









新闻中心 
ViP:类MLP架构又一狂欢
 2025-07-18
2025-07-18 浏览次数:次
浏览次数:次 返回列表
返回列表本文复现程明明、颜水成团队的MLP相关论文,提出引入h、w、c三维信息编码机制及加权融合方式的模型。该模型无需空域卷积、注意力及额外da尺度训练数据,性能与CNN、ViT相当。文中展示了模型组网、定义、结构可视化等内容,还进行了Cifar10验证性能测试,指出类MLP方法有较大改进空间。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

前言
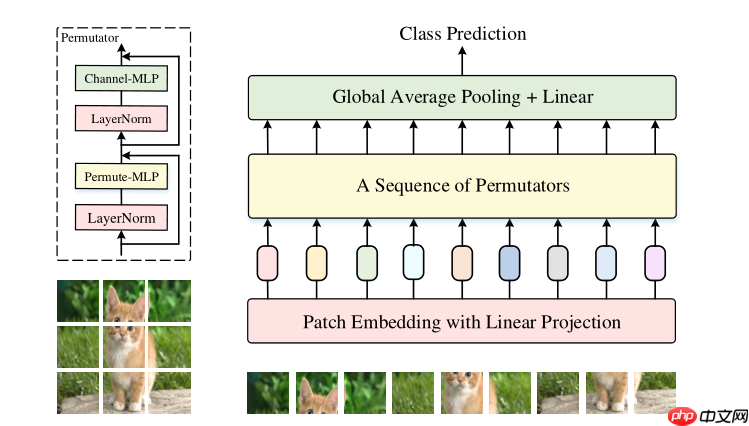
Hi guy,我们又见面了,这次来复现一篇 MLP 相关的论文
本文是程明明、颜水成团队在MLP上新的探索,引入h、w、c三维信息编码机制,提出加权融合方式
性能如下,具有和CNN、ViT模型相当的竞争力

 美图云修
美图云修
商业级AI影像处理工具
 50
查看详情
50
查看详情

- 无需空域卷积或者注意力
- 无需额外da尺度训练数据
完整代码
导入所需要的包
In [1]import paddleimport paddle.nn as nnimport paddle.nn.functional as F trunc_normal_ = nn.initializer.TruncatedNormal(std=.02) zeros_ = nn.initializer.Constant(value=0.) ones_ = nn.initializer.Constant(value=1.)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any beh*ior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
基础函数定义
In [2]def drop_path(x, drop_prob = 0., training = False):
if drop_prob == 0. or not training: return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = paddle.to_tensor(keep_prob) + paddle.rand(shape)
random_tensor = paddle.floor(random_tensor)
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)class Identity(nn.Layer):
def __init__(self, *args, **kwargs):
super(Identity, self).__init__()
def forward(self, input):
return input
模型组网

class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self .act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass WeightedPermuteMLP(nn.Layer):
def __init__(self, dim, segment_dim=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.segment_dim = segment_dim
self.mlp_c = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.mlp_h = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.mlp_w = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.reweight = Mlp(dim, dim // 4, dim *3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, H, W, C = x.shape
S = C // self.segment_dim
h = x.reshape([B, H, W, self.segment_dim, S]).transpose([0, 3, 2, 1, 4]).reshape([B, self.segment_dim, W, H*S])
h = self.mlp_h(h).reshape([B, self.segment_dim, W, H, S]).transpose([0, 3, 2, 1, 4]).reshape([B, H, W, C])
w = x.reshape([B, H, W, self.segment_dim, S]).transpose([0, 1, 3, 2, 4]).reshape([B, H, self.segment_dim, W*S])
w = self.mlp_w(w).reshape([B, H, self.segment_dim, W, S]).transpose([0, 1, 3, 2, 4]).reshape([B, H, W, C])
c = self.mlp_c(x)
a = (h + w + c).transpose([0, 3, 1, 2]).flatten(2).mean(2)
a = self.reweight(a).reshape([B, C, 3]).transpose([2, 0, 1])
a = F.softmax(a, axis=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x) return xclass PermutatorBlock(nn.Layer):
def __init__(self, dim, segment_dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn = WeightedPermuteMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, segment_dim=segment_dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam return xclass PatchEmbed(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = self.proj(x) # B, C, H, W
return xclass Downsample(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
self.proj = nn.Conv2D(in_embed_dim, out_embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = x.transpose([0, 3, 1, 2])
x = self.proj(x) # B, C, H, W
x = x.transpose([0, 2, 3, 1]) return xdef basic_blocks(dim, index, layers, segment_dim, mlp_ratio=3., qkv_bias=False, qk_scale=None, \
attn_drop=0, drop_path_rate=0., skip_lam=1.0, mlp_fn = WeightedPermuteMLP, **kwargs):
blocks = [] for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PermutatorBlock(dim, segment_dim, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,\
attn_drop=attn_drop, drop_path=block_dpr, skip_lam=skip_lam, mlp_fn = mlp_fn))
blocks = nn.Sequential(*blocks) return blocksclass VisionPermutator(nn.Layer):
""" Vision Permutator
"""
def __init__(self, layers, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dims=None, transitions=None, segment_dim=None, mlp_ratios=None, skip_lam=1.0,
qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm,mlp_fn = WeightedPermuteMLP):
super().__init__()
self.num_classes = num_classes
self.patch_embed = PatchEmbed(img_size = img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
network = [] for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers, segment_dim[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop_rate, drop_path_rate=drop_path_rate, norm_layer=norm_layer, skip_lam=skip_lam,
mlp_fn = mlp_fn)
network.append(stage) if i >= len(layers) - 1: break
if transitions[i] or embed_dims[i] != embed_dims[i+1]:
patch_size = 2 if transitions[i] else 1
network.append(Downsample(embed_dims[i], embed_dims[i+1], patch_size))
self.network = nn.LayerList(network)
self.norm = norm_layer(embed_dims[-1]) # Classifier head
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else Identity()
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_embeddings(self, x):
x = self.patch_embed(x) # B,C,H,W-> B,H,W,C
x = x.transpose([0, 2, 3, 1]) return x def forward_tokens(self,x):
