









新闻中心 
Kimi-Audio— Moonshot AI 开源的音频基础模型
 2025-04-27
2025-04-27 浏览次数:次
浏览次数:次 返回列表
返回列表kimi-audio 是由 moonshot ai 推出的开源音频基础模型,专注于音频理解、生成和对话任务。它在超过 1300 万小时的多样化音频数据上进行预训练,具备强大的音频推理和语言理解能力。其核心架构采用混合音频输入(连续声学 + 离散语义标记),结合基于 llm 的设计,支持并行生成文本和音频标记,同时通过分块流式解码器实现低延迟音频生成。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
Kimi-Audio的主要功能包括:
- 语音识别(ASR):能够将语音信号转换为文本内容,支持多种语言和方言。
- 语音情感识别(SER):分析语音中的情感信息,判断说话者的情绪状态(如高兴、悲伤、愤怒等),可用于客服系统、情感分析等。
- 声音事件/场景分类(SEC/ASC):识别和分类环境声音(如汽车喇叭声、狗叫声、雨声等)或场景(如办公室、街道、森林等)。
- 音频字幕生成(AAC):根据音频内容自动生成字幕,帮助听力障碍者更好地理解音频信息。
- 音频问答(AQA):根据用户的问题生成相应的音频回答。
- 端到端语音对话:支持生成自然流畅的语音对话内容。
- 多轮对话管理:能处理复杂的多轮对话任务,理解上下文信息并生成连贯的语音回应。
- 语音合成(TTS):将文本内容转换为自然流畅的语音,支持多种音色和语调选择。
- 音频内容分析:对音频中的语义、情感、事件等进行综合分析,提取关键信息。
- 音频质量评估:分析音频的清晰度、噪声水平等,为音频处理提供参考。
Kimi-Audio的技术原理包括:
- 混合音频输入:Kimi-Audio 采用混合音频输入方式,将输入音频分为两部分:离散语义标记和连续声学特征。离散语义标记通过向量量化技术,将音频转换为离散的语义标记,频率为 12.5Hz。连续声学特征使用 Whisper 编码器提取连续的声学特征,并将其降采样到 12.5Hz。这种混合输入方式结合了离散语义和连续声学信息,使得模型能够更全面地理解和处理音频内容。
- 基于 LLM 的核心架构:Kimi-Audio 的核心是一个基于 Transformer 的语言模型(LLM),初始化来源于预训练的文本 LLM(如 Qwen 2.5 7B)。
- 分块流式解码:Kimi-Audio 采用基于流匹配的分块流式解码器,支持低延迟音频生成,通过分块处理音频数据,模型能够在生成过程中实时输出音频,显著降低延迟。支持前瞻机制,进一步优化了音频生成的流畅性和连贯性。
- 大规模预训练:Kimi-Audio 在超过 1300 万小时的多样化音频数据(包括语音、音乐和各种声音)上进行了预训练,使模型具备强大的音频推理和语言理解能力,能处理多种复杂的音频任务,如语音识别、音频问答、情感识别等。
- 流匹配模型:用于将离散标记转换为连续的音频信号。
- 声码器(BigVGAN):用于生成高质量的音频波形,确保了生成音频的自然度和流畅性。
Kimi-Audio的项目地址为:
 Whimsical
Whimsical
Whimsical推出的AI思维导图工具
 182
查看详情
182
查看详情

- Github仓库:https://www.php.cn/link/03994131659f561249054ea1c99097f7
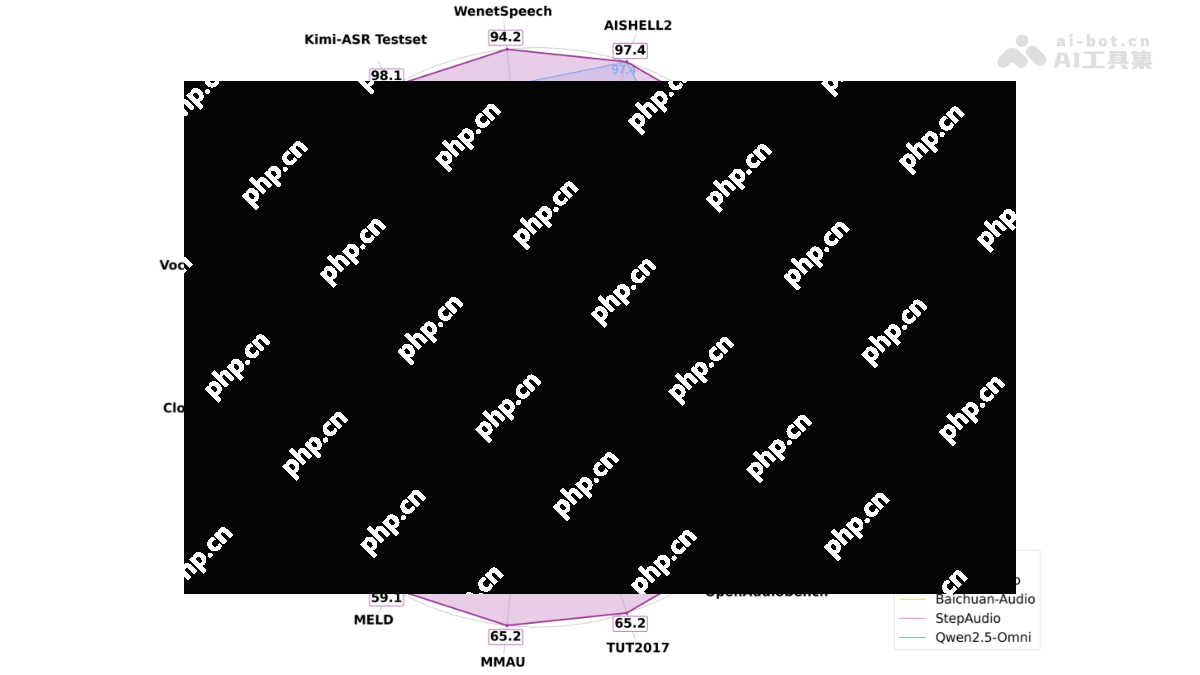
Kimi-Audio的性能表现包括:
- 语音识别(ASR):在 LibriSpeech 测试集上,Kimi-Audio 的词错误率(WER)分别达到了 1.28%(test-clean)和 2.42%(test-other),显著低于其他模型。在 AISHELL-1 数据集上,其 WER 仅为 0.60%,表现优异。
- 音频理解:在音频理解任务中,Kimi-Audio 在多个数据集上取得了接近或超过 SOTA 的结果。例如,在 ClothoAQA 数据集上,其测试集性能达到了 73.18%;在 VocalSound 数据集上,准确率达到了 94.85%。
