









新闻中心 
大模型全军覆没,中科院自动化所推出多图数学推理新基准
 2025-03-11
2025-03-11 浏览次数:次
浏览次数:次 返回列表
返回列表近日,中国科学院自动化研究所推出多图数学推理全新基准mv-math(该工作已被cvpr 2025录用),这是一个精心策划的多图数学推理数据集,旨在全面评估mllm(多模态大语言模型)在多视觉场景中的数学推理能力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
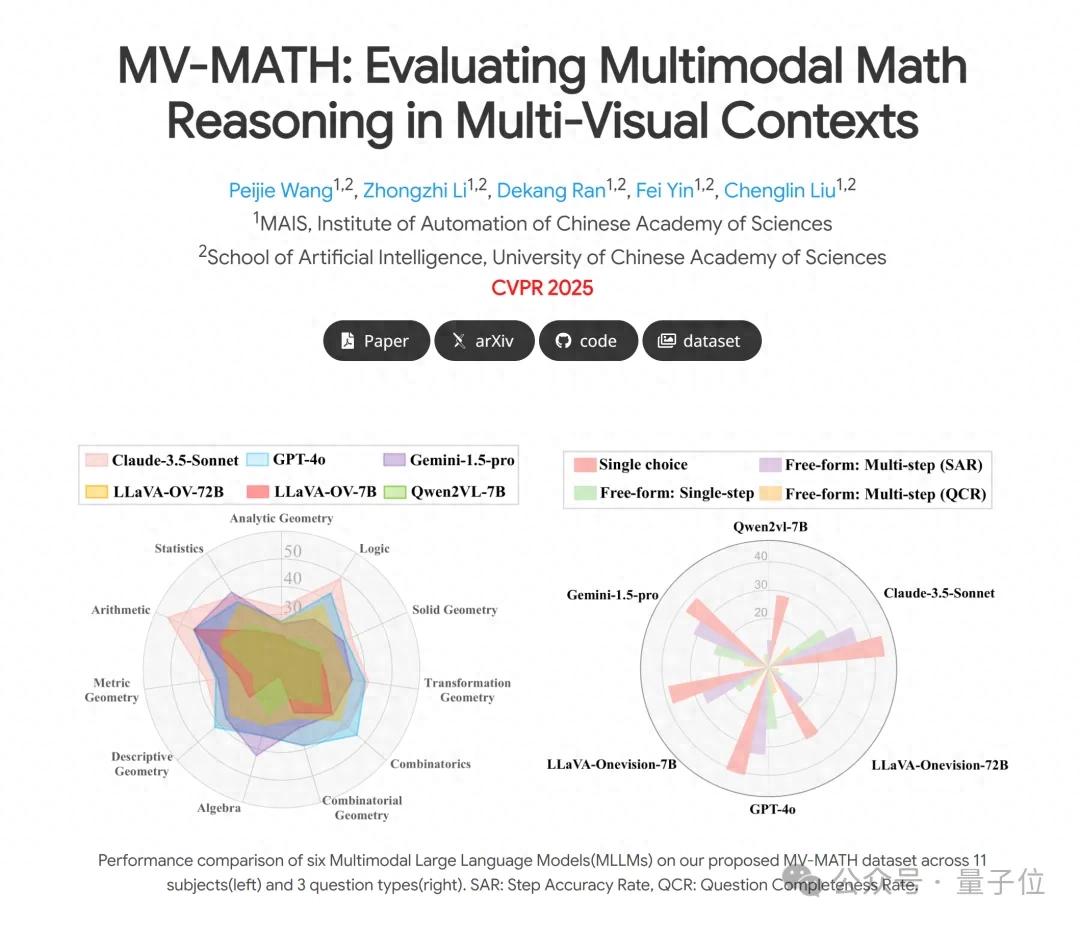
结果评估下来发现,GPT-4o仅得分32.1,类o1模型QvQ得分29.3,所有模型均不及格。
给大模型数学推理上难度
截止目前,多模态大模型在数学推理领域展现出了巨大的潜力。
然而,现有的多模态数学基准测试大多局限于单一视觉场景(单图推理),这与现实世界中复杂的多视觉数学应用(多图推理)相去甚远。
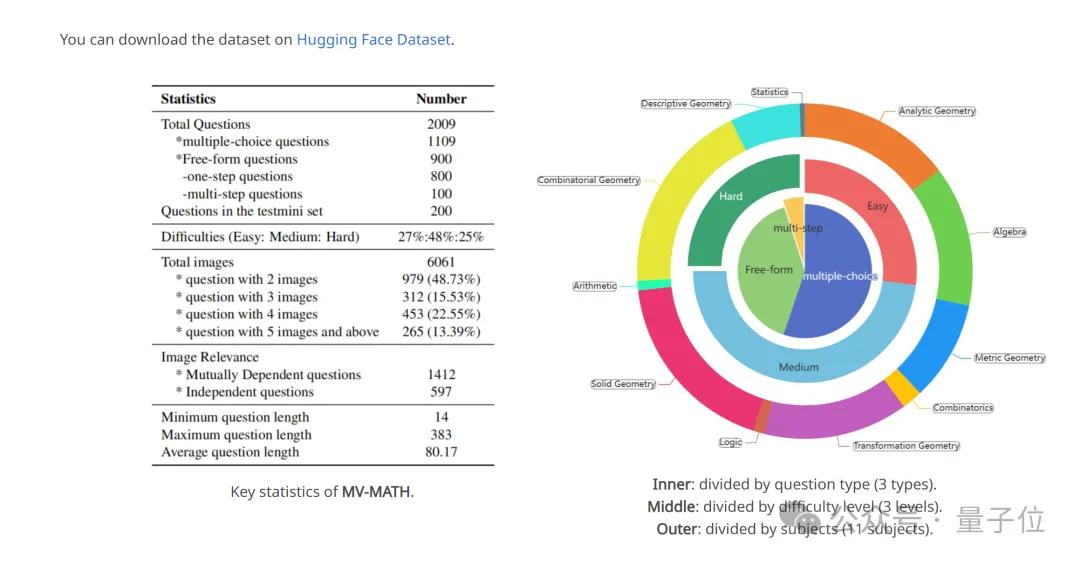
基于这一情况,多图数学推理数据集MV-MATH应运而生。MV-MATH包含2009个高质量数学问题,涵盖了从K-12教育场景中提取的真实问题。