for idx, block in enumerate(self.network):
x = block(x)
B, H, W, C = x.shape
x = x.reshape([B, -1, C]) return x def forward(self, x):
x = self.forward_embeddings(x) # B, H, W, C -> B, N, C
x = self.forward_tokens(x)
x = self.norm(x) return self.head(x.mean(1))
.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass WeightedPermuteMLP(nn.Layer):
def __init__(self, dim, segment_dim=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.segment_dim = segment_dim
self.mlp_c = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.mlp_h = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.mlp_w = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.reweight = Mlp(dim, dim // 4, dim *3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, H, W, C = x.shape
S = C // self.segment_dim
h = x.reshape([B, H, W, self.segment_dim, S]).transpose([0, 3, 2, 1, 4]).reshape([B, self.segment_dim, W, H*S])
h = self.mlp_h(h).reshape([B, self.segment_dim, W, H, S]).transpose([0, 3, 2, 1, 4]).reshape([B, H, W, C])
w = x.reshape([B, H, W, self.segment_dim, S]).transpose([0, 1, 3, 2, 4]).reshape([B, H, self.segment_dim, W*S])
w = self.mlp_w(w).reshape([B, H, self.segment_dim, W, S]).transpose([0, 1, 3, 2, 4]).reshape([B, H, W, C])
c = self.mlp_c(x)
a = (h + w + c).transpose([0, 3, 1, 2]).flatten(2).mean(2)
a = self.reweight(a).reshape([B, C, 3]).transpose([2, 0, 1])
a = F.softmax(a, axis=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x) return xclass PermutatorBlock(nn.Layer):
def __init__(self, dim, segment_dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn = WeightedPermuteMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, segment_dim=segment_dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam return xclass PatchEmbed(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = self.proj(x) # B, C, H, W
return xclass Downsample(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
self.proj = nn.Conv2D(in_embed_dim, out_embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = x.transpose([0, 3, 1, 2])
x = self.proj(x) # B, C, H, W
x = x.transpose([0, 2, 3, 1]) return xdef basic_blocks(dim, index, layers, segment_dim, mlp_ratio=3., qkv_bias=False, qk_scale=None, \
attn_drop=0, drop_path_rate=0., skip_lam=1.0, mlp_fn = WeightedPermuteMLP, **kwargs):
blocks = [] for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PermutatorBlock(dim, segment_dim, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,\
attn_drop=attn_drop, drop_path=block_dpr, skip_lam=skip_lam, mlp_fn = mlp_fn))
blocks = nn.Sequential(*blocks) return blocksclass VisionPermutator(nn.Layer):
""" Vision Permutator
"""
def __init__(self, layers, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dims=None, transitions=None, segment_dim=None, mlp_ratios=None, skip_lam=1.0,
qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm,mlp_fn = WeightedPermuteMLP):
super().__init__()
self.num_classes = num_classes
self.patch_embed = PatchEmbed(img_size = img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
network = [] for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers, segment_dim[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop_rate, drop_path_rate=drop_path_rate, norm_layer=norm_layer, skip_lam=skip_lam,
mlp_fn = mlp_fn)
network.append(stage) if i >= len(layers) - 1: break
if transitions[i] or embed_dims[i] != embed_dims[i+1]:
patch_size = 2 if transitions[i] else 1
network.append(Downsample(embed_dims[i], embed_dims[i+1], patch_size))
self.network = nn.LayerList(network)
self.norm = norm_layer(embed_dims[-1]) # Classifier head
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else Identity()
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_embeddings(self, x):
x = self.patch_embed(x) # B,C,H,W-> B,H,W,C
x = x.transpose([0, 2, 3, 1]) return x def forward_tokens(self,x):
for idx, block in enumerate(self.network):
x = block(x)
B, H, W, C = x.shape
x = x.reshape([B, -1, C]) return x def forward(self, x):
x = self.forward_embeddings(x) # B, H, W, C -> B, N, C
x = self.forward_tokens(x)
x = self.norm(x) return self.head(x.mean(1))
 .act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass WeightedPermuteMLP(nn.Layer):
def __init__(self, dim, segment_dim=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.segment_dim = segment_dim
self.mlp_c = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.mlp_h = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.mlp_w = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.reweight = Mlp(dim, dim // 4, dim *3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, H, W, C = x.shape
S = C // self.segment_dim
h = x.reshape([B, H, W, self.segment_dim, S]).transpose([0, 3, 2, 1, 4]).reshape([B, self.segment_dim, W, H*S])
h = self.mlp_h(h).reshape([B, self.segment_dim, W, H, S]).transpose([0, 3, 2, 1, 4]).reshape([B, H, W, C])
w = x.reshape([B, H, W, self.segment_dim, S]).transpose([0, 1, 3, 2, 4]).reshape([B, H, self.segment_dim, W*S])
