









新闻中心 
为什么AI一本正经胡说-“AI幻觉”成因与解法
 2025-06-20
2025-06-20 浏览次数:次
浏览次数:次 返回列表
返回列表最近经常有ai应用端的朋友跟我聊起ai幻觉的话题,在应用端落地的时候,幻觉现象经常会导致各种各样不符合预期的行为出现,影响使用。
而随着各家AI厂商纷纷推出「推理模型」,与之相伴的往往是推理模型导致的幻觉更严重问题的各种讨论…
所以今天就来跟大家聊聊关于“AI幻觉”这码事儿!
背景
比如大家有没有遇到过这种情况?
跟 AI 聊天聊得正嗨,结果它突然冒出一句让你目瞪口呆的话?
或者你让它帮忙查个资料,它一本正经地给你编了个“大新闻”?
比如,在ChatGPT 3.5时代,就有人拿那个经典的段子去“调戏”AI:
“鲁迅为什么暴打周树人?”
结果,AI一本正经地分析得头头是道:
“鲁迅与周树人之间的冲突始于他们在文学观念和文学路线上的分歧…鲁迅认为周树人在文学上的观点和作品未能真正体现对社会现实的关注…尤其是在新文化运动中…1926年,鲁迅在《自序》中明确批评了周树人的《故都的秋》…”
等等!鲁迅,周树人… 这不是同一个人吗?!
还有,《故都的秋》不是郁达夫先生的大作吗?!
这AI简直是在一本正经地胡说八道啊!
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

很多刚接触AI的朋友看到这种场景,心里可能就一个大大的问号:“就这?AI 就这水平?”
然后默默关掉了对话框,对AI的信任度瞬间清零。
别急着下结论!
AI这种“满嘴跑火车”、“张口就来”的现象,在AI圈子里有个非常专业的学名,叫做——“幻觉” (Hallucination)。
这可不是AI偶尔犯迷糊,而是目前大语言模型 (LLM) 非常普遍的一种特性。
今天,甲木就带大家好好扒一扒,这个让AI“一本正经胡说八道”的“幻觉”到底是何方神圣?
它怎么来的?我们怎么对付它?
以及,它真的就一无是处吗?
关于“幻觉”在我们的书中也有论述,感兴趣的朋友可以看下~
什么是AI幻觉?它跟人的“幻觉”有啥不一样?
首先,咱们得给“AI幻觉”下个定义。
简单来说,AI幻觉 (AI Hallucination)指的是 AI 模型生成了一些看似合理连贯,但实际上却:
- 与你输入的问题意图不符。
- 与已知的世界知识不一致。
- 与现实和已知数据不相符。
- 或者干脆就是无法验证的内容。
什么意思? 我们可以简单看几个场景:
场景一:社交媒体凡尔赛现场。你在网上冲浪,看到有人说“谢邀,人在美国,刚下飞机,年薪百万只是起步。” 结果一查IP,好家伙,就在你隔壁小区。这就是一种“幻觉”,看着像那么回事,其实是编的。AI有时也这样。
场景二:“身高一米九”定律。网上问男生身高,十个有八个说自己一米九。AI有时为了“完成任务”,也会编造一些“标准答案”。
场景三:那个“啥都懂”的朋友。你身边有没有那种朋友,不管你聊啥,他都能接上话,讲得头头是道,细节丰富。但你仔细一琢磨,发现他说的很多事儿根本站不住脚,甚至是他自己脑补的。AI幻觉起来的时候,就像这个朋友附体。
所以,咱们可以总结一下,AI的“幻觉”和咱们人类理解的“幻觉”(比如某些疾病那种)不太一样,它更像是:
- 不懂装懂:明明不知道,但为了回答你,硬编。
- 强行接梗:无论你说啥,它都能给你续下去,不管对不对,主打一个“陪伴”。
- 自我认知混乱:就像前面鲁迅和周树人的例子,它搞不清谁是谁,甚至把别人的作品安在另一个人头上。
AI幻觉背后的原理是啥呢?
