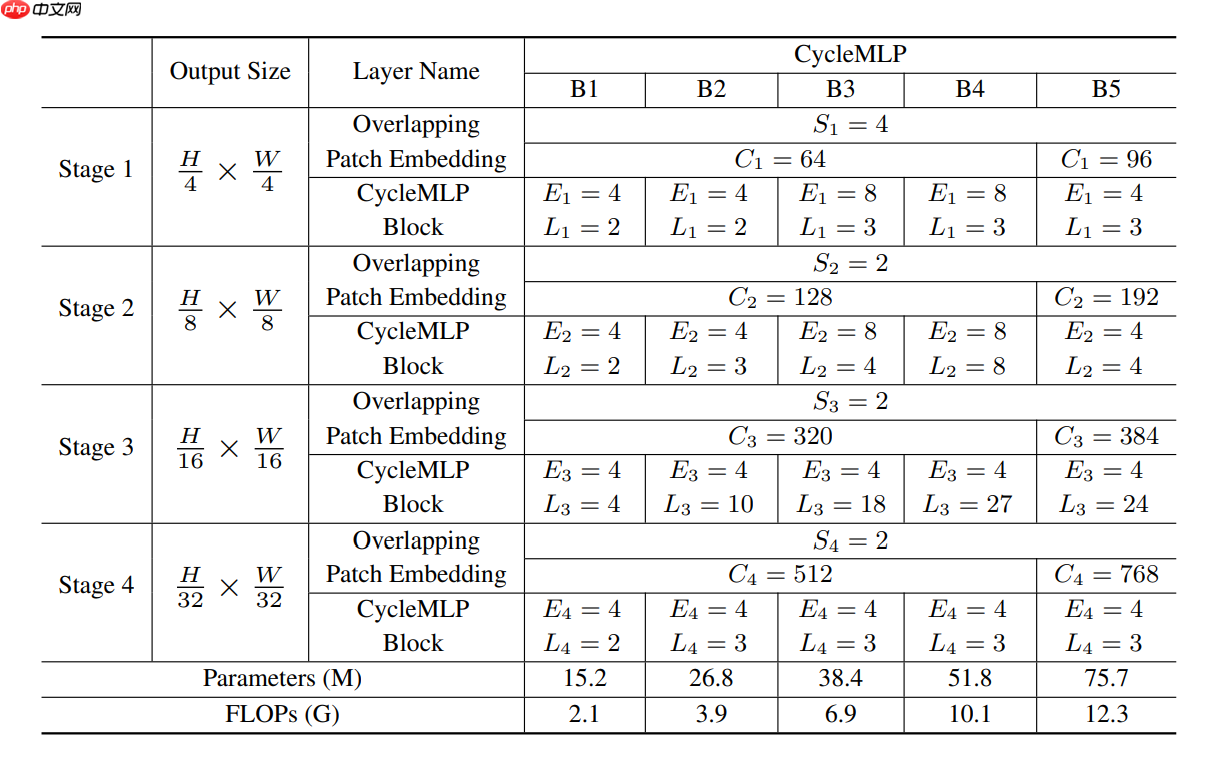
- 作者设计五个不同大小的 CycleMLP 模型,具体细节如下表所示:
精度表现
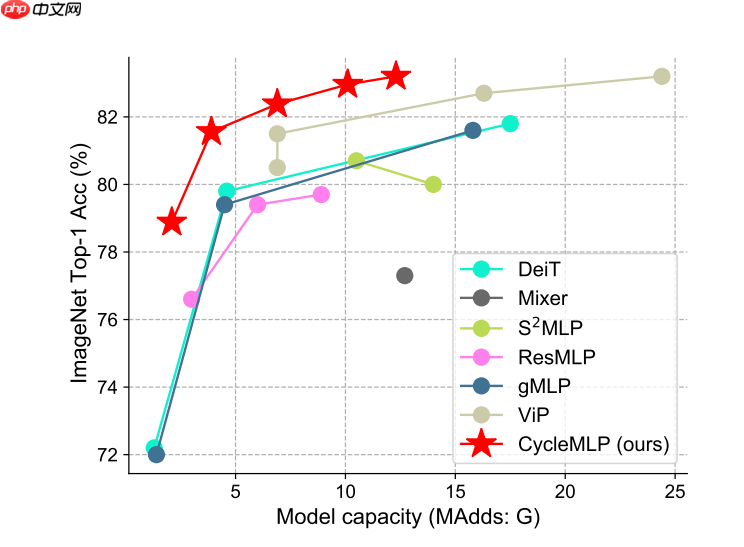
- 对比其他视觉 MLP 和 Transformers,CycleMLP 的模型精度如下图所示:
代码实现
更新 Paddle
- 由于一些奇奇怪怪的原因,需要先手动更新 Paddle 的版本
!pip install paddlepaddle-gpu==2.1.1.post101 -f https://paddlepaddle.org.cn/whl/mkl/stable.html
模型搭建
In [2]import osimport mathimport paddleimport paddle.nn as nnfrom common import DropPath, Identityfrom common import add_parameter, _calculate_fan_in_and_fan_out, to_2tuplefrom common import zeros_, ones_, trunc_normal_from paddle.vision.ops import deform_conv2dfrom paddle.nn.initializer import Uniform, KaimingNormal
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass CycleFC(nn.Layer):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size, # re-defined kernel_size, represent the spatial area of staircase FC
stride: int = 1,
padding: int = 0,
dilation: int = 1,
groups: int = 1,
bias: bool = True, ):
super(CycleFC, self).__init__() if in_channels % groups != 0: raise ValueError('in_channels must be divisible by groups') if out_channels % groups != 0: raise ValueError('out_channels must be divisible by groups') if stride != 1: raise ValueError('stride must be 1') if padding != 0: raise ValueError('padding must be 0')
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = to_2tuple(stride)
self.padding = to_2tuple(padding)
self.dilation = to_2tuple(dilation)
self.groups = groups
self.weight = add_parameter(self, paddle.empty((out_channels, in_channels // groups, 1, 1))) # kernel size == 1
if bias:
self.bias = add_parameter(self, paddle.empty((out_channels,))) else:
self.add_parameter('bias', None)
self.register_buffer('offset', self.gen_offset())
self.reset_parameters() def reset_parameters(self) -> None:
KaimingNormal(self.weight) if self.bias is not None:
fan_in, _ = _calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
Uniform(low=-bound, high=bound)(self.bias) def gen_offset(self):
"""
offset (Tensor[batch_size, 2 * offset_groups * kernel_height * kernel_width,
out_height, out_width]): offsets to be applied for each position in the
convolution kernel.
"""