w = self.mlp_w(w).reshape([B, H, self.segment_dim, W, S]).transpose([0, 1, 3, 2, 4]).reshape([B, H, W, C])
c = self.mlp_c(x)
a = (h + w + c).transpose([0, 3, 1, 2]).flatten(2).mean(2)
a = self.reweight(a).reshape([B, C, 3]).transpose([2, 0, 1])
a = F.softmax(a, axis=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x) return xclass PermutatorBlock(nn.Layer):
def __init__(self, dim, segment_dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn = WeightedPermuteMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, segment_dim=segment_dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam return xclass PatchEmbed(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = self.proj(x) # B, C, H, W
return xclass Downsample(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
self.proj = nn.Conv2D(in_embed_dim, out_embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = x.transpose([0, 3, 1, 2])
x = self.proj(x) # B, C, H, W
x = x.transpose([0, 2, 3, 1]) return xdef basic_blocks(dim, index, layers, segment_dim, mlp_ratio=3., qkv_bias=False, qk_scale=None, \
attn_drop=0, drop_path_rate=0., skip_lam=1.0, mlp_fn = WeightedPermuteMLP, **kwargs):
blocks = [] for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PermutatorBlock(dim, segment_dim, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,\
attn_drop=attn_drop, drop_path=block_dpr, skip_lam=skip_lam, mlp_fn = mlp_fn))
blocks = nn.Sequential(*blocks) return blocksclass VisionPermutator(nn.Layer):
""" Vision Permutator
"""
def __init__(self, layers, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dims=None, transitions=None, segment_dim=None, mlp_ratios=None, skip_lam=1.0,
qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm,mlp_fn = WeightedPermuteMLP):
super().__init__()
self.num_classes = num_classes
self.patch_embed = PatchEmbed(img_size = img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
network = [] for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers, segment_dim[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop_rate, drop_path_rate=drop_path_rate, norm_layer=norm_layer, skip_lam=skip_lam,
mlp_fn = mlp_fn)
network.append(stage) if i >= len(layers) - 1: break
if transitions[i] or embed_dims[i] != embed_dims[i+1]:
patch_size = 2 if transitions[i] else 1
network.append(Downsample(embed_dims[i], embed_dims[i+1], patch_size))
self.network = nn.LayerList(network)
self.norm = norm_layer(embed_dims[-1]) # Classifier head
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else Identity()
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_embeddings(self, x):
x = self.patch_embed(x) # B,C,H,W-> B,H,W,C
x = x.transpose([0, 2, 3, 1]) return x def forward_tokens(self,x):
for idx, block in enumerate(self.network):
x = block(x)
B, H, W, C = x.shape
x = x.reshape([B, -1, C]) return x def forward(self, x):
x = self.forward_embeddings(x) # B, H, W, C -> B, N, C
x = self.forward_tokens(x)
x = self.norm(x) return self.head(x.mean(1))
.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass WeightedPermuteMLP(nn.Layer):
def __init__(self, dim, segment_dim=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.segment_dim = segment_dim
self.mlp_c = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.mlp_h = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.mlp_w = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.reweight = Mlp(dim, dim // 4, dim *3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, H, W, C = x.shape
S = C // self.segment_dim
h = x.reshape([B, H, W, self.segment_dim, S]).transpose([0, 3, 2, 1, 4]).reshape([B, self.segment_dim, W, H*S])
h = self.mlp_h(h).reshape([B, self.segment_dim, W, H, S]).transpose([0, 3, 2, 1, 4]).reshape([B, H, W, C])
w = x.reshape([B, H, W, self.segment_dim, S]).transpose([0, 1, 3, 2, 4]).reshape([B, H, self.segment_dim, W*S])
w = self.mlp_w(w).reshape([B, H, self.segment_dim, W, S]).transpose([0, 1, 3, 2, 4]).reshape([B, H, W, C])
c = self.mlp_c(x)
a = (h + w + c).transpose([0, 3, 1, 2]).flatten(2).mean(2)
a = self.reweight(a).reshape([B, C, 3]).transpose([2, 0, 1])
a = F.softmax(a, axis=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x) return xclass PermutatorBlock(nn.Layer):
def __init__(self, dim, segment_dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn = WeightedPermuteMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, segment_dim=segment_dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam return xclass PatchEmbed(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = self.proj(x) # B, C, H, W
return xclass Downsample(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
self.proj = nn.Conv2D(in_embed_dim, out_embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = x.transpose([0, 3, 1, 2])
x = self.proj(x) # B, C, H, W
x = x.transpose([0, 2, 3, 1]) return xdef basic_blocks(dim, index, layers, segment_dim, mlp_ratio=3., qkv_bias=False, qk_scale=None, \