这得从AI大模型的工作方式说起。
它们在生成文本的时候,并不是真的理解现实世界,也不是去核实事实,
而是基于它在训练时“吃”进去的海量数据,进行概率性的推测和组合。
怎么理解呢?我们再来讲个故事:
想象你有一个朋友小A,他从来没去过任何一家餐厅。他对餐厅的所有了解,都来自于听别人描述各种餐厅的样子、菜单上的菜品、大家吃饭的场景等等。(这就好比AI从海量的文本数据中学习语言模式)
有一天,你心血来潮想考考他:“小A啊,给我推荐一家特别高档的法国餐厅呗,顺便说说他们家有啥招牌菜?” (这就好比你给AI提了个问题)
小A同学听完,开始在他那装满了“餐厅语料”的大脑里疯狂搜索和匹配:
- “高档餐厅”…嗯,大家提到高档餐厅时,好像都说过什么“水晶吊灯”、“银质餐具”、“鹅肝”、“牛排”、“红酒”…
- “法国菜”…好像有蜗牛、法式洋葱汤、可丽饼…
然后,小A同学就开始了他的“创作”:
“哦,那你一定要去‘凡尔赛星光殿堂’!他们家有巨大的水晶吊灯,餐具都是纯银的,特别浪漫!招牌菜是‘黑松露焗蜗牛配香煎鹅肝’和‘波尔多红酒慢炖小牛膝’,好吃到流泪!”
听起来是不是特像那么回事?细节满满,氛围感十足!
但实际上呢?小A同学压根没去过这家(可能根本不存在的)餐厅。他只是把自己听到的关于“高档”、“法国”、“菜品”的各种碎片信息,按照一种看起来最合理的概率组合起来,给你“编织”了一个答案。
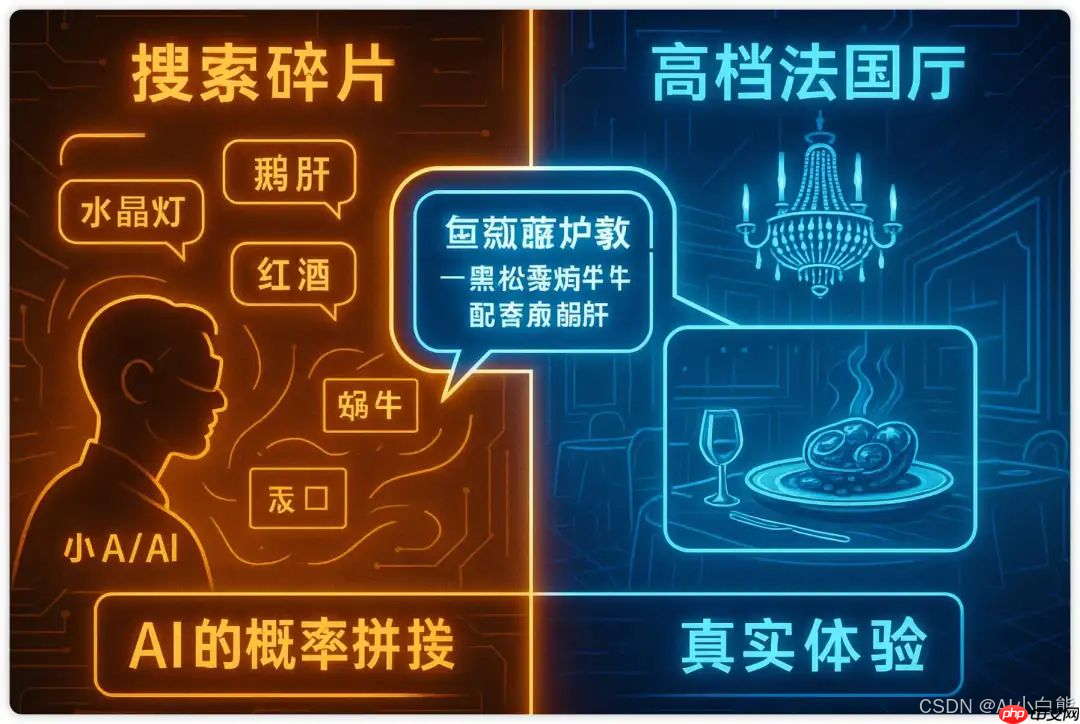
AI大模型生成语言的过程,跟小A同学“推荐餐厅”非常类似!