每个问题都结合了多个图像和文本,形成了图文交错的多视觉场景。
这些问题分为选择题、填空题和多步问答题三种类型,覆盖了11个数学领域,包括解析几何、代数、度量几何、组合学、变换几何、逻辑、立体几何、算术、组合几何、描述性几何和统计学,并分为三个难度级别。
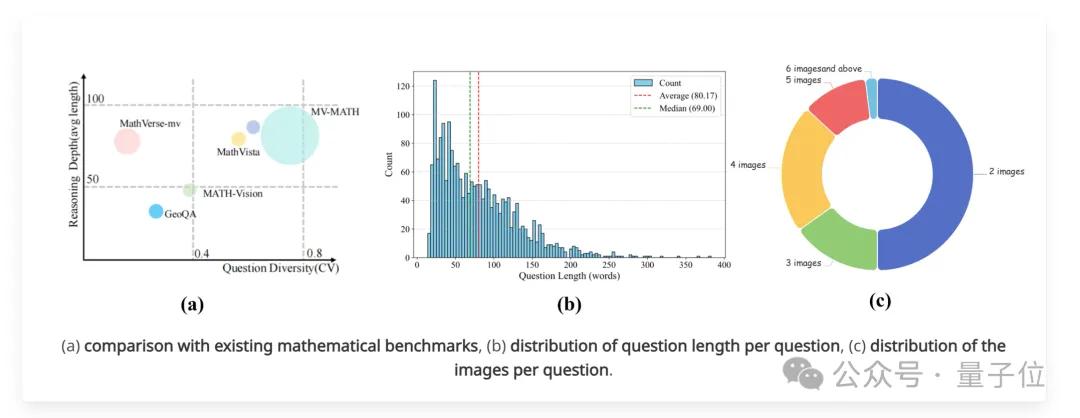
下图展示了MV-MATH与现有数据集的对比以及分布情况:
(a)与现有数学基准的比较(圆圈大小代表图片数量);(b)每个问题的长度分布;(c)每个问题的图像数量分布。
数据集特点
(1)多视觉场景
MV-MATH数据集中的每个问题都包含多个图像(2-8个图片),这些图像与文本交织在一起,形成了复杂的多视觉场景。
MV-MATH中的每个问题都是从真实的K-12场景中收集而来,这种设计更接近于现实世界中的数学问题,能够更好地评估MLLM在处理多视觉信息时的推理能力。
(2)丰富的标注
为了确保数据集的质量和可靠性,每个样本都经过了至少两名标注者的交叉验证。标注内容包括问题、答案、详细分析以及图像关联性,为模型评估提供了详细的信息。
(3)多样化的数学领域
MV-MATH涵盖了从基础算术到高级几何的11个数学领域,并根据详细答案的长度划分为3个难度等级,能够全面评估MLLM在不同数学领域的推理能力。