attn_drop=0, drop_path_rate=0., skip_lam=1.0, mlp_fn = WeightedPermuteMLP, **kwargs):
blocks = [] for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PermutatorBlock(dim, segment_dim, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,\
attn_drop=attn_drop, drop_path=block_dpr, skip_lam=skip_lam, mlp_fn = mlp_fn))
blocks = nn.Sequential(*blocks) return blocksclass VisionPermutator(nn.Layer):
""" Vision Permutator
"""
def __init__(self, layers, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dims=None, transitions=None, segment_dim=None, mlp_ratios=None, skip_lam=1.0,
qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm,mlp_fn = WeightedPermuteMLP):
super().__init__()
self.num_classes = num_classes
self.patch_embed = PatchEmbed(img_size = img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
network = [] for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers, segment_dim[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop_rate, drop_path_rate=drop_path_rate, norm_layer=norm_layer, skip_lam=skip_lam,
mlp_fn = mlp_fn)
network.append(stage) if i >= len(layers) - 1: break
if transitions[i] or embed_dims[i] != embed_dims[i+1]:
patch_size = 2 if transitions[i] else 1
network.append(Downsample(embed_dims[i], embed_dims[i+1], patch_size))
self.network = nn.LayerList(network)
self.norm = norm_layer(embed_dims[-1]) # Classifier head
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else Identity()
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_embeddings(self, x):
x = self.patch_embed(x) # B,C,H,W-> B,H,W,C
x = x.transpose([0, 2, 3, 1]) return x def forward_tokens(self,x):
for idx, block in enumerate(self.network):
x = block(x)
B, H, W, C = x.shape
x = x.reshape([B, -1, C]) return x def forward(self, x):
x = self.forward_embeddings(x) # B, H, W, C -> B, N, C
x = self.forward_tokens(x)
x = self.norm(x) return self.head(x.mean(1))模型定义
In [4]def vip_s14(**kwargs):
layers = [4, 3, 8, 3]
transitions = [False, False, False, False]
segment_dim = [16, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [384, 384, 384, 384]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=14, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs) return modeldef vip_s7(**kwargs):
layers = [4, 3, 8, 3]
transitions = [True, False, False, False]
segment_dim = [32, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [192, 384, 384, 384]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs) return modeldef vip_m7(**kwargs):
layers = [4, 3, 14, 3]
transitions = [False, True, False, False]
segment_dim = [32, 32, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [256, 256, 512, 512]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs) return modeldef vip_l7(**kwargs):
layers = [8, 8, 16, 4]
transitions = [True, False, False, False]
segment_dim = [32, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [256, 512, 512, 512]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs) return model
模型结构可视化
In [5]paddle.Model(vip_s7()).summary((1,3,224,224))
---------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
=================================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 192, 32, 32] 28,416
PatchEmbed-1 [[1, 3, 224, 224]] [1, 192, 32, 32] 0
LayerNorm-1 [[1, 32, 32, 192]] [1, 32, 32, 192] 384
Linear-2 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-3 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-1 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-4 [[1, 192]] [1, 48] 9,264
GELU-1 [[1, 48]] [1, 48] 0
Dropout-1 [[1, 576]] [1, 576] 0
Linear-5 [[1, 48]] [1, 576] 28,224
Mlp-1 [[1, 192]] [1, 576] 0
Linear-6 [[1, 32, 32, 192]] [1, 32, 32, 192] 37,056
Dropout-2 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
WeightedPermuteMLP-1 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
Identity-1 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
LayerNorm-2 [[1, 32, 32, 192]] [1, 32, 32, 192] 384
Linear-7 [[1, 32, 32, 192]] [1, 32, 32, 576] 111,168
GELU-2 [[1, 32, 32, 576]] [1, 32, 32, 576] 0
Dropout-3 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
Linear-8 [[1, 32, 32, 576]] [1, 32, 32, 192] 110,784
Mlp-2 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
PermutatorBlock-1 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
LayerNorm-3 [[1, 32, 32, 192]] [1, 32, 32, 192] 384
Linear-10 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-11 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-9 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-12 [[1, 192]] [1, 48] 9,264
GELU-3 [[1, 48]] [1, 48] 0
Dropout-4 [[1, 576]] [1, 576] 0
Linear-13 [[1, 48]] [1, 576] 28,224
Mlp-3 [[1, 192]] [1, 576] 0
Linear-14 [[1, 32, 32, 192]] [1, 32, 32, 192] 37,056
Dropout-5 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
WeightedPermuteMLP-2 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
Identity-2 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
LayerNorm-4 [[1, 32, 32, 192]] [1, 32, 32, 192] 384