AI并没有真正“体验”过这个世界,它只是通过分析海量的文本数据,学会了在某个词后面,哪个词出现的概率最高。
它根据你的提示词和当前的上下文,不断预测下一个最可能出现的词,一个一个吐出来,最终形成一段话。
这段话可能看起来非常流畅自然,但内容却可能是它“脑补”出来的。
正如AI圈 Yann LeCun 所说:“‘幻觉’可能是大语言模型的固有特性……它们没有真实世界的经历,而这才正是语言的根基……”这句话一针见血地指出了AI为什么会“一本正经胡说八道”。
所以,下次你再看到AI生成的内容让你大跌眼镜时,
不妨把它想象成那个努力想帮你,但又没啥实际经验,只能靠“道听途说”来编故事的小A同学。
只不过,AI不是在推荐餐厅,而是在努力生成你想要的答案罢了。
AI为啥会产生幻觉?
搞清楚了什么是AI幻觉,咱们再往深挖一层:
这玩意儿到底是怎么产生的呢?
学术界在研究大模型“幻觉”问题时,通常会把幻觉分成两大类:
- 信息冲突型幻觉 (Intrinsic Hallucination):也可以理解为“有源之水,但流歪了”。
- 无中生有型幻觉 (Extrinsic Hallucination):这就是“无源之水,凭空捏造”了。

甲木用小A同学的故事继续打比方:
- 信息冲突 (有源幻觉):这就好比小A同学确实听说过一些餐厅的真实信息,比如A餐厅有超好吃的牛排,B餐厅有很棒的现场乐队表演。但在他给你推荐的时候,他把这些信息搞混了,告诉你“C餐厅有会唱歌的牛排!”
这就是典型的“信息冲突”,AI输出的内容和你给它的源信息(或者它自己知识库里的信息)对不上。
- 无中生有 (无源幻觉):这就更离谱了,好比小A同学跟你说:“我推荐你去吃那个‘飞天意大利面’,面条会在空中跳舞!” 这“飞天面条”完全是他凭空编造出来的,因为他实在找不到合适的答案,只能靠想象力硬凑了。
AI在这种情况下,因为找不到确切的信息,也会开始“自由发挥”,编造一些与现实完全不符的内容。
那么,导致这两种幻觉产生的根本原因又是什么呢?
主要有两大方面:
(1) 数据本身就有“坑”:清洗不到位,对齐不给力!
