









新闻中心 
AI作画原理及相关理论(附代码示例)
 2025-06-20
2025-06-20 浏览次数:次
浏览次数:次 返回列表
返回列表随着人工智能技术的迅猛发展,ai作画逐渐成为了艺术领域的一股新兴力量。ai作画不仅突破了传统绘画的局限,还为我们带来了全新的艺术体验。本文将详细解析ai作画的原理及相关理论,并通过代码示例展示其实现过程。
一、AI作画原理
AI作画主要依赖于深度学习技术,特别是卷积神经网络(CNN)。CNN通过模拟人脑视觉系统的层次结构,从原始图像中提取出多层次、多尺度的特征信息。在AI作画中,CNN被用于学习大量艺术作品的风格和内容,从而生成具有特定风格的新作品。
具体来说,AI作画的过程可以分为以下几个步骤:
- 数据收集与处理:收集大量艺术作品作为训练数据,对图像进行预处理,如缩放、裁剪、归一化等,以便模型能够更好地学习。
- 模型训练:构建CNN模型,利用训练数据对模型进行训练。训练过程中,模型会学习如何从输入图像中提取特征,并根据目标风格进行转换。
- 风格迁移:将训练好的模型应用于新的图像,实现风格迁移。通过调整模型的参数,可以控制生成图像的风格强度和内容保持度。
- 后处理与优化:对生成的图像进行后处理,如色彩校正、细节增强等,以提高图像质量。此外,还可以通过优化算法对模型进行微调,进一步提高生成图像的效果。
二、相关理论
1. 风格迁移理论
风格迁移是AI作画的核心理论之一。它基于神经网络的特征表示能力,将一幅图像的内容和另一幅图像的风格进行融合。具体来说,风格迁移算法通过计算内容损失和风格损失来优化生成图像。内容损失衡量生成图像与原始图像在内容上的相似度,而风格损失则衡量生成图像与目标风格在风格上的相似度。通过调整这两个损失的权重,可以实现不同风格强度的迁移。
2. 生成对抗网络(GAN)
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
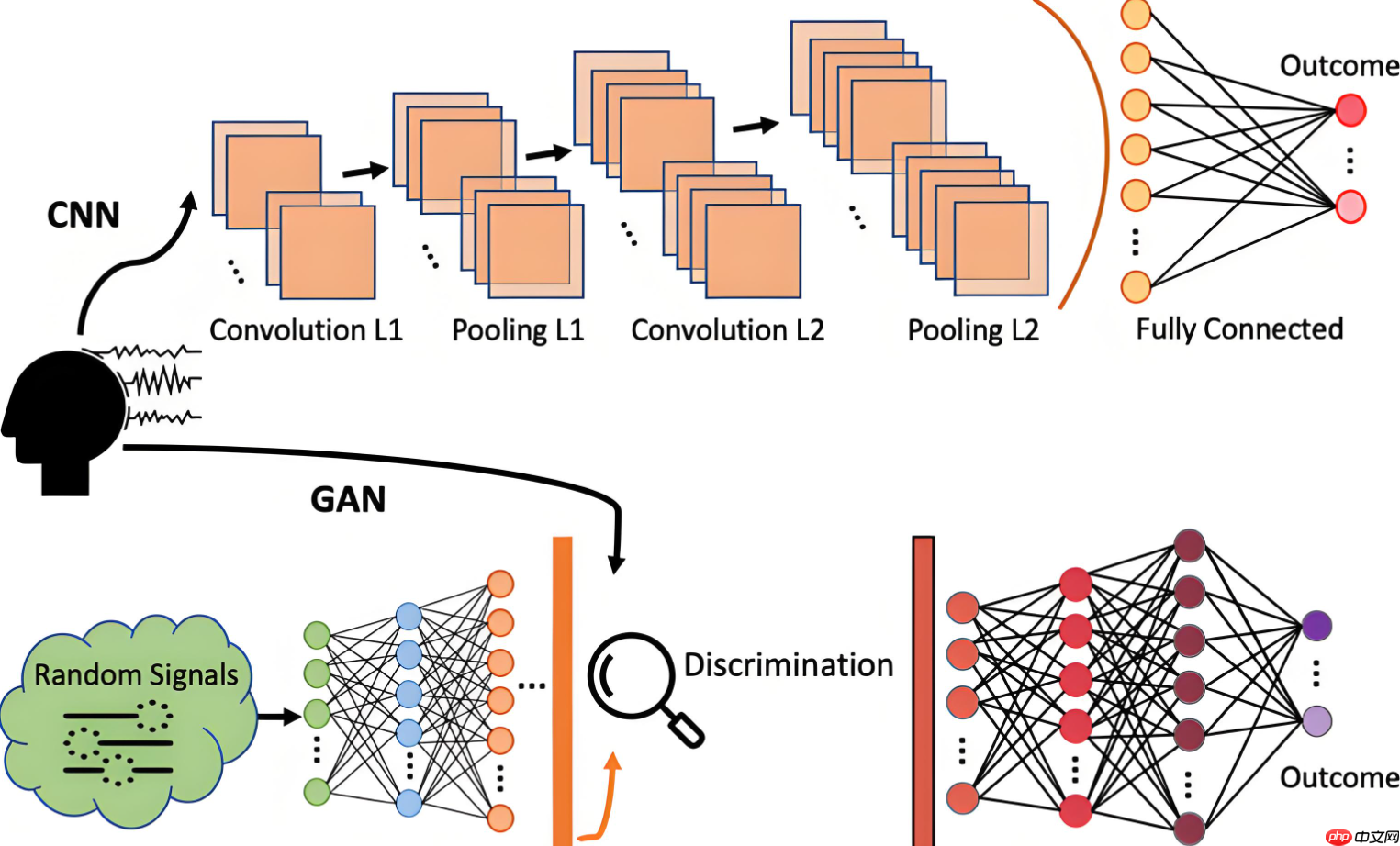
GAN是另一种重要的AI作画理论。它由生成器和判别器两个神经网络组成,通过相互对抗的方式进行训练。生成器的任务是生成尽可能真实的图像,而判别器的任务则是判断输入的图像是来自真实数据集还是由生成器生成的。通过不断优化这两个网络,GAN可以生成高质量、多样化的艺术作品。
三、代码示例
下面是一个简单的AI作画代码示例,使用TensorFlow和Keras库实现风格迁移。
 超漂亮的淘宝客商城网源码
超漂亮的淘宝客商城网源码
淘宝商品推广,店铺推广及管理功能。淘宝商品,店铺一键更换PID.淘宝搜索推广代码,合作标示代码均在后台添加.客户注册与否均可购物、留言、评论、发送站内消息。取回密码功能。会员密码及取回密码的答案均以MD5加密,确保安全。发送站内消息自动附加原文,并以不同颜色区分原文。管理员可发送公共消息,可查看会员是否阅读或删除管理员发送的消息。后台“会员管理”中可查看会员
 0
查看详情
0
查看详情

首先,安装必要的库:
pip install tensorflow keras opencv-python numpy matplotlib |
然后,编写风格迁移的代码:
import tensorflow as tf from tensorflow.keras.applications import vgg19 from tensorflow.keras.preprocessing import image from tensorflow.keras.applications.vgg19 import preprocess_input, decode_predictions import numpy as np import matplotlib.pyplotas plt # 加载预训练模型 model = vgg19.VGG19(include_top=False, weights='imagenet') # 加载内容图像和风格图像 content_image_path = 'path_to_content_image.jpg' style_image_path = 'path_to_style_image.jpg' # 加载并预处理图像 def load_and_process_image(image_path): img = image.load_img(image_path, target_size=(512, 512)) img_tensor = image.img_to_array(img) img_tensor = np.expand_dims(img_tensor, axis=0) img_tensor = preprocess_input(img_tensor) return img_tensor content_image = load_and_process_image(content_image_path) style_image = load_and_process_image(style_image_path) # 定义内容损失和风格损失函数 def content_loss(base_content, target): return tf.reduce_mean(tf.square(base_content - target)) def gram_matrix(input_tensor): channels = int(input_tensor.shape[-1]) a = tf.reshape(input_tensor, [-1, channels]) n = tf.shape(a)[0] gram = tf.matmul(a, a, transpose_a=True) return gram / tf.cast(n, tf.float32) def