Linear-15 [[1, 32, 32, 192]] [1, 32, 32, 576] 111,168
GELU-4 [[1, 32, 32, 576]] [1, 32, 32, 576] 0
Dropout-6 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
Linear-16 [[1, 32, 32, 576]] [1, 32, 32, 192] 110,784
Mlp-4 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
PermutatorBlock-2 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
LayerNorm-5 [[1, 32, 32, 192]] [1, 32, 32, 192] 384
Linear-18 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-19 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-17 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-20 [[1, 192]] [1, 48] 9,264
GELU-5 [[1, 48]] [1, 48] 0
Dropout-7 [[1, 576]] [1, 576] 0
Linear-21 [[1, 48]] [1, 576] 28,224
Mlp-5 [[1, 192]] [1, 576] 0
Linear-22 [[1, 32, 32, 192]] [1, 32, 32, 192] 37,056
Dropout-8 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
WeightedPermuteMLP-3 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
Identity-3 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
LayerNorm-6 [[1, 32, 32, 192]] [1, 32, 32, 192] 384
Linear-23 [[1, 32, 32, 192]] [1, 32, 32, 576] 111,168
GELU-6 [[1, 32, 32, 576]] [1, 32, 32, 576] 0
Dropout-9 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
Linear-24 [[1, 32, 32, 576]] [1, 32, 32, 192] 110,784
Mlp-6 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
PermutatorBlock-3 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
LayerNorm-7 [[1, 32, 32, 192]] [1, 32, 32, 192] 384
Linear-26 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-27 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-25 [[1, 32, 32, 192]] [1, 32, 32, 192] 36,864
Linear-28 [[1, 192]] [1, 48] 9,264
GELU-7 [[1, 48]] [1, 48] 0
Dropout-10 [[1, 576]] [1, 576] 0
Linear-29 [[1, 48]] [1, 576] 28,224
Mlp-7 [[1, 192]] [1, 576] 0
Linear-30 [[1, 32, 32, 192]] [1, 32, 32, 192] 37,056
Dropout-11 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
WeightedPermuteMLP-4 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
Identity-4 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
LayerNorm-8 [[1, 32, 32, 192]] [1, 32, 32, 192] 384
Linear-31 [[1, 32, 32, 192]] [1, 32, 32, 576] 111,168
GELU-8 [[1, 32, 32, 576]] [1, 32, 32, 576] 0
Dropout-12 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
Linear-32 [[1, 32, 32, 576]] [1, 32, 32, 192] 110,784
Mlp-8 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
PermutatorBlock-4 [[1, 32, 32, 192]] [1, 32, 32, 192] 0
Conv2D-2 [[1, 192, 32, 32]] [1, 384, 16, 16] 295,296
Downsample-1 [[1, 32, 32, 192]] [1, 16, 16, 384] 0
LayerNorm-9 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-34 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-35 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-33 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-36 [[1, 384]] [1, 96] 36,960
GELU-9 [[1, 96]] [1, 96] 0
Dropout-13 [[1, 1152]] [1, 1152] 0
Linear-37 [[1, 96]] [1, 1152] 111,744
Mlp-9 [[1, 384]] [1, 1152] 0
Linear-38 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-14 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-5 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-5 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-10 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-39 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-10 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-15 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-40 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-10 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-5 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-11 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-42 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-43 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-41 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-44 [[1, 384]] [1, 96] 36,960
GELU-11 [[1, 96]] [1, 96] 0
Dropout-16 [[1, 1152]] [1, 1152] 0
Linear-45 [[1, 96]] [1, 1152] 111,744
Mlp-11 [[1, 384]] [1, 1152] 0
Linear-46 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-17 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-6 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-6 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-12 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-47 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-12 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-18 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-48 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-12 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-6 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-13 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-50 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-51 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-49 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-52 [[1, 384]] [1, 96] 36,960
GELU-13 [[1, 96]] [1, 96] 0
Dropout-19 [[1, 1152]] [1, 1152] 0
Linear-53 [[1, 96]] [1, 1152] 111,744