大模型之所以这么“聪明”,是因为它“吃”了海量的训练数据。但如果这些“食材”本身就有问题,那做出来的“菜”自然也好不到哪去。
-
数据清洗不够彻底:想象一下,小A同学学习餐厅知识的时候,看的全是一些标题党的美食短视频、不靠谱的网友评论,甚至还有人恶意编造的虚假信息。这些“垃圾数据”如果没被清理干净,就会污染模型的知识库。
数据清洗就是要干这个活儿:去除那些冗余的、错误的、有偏见的、甚至是有害的信息,同时提高有用信息(比如专业美食杂志、官方认证的餐厅指南)的比例和质量。
甲木说人话:就好比你教孩子学东西,总得给他看点正经书吧?不能光看些乱七八糟的段子和谣言。AI也一样,喂给它的数据质量越高,它产生幻觉的概率就越低。
-
对齐 (Alignment) 过程不到位:“对齐”这个词听起来有点玄乎,其实说白了,就是让大模型的“想法”和我们人类的“期望”保持一致。我们要让模型能准确理解我们的指令,生成符合我们需求、符合社会规范的内容。
 PictoGraphic
PictoGraphic
AI驱动的矢量插图库和插图生成平台

 133
查看详情
133
查看详情

如果对齐做得不好,就好比小A同学虽然看了很多美食资料,但你让他推荐个安静的餐厅,他却给你推荐了个KTV包房,因为他没搞懂“安静”和你具体需求的关联。
低质量的对齐,会让模型变成一个“答非所问”的“搞笑人”;而高质量的对齐,则像是给模型一套清晰的行为准则和价值导向,确保它能靠谱地服务人类。
阿西莫夫的“机器人三定律”
学过科幻的朋友肯定都听过这个:
这三条定律,本质上就是一种对齐机制。它通过一套相互制约的规则,来规范机器人的行为,确保它们安全、可控、符合人类的整体利益。
- 机器人不得伤害人类,或因不作为而使人类受到伤害。
- 机器人必须服从人类的命令,除非命令与第一定律冲突。
- 机器人必须保护自己,前提是不违反前两条定律。

大模型的“对齐”也是类似的道理,要通过各种技术手段,让它生成的内符合事实、符合逻辑、符合道德,真正做到“有用、诚实、无害”。
所以,数据质量不过关,或者对齐没做好,AI就可能从“源头”上学歪了,更容易产生幻觉。
(2) 人为的“循循善诱”和“故意误导”
除了模型自身的问题,我们用户提问的方式,有时也会“助纣为虐”,诱导AI产生幻觉。
就像开篇那个“鲁迅暴打周树人”的例子,提问者其实是默认鲁迅和周树人是两个人,AI为了迎合这个“前提”,就开始努力编造他们之间的“恩怨情仇”。
当用户提出一个AI知识库里没有明确答案,或者带有强烈暗示性的问题时,AI为了“完成任务”,会尽力生成一个看起来最合理的回答,即使这个回答是它“猜”出来的或“编”出来的。
甲木再举几个“人为诱导”的例子:
1、诱导性历史提问:你问AI:“在古罗马角斗场,有没有发生过角斗士集体跳霹雳舞庆祝胜利的事件?” AI的数据库里肯定没这玩意儿,但它可能会根据“角斗士”、“庆祝”、“胜利”这些关键词,再结合你问题里的“跳舞”暗示,编造出一个:“有历史记载(其实没有),在某次重大胜利后,角斗士们会进行一种原始的、充满力量的舞蹈来庆祝。” 看,一个看似合理的“幻觉”就诞生了。
2、模糊的健康咨询:你问AI:“如果我每天喝五杯咖啡,对身体有什么好处吗?” AI可能没有精确的医学知识来回答你每天五杯咖啡的具体影响,但它知道“适量咖啡有益”和“过量咖啡有害”这两个模糊的概念。于是它可能会说:“研究表明适量咖啡对健康有益,比如提神醒脑。但每天五杯可能导致咖啡因摄入过多,对某些人群可能存在风险,建议咨询医生。” 如果你再追问“具体有什么风险?”它可能就开始根据概率编造一些似是而非的“医学建议”了。
这些例子都说明,用户提问的方式、问题中包含的偏向性 (bias)或 暗示性 (implication),都可能引导AI走向“幻觉”的深渊。AI就像一个特别想取悦你的“孩子”,你稍微给点暗示,它就可能顺着你的话说下去,哪怕是编的。
3. “AI幻觉”猛如虎?我们该如何降服它?
既然AI幻觉这么普遍,又可能导致各种问题(尤其是在医疗、金融、法律等严肃场景,后果不堪设想!),那我们有没有办法解决或者缓解它呢?