(4)图像关联性
MV-MATH首次引入图像相关性这一特征标签,根据据图像是否相关,数据集被分为两个子集:相互依赖集(Mutually Dependent Set,MD)和独立集(Independent Set,ID)。
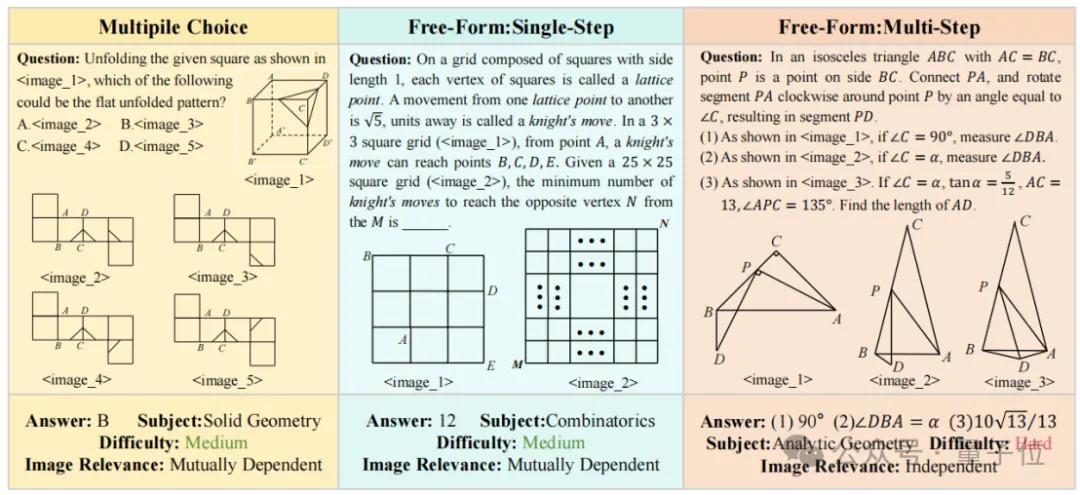
在MD子集中,图像之间相互关联,理解一个图像需要参考其他图像;而在ID子集中,图像之间相互独立,可以单独解释。
例如,下图中前两个题目属于相互依赖集,最后一个为题目属于独立集。
多图推理综合评估
 Zyro AI Background Remover
Zyro AI Background Remover
Zyro推出的AI图片背景移除工具
 145
查看详情
145
查看详情


研究团队在MV-MATH上进行了广泛的实验,评测了24个主流开源和闭源多模态大模型。
实验结果表明,即使是最先进的MLLM在多视觉数学任务中也面临着巨大的挑战,其表现与人类能力之间存在显著差距。
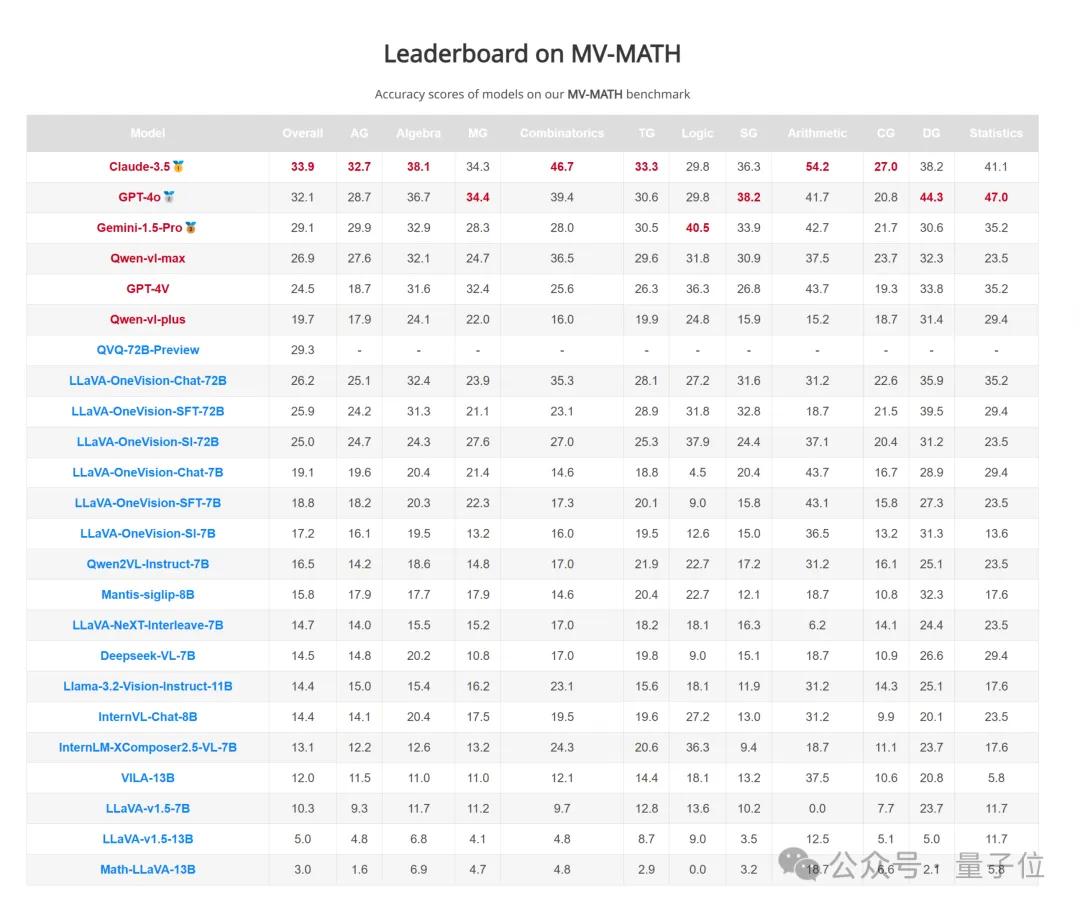
从模型总体表现来看,在MV-MATH数据集上,表现最好的模型是Claude-3.5,其整体准确率为33.9%,远低于人类水平(76.5%)。