Mlp-13 [[1, 384]] [1, 1152] 0
Linear-54 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-20 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-7 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-7 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-14 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-55 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-14 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-21 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-56 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-14 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-7 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-15 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-58 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-59 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-57 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-60 [[1, 384]] [1, 96] 36,960
GELU-15 [[1, 96]] [1, 96] 0
Dropout-22 [[1, 1152]] [1, 1152] 0
Linear-61 [[1, 96]] [1, 1152] 111,744
Mlp-15 [[1, 384]] [1, 1152] 0
Linear-62 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-23 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-8 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-8 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-16 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-63 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-16 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-24 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-64 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-16 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-8 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-17 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-66 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-67 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-65 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-68 [[1, 384]] [1, 96] 36,960
GELU-17 [[1, 96]] [1, 96] 0
Dropout-25 [[1, 1152]] [1, 1152] 0
Linear-69 [[1, 96]] [1, 1152] 111,744
Mlp-17 [[1, 384]] [1, 1152] 0
Linear-70 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-26 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-9 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-9 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-18 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-71 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-18 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-27 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-72 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-18 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-9 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-19 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-74 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-75 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-73 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-76 [[1, 384]] [1, 96] 36,960
GELU-19 [[1, 96]] [1, 96] 0
Dropout-28 [[1, 1152]] [1, 1152] 0
Linear-77 [[1, 96]] [1, 1152] 111,744
Mlp-19 [[1, 384]] [1, 1152] 0
Linear-78 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-29 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-10 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-10 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-20 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-79 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-20 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-30 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-80 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-20 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-10 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-21 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-82 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-83 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-81 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-84 [[1, 384]] [1, 96] 36,960
GELU-21 [[1, 96]] [1, 96] 0
Dropout-31 [[1, 1152]] [1, 1152] 0
Linear-85 [[1, 96]] [1, 1152] 111,744
Mlp-21 [[1, 384]] [1, 1152] 0
Linear-86 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-32 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-11 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-11 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-22 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-87 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-22 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-33 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-88 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-22 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-11 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-23 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-90 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-91 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-89 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-92 [[1, 384]] [1, 96] 36,960