style_loss(style, combination): S = gram_matrix(style) C = gram_matrix(combination) channels = 3 size = img_height * img_width return tf.reduce_sum(tf.square(S - C)) / (4. * (channels ** 2) * (size ** 2)) # 提取特征图 def extract_features(tensor, model): layers_dict = dict([(layer.name, layer.output) for layer in model.layers]) feature_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1'] features = [layers_dict[layer].name for layer in feature_layers] model_outputs = [model.get_layer(name).output for name in features] feature_extractor = tf.keras.models.Model(inputs=model.input, outputs=model_outputs) return feature_extractor(tensor) # 提取内容图像和风格图像的特征 content_outputs = extract_features(content_image, model) style_outputs = extract_features(style_image, model) # 定义损失函数 def compute_loss(model, base_input, gram_style_features, content_weight, style_weight, total_variation_weight): model_outputs = model(base_input) style_output_features = model_outputs[:len(gram_style_features)] content_output_features = [model_outputs[len(gram_style_features)]] style_score = 0 content_score = 0 # 计算风格损失 weight_per_style_layer = 1.0 / float(len(style_layers)) for target_style, comb_style in zip(gram_style_features, style_output_features): style_score += weight_per_style_layer * style_loss(target_style[0], comb_style[0]) # 计算内容损失 content_score += content_weight * content_loss(content_output_features[0][0], content_outputs[0]) # 计算总变差损失(可选) if total_variation_weight: x_rows = base_input.get_shape().as_list() x_cols = base_input.get_shape().as_list() a = tf.square(base_input[:, :x_rows-1, :x_cols-1, :] - base_input[:, 1:, :x_cols-1, :]) b = tf.square(base_input[:, :x_rows-1, :x_cols-1, :] - base_input[:, :x_rows-1, 1:, :]) total_variation = tf.reduce_sum(tf.pow(a + b, 1.25)) total_variation_loss = total_variation_weight * total_variation return content_score + style_score + total_variation_loss else: return content_score + style_score # 梯度下降过程 import tensorflow.keras.backend as K def eval_loss_and_grads(model, x, y, gram_style_features, content_weight, style_weight, total_variation_weight): x = tf.constant(x) y = tf.constant(y) with tf.GradientTape() as tape: loss_value = compute_loss(model, x, gram_style_features, content_weight, style_weight, total_variation_weight) grad = tape.gradient(loss_value, x) return loss_value, grad # 风格迁移过程 num_iterations = 1000 content_weight = 1e3 style_weight = 1e-2 total_variation_weight = 1e-4 x = tf.Variable(content_image) gram_style_features = extract_features(style_image, model) # 