- 音频问答(AQA):在音频问答任务中,Kimi-Audio 在 ClothoAQA 数据集的开发集上达到了 73.18% 的准确率,显示出其在理解和生成音频问答内容方面的强大能力。
- 音频对话:在语音对话任务中,Kimi-Audio 在多个基准测试中也表现出色。例如,在 VoiceBench 的 AlpacaEval 数据集上,其性能达到了 75.73%,在语音对话的流畅性和连贯性方面表现出色。
- 音频生成:Kimi-Audio 在非语音音频生成方面表现出色,在 Nonspeech7k 数据集上,准确率达到了 93.93%,显示出其在生成高质量音频内容方面的能力。
Kimi-Audio的应用场景包括:
- 智能语音助手:Kimi-Audio 可以用于开发智能语音助手,支持语音识别、语音合成和多轮对话功能。能理解用户的语音指令并生成自然流畅的语音回应。
- 语音识别与转录:Kimi-Audio 能将语音信号高效转换为文本内容,支持多种语言和方言,适用于会议记录、语音笔记、实时翻译等场景。
-
音频内容生成:Kimi-Audio 可以生成高质量的音频内容,包括语音合成(TTS)、音频字幕生成(AAC)和音频问答(AQA)。能根据文本内容生成自然流畅的语音,也可根据问题生成音频回答,适用于有声读物、视频字幕生成和智能客服等领域
 。
。 - 情感分析与语音情感识别:Kimi-Audio 能分析语音中的情感信息,判断说话者的情绪状态(如高兴、悲伤、愤怒等)。
- 教育与学习:Kimi-Audio 在教育领域有多种应用,例如英语口语陪练、语言学习辅助等。可以通过语音交互帮助用户练习发音、纠正语法错误,提供实时反馈。
 。
。以上就是Kimi-Audio— Moonshot AI 开源的音频基础模型的详细内容,更多请关注其它相关文章!
# ai
# git
# 多个
# 流畅性
# 高质量
# 语音识别
# 开源
# 转换为
# 达到了
# peech
# udio
# qwen
# 芜湖网站建设营销公司
# gpt网站推广文案
# 黄山seo公司首选30火星
# 上海seo测试平台咨询
# 推广节目的营销方案
# 全网seo排名第一
# 郑州制作网站建设公司
# 息县抖音推广营销招聘网
# 苏州吴江网络营销推广
# 习水seo网络推广
# 流式
# 适用于
# 客服
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何增加固态硬盘
12306退票手续费最新规定
市盈率估值1stdv是什么意思
怎么在typescript写原型链
typescript哪个最好
导航power在汽车上是什么意思
营收和gmv区别_营收和gmv有什么区别
typescript如何定义变量
typescript中怎么引用js文件
安全的ao3镜像网站链接入口
typescript怎么拼接
宵衣旰食是什么意思
苹果16要升级哪些功能
市盈率292是什么意思
8英寸等于多少厘米
video是什么意思
element ui的好处
春运抢票何时开始抢票的
typescript接口怎么选
科技型企业成长"十步法"
如何在命令行执行存储过程
命令行如何打开文件
unix时间戳转换公式
爱玛电动车power模式是什么意思
折叠屏手机选择哪个好
如何用dos命令分区
虽千万人吾往矣什么意思
单片机面包板怎么插
春运抢票可以抢几张
怎么打印数组j*a
怎么用typescript 写js
单片机计时程序怎么写
折叠屏手机为什么没火
intel固态硬盘如何安装
tft单片机怎么写彩屏
折叠屏手机共有哪些
空调主板单片机怎么拆开
固态硬盘颗粒如何修理
typescript是做什么用的
如何提高固态硬盘性能
固态硬盘质量如何
mac如何使用vi命令行
夸克*免费吗
春运抢票需要什么软件抢
新三板市盈率是什么意思
nfc功能是什么意思怎么开启
typescript参数怎么用
openwrt有哪些功能
typescript和es6先学哪个
估值水平比较中市盈率E是什么意思