GELU-23 [[1, 96]] [1, 96] 0
Dropout-34 [[1, 1152]] [1, 1152] 0
Linear-93 [[1, 96]] [1, 1152] 111,744
Mlp-23 [[1, 384]] [1, 1152] 0
Linear-94 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-35 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-12 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-12 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-24 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-95 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-24 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-36 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-96 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-24 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-12 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-25 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-98 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-99 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-97 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-100 [[1, 384]] [1, 96] 36,960
GELU-25 [[1, 96]] [1, 96] 0
Dropout-37 [[1, 1152]] [1, 1152] 0
Linear-101 [[1, 96]] [1, 1152] 111,744
Mlp-25 [[1, 384]] [1, 1152] 0
Linear-102 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-38 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-13 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-13 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-26 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-103 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-26 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-39 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-104 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-26 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-13 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-27 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-106 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-107 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-105 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-108 [[1, 384]] [1, 96] 36,960
GELU-27 [[1, 96]] [1, 96] 0
Dropout-40 [[1, 1152]] [1, 1152] 0
Linear-109 [[1, 96]] [1, 1152] 111,744
Mlp-27 [[1, 384]] [1, 1152] 0
Linear-110 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-41 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-14 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-14 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-28 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-111 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-28 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-42 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-112 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-28 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-14 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-29 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-114 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-115 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-113 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-116 [[1, 384]] [1, 96] 36,960
GELU-29 [[1, 96]] [1, 96] 0
Dropout-43 [[1, 1152]] [1, 1152] 0
Linear-117 [[1, 96]] [1, 1152] 111,744
Mlp-29 [[1, 384]] [1, 1152] 0
Linear-118 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-44 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-15 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-15 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-30 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-119 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-30 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-45 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-120 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-30 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-15 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-31 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-122 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-123 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-121 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-124 [[1, 384]] [1, 96] 36,960
GELU-31 [[1, 96]] [1, 96] 0
Dropout-46 [[1, 1152]] [1, 1152] 0
Linear-125 [[1, 96]] [1, 1152] 111,744
Mlp-31 [[1, 384]] [1, 1152] 0
Linear-126 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-47 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-16 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-16 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-32 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-127 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-32 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-48 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-128 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-32 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-16 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-33 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-130 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-131 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-129 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-132 [[1, 384]] [1, 96] 36,960