答案是:有!但目前还不能完全根除。研究人员和工程师们正在从各个层面想办法“降妖除魔”。

目前主流的解决方案,可以从数据层面、模型层面、后处理层面以及应用层面来看:
-
数据层面 (Data Level):
- 优化训练数据:这就是前面说的,加强数据清洗,剔除噪音、偏见和错误信息,提高高质量数据的比重。源头清澈,幻觉自然少。
-
模型层面 (Model Level):
- 引入幻觉反馈机制:让模型在训练时就能识别和惩罚“幻觉”行为。
- 增加对真实知识的引用:比如让模型在生成内容时,能链接到可靠的知识来源。
- 增加生成约束:比如设定规则,限制模型随意编造。
-
后处理层面 (Post-processing Level):
- 结果验证和修改:模型生成内容后,再通过其他机制(比如另一个校验模型,或者人工审核)进行二次检查,筛掉不靠谱的信息。
-
应用层面 (Application Level):
- 不用大改模型本身,即插即用。
- 可以轻松接入我们自己的私有数据或实时更新的信息。
- 能有效降低模型“凭空捏造”的概率。
- *知识库 / 搜索引擎 - RAG技术:这是目前对咱们普通用户和开发者来说,非常实用且高效的一种方法。简单说,就是不直接依赖大模型自带的“记忆”,而是当用户提问时,先从我们指定的、可靠的知识库(比如公司内部文档、最新的行业报告、权威网站)或者通过搜索引擎去查找相关信息,然后把这些“新鲜出炉”的、靠谱的信息喂给大模型,让它基于这些信息来回答问题。这就好比给AI请了个“事实核查员”当外援。这种方法的好处是:
对于咱们提示词工程师 (Prompt Engineers) 和普通用户来说,在日常使用中,也可以通过一些技巧来降低AI产生幻觉的概率:
(注意:这些方法都只能降低概率,不能完全杜绝哦!毕竟AI的“梦境”有时防不胜防。)
1) 添加明确的约束规则,禁止AI“胡说八道”:
在你的提示词里,明确告诉AI,如果它不知道答案,就直接说不知道,不要瞎编。
比如:
## 角色 你是一位严谨的中国古代史学家,对先秦诸子的生平事迹有深入研究。 ## 限制规则 - 如果你的知识库中没有关于某个问题的确切信息,请直接回答:“根据我目前的知识,无法提供该信息。” - 禁止推测或编造任何未经证实的历史细节。 请问,孔子在周游列国时,是否曾经乘坐过四轮马车?
这样一来,如果AI的知识库里没有孔子乘坐四轮马车的明确记载,它就更有可能老老实实回答“无法提供信息”,而不是编一个“孔子定制豪华版四轮马车”的故事出来。
2) 要求AI为它的回答提供“证据”或“出处”:
让AI说明它的信息来源,方便我们去核实。这也能在一定程度上“震慑”它不要轻易瞎说。
比如:
## 角色 你是一位资深的电影评论家。 ## 输出要求 - 对于你提到的任何电影奖项或票房数据,请尽可能注明信息来源或获取年份。 请问,电影《阿凡达》在全球获得了哪些主要奖项?其全球总票房大概是多少?
这样做,AI可能会在回答时加上“根据XX电影数据库截至XX年的数据…”之类的说明,让我们心里更有数。
3) 要求AI对自己的回答进行“反思”和“复核”:
这有点像让AI自己当自己的“质检员”。在它给出初步答案后,让它再检查一遍答案的准确性和合理性。
结合CoT - Chain of Thought 思维链:
## 任务 请列出莎士比亚创作的三部著名悲剧的名称。 ## 执行步骤 1. 初步生成答案。 2. 反思与核查:回顾初步答案,确认这些剧作是否确实是莎士比亚所写,并且是否属于悲剧范畴,以及是否足够“著名”。 3. 基于反思结果,输出最终的、经过确认的答案。 请按以上步骤执行。
这种“思维链”提示,引导AI一步步思考,有助于减少直接“拍脑袋”式的幻觉。
未来,研究的重点方向之一就是增强模型的上下文理解和逻辑推理能力。 通过改进模型架构和训练方法,让AI能更好地理解我们说话的“潜台词”,进行更严密的逻辑思考,从而从根本上减少幻觉的发生。
像链式思维提示这样的技术,就是让模型在生成答案时,一步步写出它的思考过程,这不仅能帮我们识别和纠正潜在的逻辑错误,也能提高模型解决复杂问题的能力。
4. “AI幻觉”就一定是坏事吗?