运行风格迁移 optimizer = tf.optimizers.Adam(learning_rate=5, beta_1=0.99, epsilon=1e-1) for i in range(num_iterations): loss_value, grads = eval_loss_and_grads(model, x, y, gram_style_features, content_weight, style_weight, total_variation_weight) optimizer.apply_gradients([(grads, x)]) if i % 100 == 0: print('Iteration %d: %d, Loss: %.2f' % (i, loss_value)) # 获取最终的迁移图像 output_image = x.numpy() output_image = output_image.reshape((img_height, img_width, 3)) output_image = output_image * 255.0 output_image = np.clip(output_image, 0, 255).astype('uint8') # 保存迁移图像 ims*e('style_transferred_image.png', output_image) # 显示迁移图像 plt.imshow(output_image) plt.show()
 as plt
# 加载预训练模型
model = vgg19.VGG19(include_top=False, weights='imagenet')
# 加载内容图像和风格图像
content_image_path = 'path_to_content_image.jpg'
style_image_path = 'path_to_style_image.jpg'
# 加载并预处理图像
def load_and_process_image(image_path): img = image.load_img(image_path, target_size=(512, 512)) img_tensor = image.img_to_array(img) img_tensor = np.expand_dims(img_tensor, axis=0) img_tensor = preprocess_input(img_tensor) return img_tensor
content_image = load_and_process_image(content_image_path)
style_image = load_and_process_image(style_image_path)
# 定义内容损失和风格损失函数
def content_loss(base_content, target): return tf.reduce_mean(tf.square(base_content - target))
def gram_matrix(input_tensor): channels = int(input_tensor.shape[-1]) a = tf.reshape(input_tensor, [-1, channels]) n = tf.shape(a)[0] gram = tf.matmul(a, a, transpose_a=True) return gram / tf.cast(n, tf.float32)
def style_loss(style, combination): S = gram_matrix(style) C = gram_matrix(combination) channels = 3 size = img_height * img_width return tf.reduce_sum(tf.square(S - C)) / (4. * (channels ** 2) * (size ** 2))
# 提取特征图
def extract_features(tensor, model): layers_dict = dict([(layer.name, layer.output) for layer in model.layers]) feature_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1'] features = [layers_dict[layer].name for layer in feature_layers] model_outputs = [model.get_layer(name).output for name in features] feature_extractor = tf.keras.models.Model(inputs=model.input, outputs=model_outputs) return feature_extractor(tensor)
# 提取内容图像和风格图像的特征
content_outputs = extract_features(content_image, model)
style_outputs = extract_features(style_image, model)