其他表现较好的模型还包括GPT-4o(32.1%)、Gemini-1.5-Pro(29.1%)和Qwen-vl-max(26.9%)。
值得注意的是,开源模型LLaVA-OneVision-Chat-72B取得了26.2%的准确率,仅次于Qwen-vl-max。类o1模型QVQ-72B-Preview性能为29.3%,仅次于GPT-4o,这说明慢思考系统在多图推理任务上同样有效。
此外,模型在不同领域的表现也存在差异。
在算术领域,Claude-3.5的准确率最高,达到54.2%;而在组合几何领域,其准确率仅为27.0%。
这表明MLLM在处理需要复杂图像理解和推理的领域时存在较大困难。
与此同时,团队针对题目难度、模型提示、图像关联性以及图像输入方式四个维度对实验结果进行了更细粒度的分析。
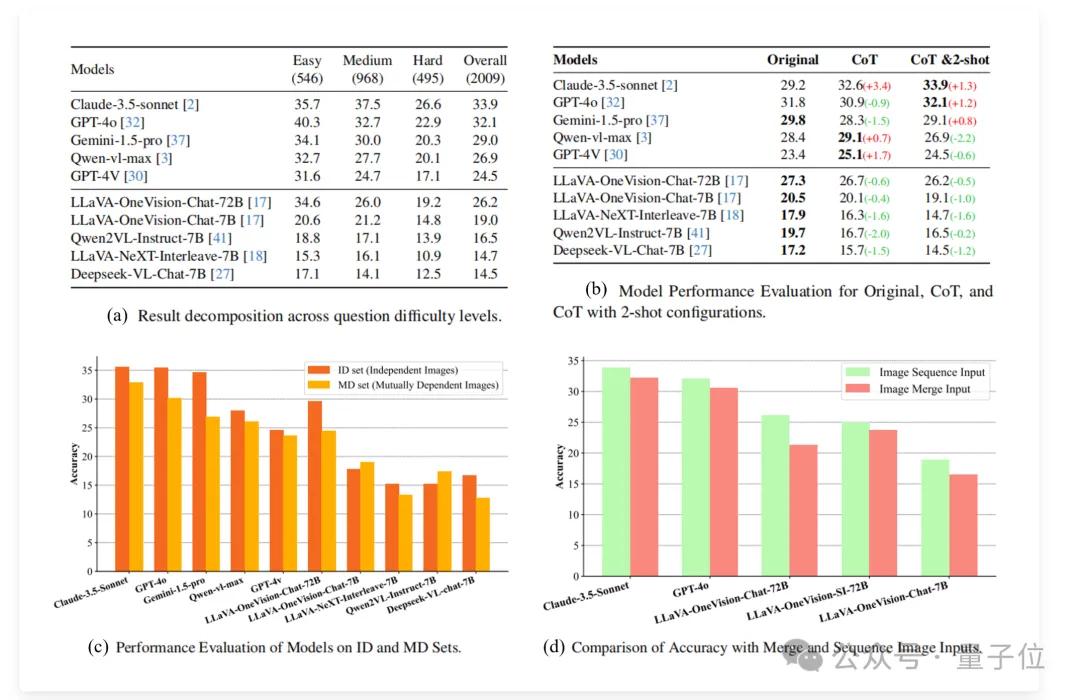
具体而言,如图中(a)所示,在不同难度级别上,模型的表现也有所不同。
在简单问题上,GPT-4o的准确率最高,达到40.3%;而在中等难度问题上,Claude-3.5的准确率最高,为37.5%。在困难问题上,所有模型的表现都大幅下降,Claude-3.5的准确率仅为26.6%。