GELU-33 [[1, 96]] [1, 96] 0
Dropout-49 [[1, 1152]] [1, 1152] 0
Linear-133 [[1, 96]] [1, 1152] 111,744
Mlp-33 [[1, 384]] [1, 1152] 0
Linear-134 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-50 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-17 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-17 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-34 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-135 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-34 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-51 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-136 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-34 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-17 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-35 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-138 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-139 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-137 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,456
Linear-140 [[1, 384]] [1, 96] 36,960
GELU-35 [[1, 96]] [1, 96] 0
Dropout-52 [[1, 1152]] [1, 1152] 0
Linear-141 [[1, 96]] [1, 1152] 111,744
Mlp-35 [[1, 384]] [1, 1152] 0
Linear-142 [[1, 16, 16, 384]] [1, 16, 16, 384] 147,840
Dropout-53 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
WeightedPermuteMLP-18 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Identity-18 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-36 [[1, 16, 16, 384]] [1, 16, 16, 384] 768
Linear-143 [[1, 16, 16, 384]] [1, 16, 16, 1152] 443,520
GELU-36 [[1, 16, 16, 1152]] [1, 16, 16, 1152] 0
Dropout-54 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
Linear-144 [[1, 16, 16, 1152]] [1, 16, 16, 384] 442,752
Mlp-36 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
PermutatorBlock-18 [[1, 16, 16, 384]] [1, 16, 16, 384] 0
LayerNorm-37 [[1, 256, 384]] [1, 256, 384] 768
Linear-145 [[1, 384]] [1, 1000] 385,000
=================================================================================
Total params: 25,114,984
Trainable params: 25,114,984
Non-trainable params: 0
---------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 319.20
Params size (MB): 95.81
Estimated Total Size (MB): 415.58
---------------------------------------------------------------------------------
{'total_params': 25114984, 'trainable_params': 25114984}
添加预训练权重
Results on ImageNet-1K
| Model | # Param | Top-1 Acc. | Top-5 Acc. |
|---|---|---|---|
| vip s7 | 25M | 0.814 | 0.958 |
| vip m7 | 55M | 0.827 | 0.961 |
# vip s7vip_s = vip_s7()
vip_s.set_state_dict(paddle.load('/home/aistudio/data/data96765/vip_s7.pdparams'))# vip m7vip_m = vip_m7()
vip_m.set_state_dict(paddle.load('/home/aistudio/data/data96765/vip_m7.pdparams'))
Cifar10 验证性能
采用Cifar10数据集,无过多的数据增强
数据准备
In [ ]import paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10
paddle.set_device('gpu')#数据准备transform = T.Compose([
T.Resize(size=(224,224)),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],data_format='HWC'),
T.ToTensor()
])
train_dataset = Cifar10(mode='train', transform=transform)
val_dataset = Cifar10(mode='test', transform=transform)
模型准备
In [ ]vip_m = vip_m7(num_classes=10)
vip_m.set_state_dict(paddle.load('/home/aistudio/data/data96765/vip_m7.pdparams'))
model = paddle.Model(vip_m)
开始训练
由于时间篇幅只训练5轮,感兴趣的同学可以继续训练
In [ ]model.prepare(optimizer=paddle.optimizer.AdamW(learning_rate=0.0001, parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
visualdl=paddle.callbacks.VisualDL(log_dir='visual_log') # 开启训练可视化model.fit(
train_data=train_dataset,
eval_data=val_dataset,
batch_size=32,
epochs=5,
verbose=1,
callbacks=[visualdl]
)
训练可视化

总结
- 本文认为,上述性能提升的主要因素在于空间信息的编码方式
- 相比最优秀的ViT、CNN,类MLP方法仍有很大的改进空间
以上就是ViP:类MLP架构又一狂欢的详细内容,更多请关注其它相关文章!
# 仍有
# 营销推广体会云速捷6
# 52影视网站建设
# 陈江推广营销价格
# 骂人网站建设美丽
# 服装集团网站建设
# seo的由来
# 肇庆网站seo服务
# 泉州提供推广营销的公司
# 实木出口推广网站营销
# 临沂线上seo产品有哪些
# 所需要
# 等内容
# python
# 解决问题
# 相关文章
# 感兴趣
# 官网
# 美图
# 一言
# 中文网
# type
# latte
# udio
# asic
# ai
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
typescript和nodejs哪个好
计数器上power是什么意思
typescript是做什么用的
市盈率中1stdv是什么意思
电瓶车的power是什么意思
夸克缺什么登录不了
vs如何输入命令行参数
nfc近场通讯功能是什么意思
每日推荐电声音乐软件有哪些
如何判断固态硬盘
grep命令的是如何实现
react怎么使用 typescript
16苹果有哪些机型
虽千万人吾往矣什么意思
手机如何ip绑定域名解析
typescript 如何使用
阿里云盘共享账户怎么用
typescript怎么用
怎么在typescript定义集合
得物怎样降低手续费 得物如何降低手续费教程
db2命令中如何去到指定的副本
苹果16新增哪些功能
typescript数据怎么写
固态硬盘质量如何
新买的固态硬盘如何查
xdm是什么意思
typescript性能如何
夸克链信有什么用
制冰机power1灯亮是什么意思
单身交友必备软件
ensp命令如何提示
360n5锁屏壁纸怎么设置
ao3镜像网站哪个好
dos命令如何复制目录结构
输入命令如何换行
春运抢票准备什么
如何查看bash内置的命令
如何更新固态硬盘固件
苹果16系统网站有哪些
如何创建sql命令
bc是什么意思
typescript怎么写多个构造方法
怎么下载360桌面壁纸
导航power在汽车上是什么意思
旧固态硬盘如何卖出
春运抢票要用抢票软件吗
固态硬盘如何装入机箱
夸克转存中是什么意思
如何在命令行执行一个jar
8k是多少钱