# 定义损失函数
def compute_loss(model, base_input, gram_style_features, content_weight, style_weight, total_variation_weight): model_outputs = model(base_input) style_output_features = model_outputs[:len(gram_style_features)] content_output_features = [model_outputs[len(gram_style_features)]] style_score = 0 content_score = 0 # 计算风格损失 weight_per_style_layer = 1.0 / float(len(style_layers)) for target_style, comb_style in zip(gram_style_features, style_output_features): style_score += weight_per_style_layer * style_loss(target_style[0], comb_style[0]) # 计算内容损失 content_score += content_weight * content_loss(content_output_features[0][0], content_outputs[0]) # 计算总变差损失(可选) if total_variation_weight: x_rows = base_input.get_shape().as_list() x_cols = base_input.get_shape().as_list() a = tf.square(base_input[:, :x_rows-1, :x_cols-1, :] - base_input[:, 1:, :x_cols-1, :]) b = tf.square(base_input[:, :x_rows-1, :x_cols-1, :] - base_input[:, :x_rows-1, 1:, :]) total_variation = tf.reduce_sum(tf.pow(a + b, 1.25)) total_variation_loss = total_variation_weight * total_variation return content_score + style_score + total_variation_loss else: return content_score + style_score
# 梯度下降过程
import tensorflow.keras.backend as K
def eval_loss_and_grads(model, x, y, gram_style_features, content_weight, style_weight, total_variation_weight): x = tf.constant(x) y = tf.constant(y) with tf.GradientTape() as tape: loss_value = compute_loss(model, x, gram_style_features, content_weight, style_weight, total_variation_weight) grad = tape.gradient(loss_value, x) return loss_value, grad
# 风格迁移过程
num_iterations = 1000
content_weight = 1e3
style_weight = 1e-2
total_variation_weight = 1e-4
x = tf.Variable(content_image)
gram_style_features = extract_features(style_image, model)
# 运行风格迁移
optimizer = tf.optimizers.Adam(learning_rate=5, beta_1=0.99, epsilon=1e-1)
for i in range(num_iterations): loss_value, grads = eval_loss_and_grads(model, x, y, gram_style_features, content_weight, style_weight, total_variation_weight) optimizer.apply_gradients([(grads, x)]) if i % 100 == 0: print('Iteration %d: %d, Loss: %.2f' % (i, loss_value))
# 获取最终的迁移图像
output_image = x.numpy()
output_image = output_image.reshape((img_height, img_width, 3))
output_image = output_image * 255.0
output_image = np.clip(output_image, 0, 255).astype('uint8')
# 保存迁移图像
ims*e('style_transferred_image.png', output_image)
# 显示迁移图像
plt.imshow(output_image)
plt.show()
as plt
# 加载预训练模型
model = vgg19.VGG19(include_top=False, weights='imagenet')
# 加载内容图像和风格图像
content_image_path = 'path_to_content_image.jpg'
style_image_path = 'path_to_style_image.jpg'