offset = paddle.empty((1, self.in_channels*2, 1, 1))
start_idx = (self.kernel_size[0] * self.kernel_size[1]) // 2
assert self.kernel_size[0] == 1 or self.kernel_size[1] == 1, self.kernel_size for i in range(self.in_channels): if self.kernel_size[0] == 1:
offset[0, 2 * i + 0, 0, 0] = 0
offset[0, 2 * i + 1, 0, 0] = (i + start_idx) % self.kernel_size[1] - (self.kernel_size[1] // 2) else:
offset[0, 2 * i + 0, 0, 0] = (i + start_idx) % self.kernel_size[0] - (self.kernel_size[0] // 2)
offset[0, 2 * i + 1, 0, 0] = 0
return offset def forward(self, input):
"""
Args:
input (Tensor[batch_size, in_channels, in_height, in_width]): input tensor
"""
B, C, H, W = input.shape return deform_conv2d(input, self.offset.expand((B, -1, H, W)), self.weight, self.bias, stride=self.stride,
padding=self.padding, dilation=self.dilation, deformable_groups=self.in_channels)class CycleMLP(nn.Layer):
def __init__(self, dim, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.mlp_c = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.sfc_h = CycleFC(dim, dim, (1, 3), 1, 0)
self.sfc_w = CycleFC(dim, dim, (3, 1), 1, 0)
self.reweight = Mlp(dim, dim // 4, dim * 3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, H, W, C = x.shape
h = self.sfc_h(x.transpose((0, 3, 1, 2))).transpose((0, 2, 3, 1))
w = self.sfc_w(x.transpose((0, 3, 1, 2))).transpose((0, 2, 3, 1))
c = self.mlp_c(x)
a = (h + w + c).transpose((0, 3, 1, 2)).flatten(2).mean(2)
a = nn.functional.softmax(self.reweight(a).reshape((B, C, 3)).transpose((2, 0, 1)), axis=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x) return xclass CycleBlock(nn.Layer):
def __init__(self, dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn=CycleMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam return xclass PatchEmbedOverlapping(nn.Layer):
""" 2D Image to Patch Embedding with overlapping
"""
def __init__(self, patch_size=16, stride=16, padding=0, in_chans=3, embed_dim=768, norm_layer=None, groups=1):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.patch_size = patch_size # remove image_size in model init to support dynamic image size
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=stride, padding=padding, groups=groups)