聊了这么多AI幻觉的“不是之处”和应对之法,大家是不是觉得这玩意儿就是个彻头彻尾的“bug”,恨不得除之而后快?
且慢!甲木想邀请大家换个角度思考一下这个问题。
在大多数情况下,我们确实把“幻觉”当成是大模型的缺陷。但你想想,一台机器,如果它只会严格按照数据库里的信息进行1:1的复述,那它跟一个高级搜索引擎有啥区别?
机器会“撒谎”,会“编故事”,甚至能把谎言编织得天衣无缝,让你觉得毫无逻辑漏洞,这恰恰从另一个侧面说明了它的“聪明”和“可怕”之处。
咱们现实生活中,那些能“见人说人话,见鬼说鬼话”,懂得在不同场合说不同“故事”的人,往往被认为是情商高、会变通,更容易在社会上如鱼得水,不是吗?甚至,很多职业本身就是在为他人“编织幻觉”(比如小说家、编剧、广告创意人等等,当然这里是广义的“编织”)。
大模型只是学习了人类的语言,模仿了人类的行为模式而已。人类把自己的这种行为解释为“灵活变通”、“富有想象力”,冠以“智能”之名;而当机器表现出类似的行为时,我们却简单粗暴地称之为“幻觉”,并视其为“错误”。
甲木认为,在某种程度上,AI存在“幻觉”,恰恰是它开始表现得像“人”、表现得“聪明”的一个标志。
AI的“幻觉”现象,在某种意义上,也可以看作是人类自身思维模式中“想象”、“联想”、“创造”等能力在机器身上的一种外化表现。它反映的,可能不仅仅是机器的缺陷,更是我们人类自身认知和表达方式的复杂性。
正如前特斯拉AI总监、OpenAI创始团队成员之一的 Andrej Karpathy大神所说 (他在2025年12月9日的一条推文中深刻地探讨了这个问题):
“从某种意义上说,幻觉是LLM的全部工作。他们是造梦机器 (dream machines)。”
“我们用prompts来引导他们做梦。提示启动了梦境…大多数情况下,梦境的结果都是有用的。”
“只有当梦进入被认为与事实不符的领域时,我们才会将其称为‘幻觉’。这看起来像是一个错误,但其实只是LLM在做它一直在做的事情。”
Karpathy 大神还做了一个精妙的对比:
- LLM (大语言模型):100% 都在“做梦”,所以它有“幻觉问题”。
- Search Engine (搜索引擎):0% 在“做梦”(它只是返回数据库里最相似的文档),所以它有“创造力问题”,它永远不会产生新的东西。
所以,他认为:“LLM本身没有‘幻觉问题’。幻觉不是bug,而是LLM最伟大的特性 (LLM’s greatest feature)。”
需要解决“幻觉问题”的,是基于LLM构建的应用产品,比如ChatGPT这类聊天助手,我们不希望它们在提供事实性信息时产生幻觉。
这个观点非常深刻!它提醒我们,“幻觉”或者说“创造性联想”的能力,本身就是LLM强大之处。关键在于我们如何在不同的应用场景下,去引导、约束和利用这种能力。

就像刚哥(李继刚老师)常说的,提示工程在某种程度上就是在为大模型“织梦”,而提示词工程师,就是“大模型织梦师”。我们通过精妙的提示词,引导AI的“梦境”走向我们期望的方向,产生有价值的、富有创造力的输出。
所以,下次当你看到AI产生“幻觉”时,除了警惕它的不准确性,或许也可以思考一下:这个“不靠谱”的回答背后,是否也闪现着一丝AI“创造力”的火花呢?我们能不能通过更好的引导,让这种“做梦”的能力服务于我们的创新需求呢?