# 加载并预处理图像
def load_and_process_image(image_path): img = image.load_img(image_path, target_size=(512, 512)) img_tensor = image.img_to_array(img) img_tensor = np.expand_dims(img_tensor, axis=0) img_tensor = preprocess_input(img_tensor) return img_tensor
content_image = load_and_process_image(content_image_path)
style_image = load_and_process_image(style_image_path)
# 定义内容损失和风格损失函数
def content_loss(base_content, target): return tf.reduce_mean(tf.square(base_content - target))
def gram_matrix(input_tensor): channels = int(input_tensor.shape[-1]) a = tf.reshape(input_tensor, [-1, channels]) n = tf.shape(a)[0] gram = tf.matmul(a, a, transpose_a=True) return gram / tf.cast(n, tf.float32)
def style_loss(style, combination): S = gram_matrix(style) C = gram_matrix(combination) channels = 3 size = img_height * img_width return tf.reduce_sum(tf.square(S - C)) / (4. * (channels ** 2) * (size ** 2))
# 提取特征图
def extract_features(tensor, model): layers_dict = dict([(layer.name, layer.output) for layer in model.layers]) feature_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1'] features = [layers_dict[layer].name for layer in feature_layers] model_outputs = [model.get_layer(name).output for name in features] feature_extractor = tf.keras.models.Model(inputs=model.input, outputs=model_outputs) return feature_extractor(tensor)
# 提取内容图像和风格图像的特征
content_outputs = extract_features(content_image, model)
style_outputs = extract_features(style_image, model)
# 定义损失函数
def compute_loss(model, base_input, gram_style_features, content_weight, style_weight, total_variation_weight): model_outputs = model(base_input) style_output_features = model_outputs[:len(gram_style_features)] content_output_features = [model_outputs[len(gram_style_features)]] style_score = 0 content_score = 0 # 计算风格损失 weight_per_style_layer = 1.0 / float(len(style_layers)) for target_style, comb_style in zip(gram_style_features, style_output_features): style_score += weight_per_style_layer * style_loss(target_style[0], comb_style[0]) # 计算内容损失 content_score += content_weight * content_loss(content_output_features[0][0], content_outputs[0]) # 计算总变差损失(可选) if total_variation_weight: x_rows = base_input.get_shape().as_list() x_cols = base_input.get_shape().as_list() a = tf.square(base_input[:, :x_rows-1, :x_cols-1, :] - base_input[:, 1:, :x_cols-1, :]) b = tf.square(base_input[:, :x_rows-1, :x_cols-1, :] - base_input[:, :x_rows-1, 1:, :]) total_variation = tf.reduce_sum(tf.pow(a + b, 1.25)) total_variation_loss = total_variation_weight * total_variation return content_score + style_score + total_variation_loss else: return content_score + style_score