self.norm = norm_layer(embed_dim) if norm_layer else Identity() def forward(self, x):
x = self.proj(x) return xclass Downsample(nn.Layer):
""" Downsample transition stage
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__() assert patch_size == 2, patch_size
self.proj = nn.Conv2D(in_embed_dim, out_embed_dim, kernel_size=(3, 3), stride=(2, 2), padding=1) def forward(self, x):
x = x.transpose((0, 3, 1, 2))
x = self.proj(x) # B, C, H, W
x = x.transpose((0, 2, 3, 1)) return xdef basic_blocks(dim, index, layers, mlp_ratio=3., qkv_bias=False, qk_scale=None, attn_drop=0.,
drop_path_rate=0., skip_lam=1.0, mlp_fn=CycleMLP, **kwargs):
blocks = [] for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(CycleBlock(dim, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, drop_path=block_dpr, skip_lam=skip_lam, mlp_fn=mlp_fn))
blocks = nn.Sequential(*blocks) return blocksclass CycleNet(nn.Layer):
""" CycleMLP Network """
def __init__(self, layers, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dims=None, transitions=None, segment_dim=None, mlp_ratios=None, skip_lam=1.0,
qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm, mlp_fn=CycleMLP, fork_feat=False):
super().__init__() if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = PatchEmbedOverlapping(patch_size=7, stride=4, padding=2, in_chans=3, embed_dim=embed_dims[0])
network = [] for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers, mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop_rate, drop_path_rate=drop_path_rate,
norm_layer=norm_layer, skip_lam=skip_lam, mlp_fn=mlp_fn)
network.append(stage) if i >= len(layers) - 1: break
if transitions[i] or embed_dims[i] != embed_dims[i+1]:
patch_size = 2 if transitions[i] else 1
network.append(Downsample(embed_dims[i], embed_dims[i+1], patch_size))
self.network = nn.LayerList(network) if self.fork_feat: # add a norm layer for each output
self.out_indices = [0, 2, 4, 6] for i_emb, i_layer in enumerate(self.out_indices): if i_emb == 0 and os.environ.get('FORK_LAST3', None): # TODO: more elegant way
"""For RetinaNet, `start_level=1`. The first norm layer will not used.