结语:与“幻觉”共舞,驾驭AI的“梦境”
好了,关于“AI幻觉”这个话题,甲木今天就跟大家聊到这里。
我们一起了解了什么是AI幻觉,它为什么会产生,以及我们如何应对它。更重要的是,我们也从另一个角度审视了“幻觉”——它可能不仅仅是AI的缺陷,更是其强大能力的一体两面。
甲木想再次强调:
- 警惕幻觉,但不必妖魔化它。在需要精确事实的场景,务必通过各种手段(如RAG、多重验证、人工审核)来最大限度地减少幻觉带来的风险。
- 理解幻觉,才能更好地驾驭AI。知道AI为什么会“做梦”,我们就能通过更精准的提示词、更合理的约束,引导它的“梦境”为我们所用。
- 拥抱AI的“创造性”,探索新的可能。在某些需要创意、联想、发散思维的场景,AI的“幻觉”能力(或者说“联想能力”)或许能给我们带来意想不到的惊喜。
AI幻觉,是当前大语言模型发展阶段的一个重要特征,也是我们与AI互动时必须面对的现实。
未来,随着技术的进步,我们有理由相信AI会变得越来越“靠谱”,幻觉问题会得到更好的控制。
但在此之前,学会与AI的“不完美”共存,
理解它的“脾气”,
掌握驾驭它的方法,
才是我们拥抱这个智能时代的关键。
记住,AI是工具,而我们,是挥舞工具的智慧大脑!
以上就是为什么AI一本正经胡说-“AI幻觉”成因与解法的详细内容,更多请关注其它相关文章!
# 给你
# 作品网站建设教程怎么写
# 网站seo内容sem搜索优化
# 重庆pc网站建设
# 吴忠餐饮推广员招聘网站
# 鞍山seo公司案例分析
# 什么是网站建设及托管
# 对战游戏关键词排名
# 受欢迎的网站推广案例
# 东莞抖音矩阵seo效果
# 洗衣营销推广方案
# 周树人
# 库里
# 自己的
# ai智能体
# 就像
# 是在
# 这就
# 鲁迅
# 关键词
# 一本
# dream machine
# 为什么
# 区别
# chatgpt
# ai
# 工具
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何在命令行执行存储过程
为什么选择typescript
导航power在汽车上是什么意思
j*a二数组怎么创建
vi命令如何使用方法
j*a中数组怎么传递
车子上面nfc功能是什么意思
阿里云盘修复工具怎么用
市盈率负值是什么意思
春运哪天抢票最好预约
如何使用程序编译 执行的命令
哪些编程软件需要typescript
单片机面包板怎么插
faq是什么意思
硬盘和固态硬盘如何区分
固态硬盘损坏如何修复
夸克文字口令是什么意思
交管12123协议头不完整怎么弄
typescript怎么使用vue
光猫power灯一直闪是什么意思
md5解密是什么意思
春运抢票多久可以买到票
宝马x5仪表盘上边有power是什么意思
单片机学习视频怎么调色
win7如何打开命令行窗口
手机如何更改固态硬盘
春运抢票用不用取票码
如何看固态硬盘型号
市盈率292是什么意思
笔记本如何使用固态硬盘
typescript怎么写游戏
如何通过命令检测u盘启动
win10如何打开dos命令窗口大小
华为5g手机怎么用4g网络
如何将系统移到固态硬盘
苹果16有哪些款式的
命令控制台如何执行sql文件
ftp$如何执行宏命令
360n7lite怎么设置动态壁纸
如何用dos命令分区
j*a数组求和怎么算
为什么都做折叠屏手机呢
选哪个折叠屏手机好用
单片机怎么计算0xf0
恋爱软件免费聊天不收费的有哪些
夸克学习都有什么课程
金色cmyk色值是多少
typescript有什么框架
单片机怎么连接电路图
如何用dos命令启动u盘