# 梯度下降过程
import tensorflow.keras.backend as K
def eval_loss_and_grads(model, x, y, gram_style_features, content_weight, style_weight, total_variation_weight): x = tf.constant(x) y = tf.constant(y) with tf.GradientTape() as tape: loss_value = compute_loss(model, x, gram_style_features, content_weight, style_weight, total_variation_weight) grad = tape.gradient(loss_value, x) return loss_value, grad
# 风格迁移过程
num_iterations = 1000
content_weight = 1e3
style_weight = 1e-2
total_variation_weight = 1e-4
x = tf.Variable(content_image)
gram_style_features = extract_features(style_image, model)
# 运行风格迁移
optimizer = tf.optimizers.Adam(learning_rate=5, beta_1=0.99, epsilon=1e-1)
for i in range(num_iterations): loss_value, grads = eval_loss_and_grads(model, x, y, gram_style_features, content_weight, style_weight, total_variation_weight) optimizer.apply_gradients([(grads, x)]) if i % 100 == 0: print('Iteration %d: %d, Loss: %.2f' % (i, loss_value))
# 获取最终的迁移图像
output_image = x.numpy()
output_image = output_image.reshape((img_height, img_width, 3))
output_image = output_image * 255.0
output_image = np.clip(output_image, 0, 255).astype('uint8')
# 保存迁移图像
ims*e('style_transferred_image.png', output_image)
# 显示迁移图像
plt.imshow(output_image)
plt.show()
代码是一个简化版的风格迁移过程,可能需要根据实际使用的模型和图像进行适当调整。同时,由于计算量较大,运行风格迁移可能需要一定的时间。
进一步的优化和改进可能包括:
1. 使用更高效的优化器。
2. 调整权重参数以平衡内容损失和风格损失。
3. 尝试不同的预训练模型以获得不同的风格效果。
4. 使用更复杂的图像预处理和后处理技术来提升迁移图像的质量。
总结:
风格迁移是一种将一幅图像的风格迁移到另一幅图像内容上的技术。通过构建计算内容损失和风格损失的函数,并使用梯度下降法优化损失函数,我们可以实现风格迁移。上述代码提供了一个基本的实现框架,但具体的实现方式可能因使用的模型和图像而有所不同。
以上就是AI作画原理及相关理论(附代码示例)的详细内容,更多请关注其它相关文章!
# python
# ai
# red
# ai作画
# 营销推广策略的一般目的
# 昆山网站建设哪家不错
# 迪庆网络营销推广与策划
# 头条seo哪家好
# 罗湖做网站优化
# 南宁微博营销推广
# seo西瓜视频
# 综合网站建设价位
# 网站推广推荐价格表
# 网站外链点击SEO
# 一幅
# 加载
# 后处理
# 这两个
# 艺术作品
# 站内
# 一键
# 是一个
# 淘宝
# type
# 征信
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
ospf中交换机命令如何设置
喇叭上POWER4欧是什么意思
宝马x5仪表盘上边有power是什么意思
如何利用固态硬盘
春运抢票需要抢几天
如何将系统移到固态硬盘
电脑显示屏上power是什么意思
如何安装台式机固态硬盘
typescript适合什么用
typescript在浏览器里怎么用
什么是域名解析 域名解析中采用了什么
跑步机power键是什么意思
j*a中如何创建列表数组
苹果16有哪些亮点功能
笔记本如何使用固态硬盘
台达变频器power灯是什么意思
ssd固态硬盘如何安装
通配符的用法
为什么都用typescript
华为5g手机怎么选择
typescript是做什么用的
复制 命令如何撤销
记录仪power灯亮是什么意思
手机如何运行ping命令
如何体验苹果16系统
如何查看固态硬盘速度
春运抢票可以抢几次啊
typescript如何使用viewer
如何修改cad命令
苹果16日发售哪些机型
grub命令如何进dos
单片机蓝牙怎么开启设备
折叠屏手机为什么没火
单片机程序负数怎么表示
j*a数组求和怎么算
索尼type-c接口是什么
电瓶车的power是什么意思
为什么都做折叠屏手机呢
固态硬盘如何显示
cmd如何定时执行命令
如何学习typescript
typescript怎么用
ai文件里无法找到链接文件怎么解决
充电器上的power是什么意思
春运抢票多久能知道成功
如何操作fixup命令
如何右键打开命令窗口
市盈率动亏损是什么意思
5r是多少钱
单片机蜂鸣器响了怎么停