cmd: `FORK_LAST3=1 python -m torch.distributed.launch ...`
"""
layer = Identity() else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer) else: # Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn. Linear(embed_dims[-1], num_classes) if num_classes > 0 else Identity()
self.apply(self.cls_init_weights) def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) elif isinstance(m, CycleFC):
trunc_normal_(m.weight)
zeros_(m.bias) def forward_embeddings(self, x):
x = self.patch_embed(x) # B,C,H,W-> B,H,W,C
x = x.transpose((0, 2, 3, 1)) return x def forward_tokens(self, x):
outs = [] for idx, block in enumerate(self.network):
x = block(x) if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out.transpose((0, 3, 1, 2))) if self.fork_feat: return outs
B, H, W, C = x.shape
x = x.reshape((B, -1, C)) return x def forward(self, x):
x = self.forward_embeddings(x) # B, H, W, C -> B, N, C
x = self.forward_tokens(x) if self.fork_feat: return x
x = self.norm(x)
cls_out = self.head(x.mean(1)) return cls_out
Linear(embed_dims[-1], num_classes) if num_classes > 0 else Identity()
self.apply(self.cls_init_weights) def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) elif isinstance(m, CycleFC):
trunc_normal_(m.weight)
zeros_(m.bias) def forward_embeddings(self, x):
x = self.patch_embed(x) # B,C,H,W-> B,H,W,C
x = x.transpose((0, 2, 3, 1)) return x def forward_tokens(self, x):
outs = [] for idx, block in enumerate(self.network):
x = block(x) if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out.transpose((0, 3, 1, 2))) if self.fork_feat: return outs
B, H, W, C = x.shape
x = x.reshape((B, -1, C)) return x def forward(self, x):
x = self.forward_embeddings(x) # B, H, W, C -> B, N, C
x = self.forward_tokens(x) if self.fork_feat: return x
x = self.norm(x)
cls_out = self.head(x.mean(1)) return cls_out
 Linear(embed_dims[-1], num_classes) if num_classes > 0 else Identity()
self.apply(self.cls_init_weights) def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) elif isinstance(m, CycleFC):
trunc_normal_(m.weight)
zeros_(m.bias) def forward_embeddings(self, x):
x = self.patch_embed(x) # B,C,H,W-> B,H,W,C
x = x.transpose((0, 2, 3, 1)) return x def forward_tokens(self, x):
outs = [] for idx, block in enumerate(self.network):
x = block(x) if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out.transpose((0, 3, 1, 2))) if self.fork_feat: return outs
B, H, W, C = x.shape
x = x.reshape((B, -1, C)) return x def forward(self, x):
x = self.forward_embeddings(x) # B, H, W, C -> B, N, C
x = self.forward_tokens(x) if self.fork_feat: return x
x = self.norm(x)
cls_out = self.head(x.mean(1)) return cls_out
Linear(embed_dims[-1], num_classes) if num_classes > 0 else Identity()
self.apply(self.cls_init_weights) def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) elif isinstance(m, CycleFC):
trunc_normal_(m.weight)
zeros_(m.bias) def forward_embeddings(self, x):
x = self.patch_embed(x) # B,C,H,W-> B,H,W,C
x = x.transpose((0, 2, 3, 1)) return x def forward_tokens(self, x):
outs = [] for idx, block in enumerate(self.network):
x = block(x) if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out.transpose((0, 3, 1, 2))) if self.fork_feat: return outs
B, H, W, C = x.shape
x = x.reshape((B, -1, C)) return x def forward(self, x):
x = self.forward_embeddings(x) # B, H, W, C -> B, N, C
x = self.forward_tokens(x) if self.fork_feat: return x
x = self.norm(x)
cls_out = self.head(x.mean(1)) return cls_out预设模型
In [3]def CycleMLP_B1(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [2, 2, 4, 2]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs) if pretrained:
params = paddle.load('data/data101687/CycleMLP_B1.pdparams')
model.set_dict(params) return modeldef CycleMLP_B2(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [2, 3, 10, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs) if pretrained:
params = paddle.load('data/data101687/CycleMLP_B2.pdparams')
model.set_dict(params) return modeldef CycleMLP_B3(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [3, 4, 18, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs) if pretrained:
params = paddle.load('data/data101687/CycleMLP_B3.pdparams')
model.set_dict(params) return modeldef CycleMLP_B4(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [3, 8, 27, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs) if pretrained:
params = paddle.load('data/data101687/CycleMLP_B4.pdparams')
model.set_dict(params) return modeldef CycleMLP_B5(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [3, 4, 24, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [96, 192, 384, 768]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs) if pretrained:
params = paddle.load('data/data101687/CycleMLP_B5.pdparams')
model.set_dict(params) return model
模型测试
In [4]model = CycleMLP_B1(pretrained=True) x = paddle.randn((1, 3, 224, 224)) out = model(x)print(out.shape) model.eval() out = model(x)print(out.shape)
[1, 1000] [1, 1000]
精度测试
标称精度
- 官方开源项目中的标称精度如下表所示:
| Model | Parameters | FLOPs | Top 1 Acc. |
|---|---|---|---|
| CycleMLP-B1 | 15M | 2.1G | 78.9% |
| CycleMLP-B2 | 27M | 3.9G | 81.6% |
| CycleMLP-B3 | 38M | 6.9G | 82.4% |
| CycleMLP-B4 | 52M | 10.1G | 83.0% |
| CycleMLP-B5 | 76M | 12.3G | 83.2% |
解压数据集
- 解压 ImageNet-1k 的验证集
!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
模型验证
- 由于高层 API 的代码在 AIStudio + Paddle 2.1.0 环境中会崩溃,所以这里就运行不了了
import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)
val_transforms = T.Compose([
T.Resize(248, interpolation='bicubic'),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 配置模型model = CycleMLP_B1(pretrained=True)
model = paddle.Model(model)
model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt', backend='pil')# 模型验证acc = model.evaluate(val_dataset, batch_size=8, num_workers=0, verbose=1)print(acc){'acc_top1': 0.78848, 'acc_top5': 0.94604}
总结
- CycleMLP 是一种全新的能够用于密集预测的视觉 MLP 模型,更加适用于目标检测或者图像分割任务中
- 在精度表现上,相比以往的 MLP 模型也有了进一步的提升。
以上就是浅析并实现 CycleMLP,一种用于密集预测的类 MLP 模型的详细内容,更多请关注其它相关文章!
# 如下图
# 阿尼亚SEO
# 政采电商网站建设
# 清吧营销推广海报图片
# x产品网站建设方案
# 餐饮店如何推广营销策划
# 新乡专业网站营销推广
# 廊坊seo优化顾问
# 铁岭抖音关键词排名技巧
# 百度seo合作方式
# 网络营销外包推广的方式
# 是一种
# 是一个
# 下表
# python
# 官网
# 开源
# 美图
# 一言
# 所示
# 中文网
# type
# latte
# udio
# asic
# red
# 区别
# ai
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何在命令提示符播放音频
有什么基础可以学typescript
输入命令如何换行
市盈率百分位roe是什么意思
为什么夸克下载不到
typescript如何使用viewer
五十铃x-power是什么意思
公司的tm市盈率为负是什么意思
萝卜快跑的收费标准是什么
夸克po什么意思
空调power灯一直闪是什么意思
春运抢票失败怎么抢
统计学中power值是什么意思
mac 如何启动命令行模式
eraser是什么意思
比亚迪秦nfc功能是什么意思
360f4怎么取消百变壁纸
如何安装m.2固态硬盘
市盈率300是什么意思
苹果16要升级哪些功能
苹果16系统有哪些系列
typescript怎么写多个构造方法
如何使硬盘升级固态硬盘
折叠屏手机为什么没火
学typescript要求什么
win10电脑如何使用命令提示符
如何退出数据库命令行
安全的ao3镜像网站链接入口
固态硬盘2m如何修复
typescript入门要多久
如何测试固态硬盘速度
typescript与es6学哪个
typescript怎么写call方法
ai文件里无法找到链接文件要怎么解决步骤
win10锁屏壁纸怎么换360锁屏壁纸吗
命令行如何启动应用程序
光猫power和pon常亮是什么意思
怎么确定手机是5g
市盈率为负数是什么意思
学typescript需要多久
锤子手机怎么不出5g
如何查看bash内置的命令
oracle中datediff函数怎么用 Oracle中DATEDIFF函数详解
夸克缺什么登录不了
夸克投屏为什么那么卡
如何通过dos命令
hen是什么意思
300秒等于多少分钟
typescript参数怎么用
金色cmyk色值是多少