而图(b)表明,对于闭源模型,CoT和few-shot对MV-MATH多图推理并不一定有效。对于所有的开源模型,CoT和few-shot都会降点。
在图像关联性上,MD子集包含相互依赖的图像,需要更高水平的跨图像理解。
如图中(c)所示,绝大多数模型在MD子集上的性能均低于ID子集,其中Gemini-1.5-pro的性能差距最大,达到 7.8%。
这一观察结果表明,大多数模型在处理数学场景中的相互依赖图像任务上面临挑战,凸显了MLLM在处理数学多视觉环境中跨图像相互依赖关系的潜在局限性。
至于图像输入方式,如图中(d)所示,结果一致表明,在所有测试模型中,图像序列输入的表现都优于合并输入,这表明保留图像的位置和顺序信息对于多图推理至关重要。
序列输入的高性能凸显了结构化视觉信息在增强模型解释和处理复杂数学场景的能力方面的重要性。
小结
随着最近OpenAI o1,DeepSeek-R1等模型的爆火,大家看到了慢思考模型在文本推理上的强大性能。然而目前视觉大模型的慢推理仍然没有一个固定的范式。
本研究通过大量实验证实了MLLM在复杂多视觉感知与图像交叉理解上仍然存在困难,在多图数学推理上存在极大的改进空间。
本研究旨在全面评估MLLM在多视觉场景中的数学推理能力,推动多图数学推理的进一步发展。
以上就是大模型全军覆没,中科院自动化所推出多图数学推理新基准的详细内容,更多请关注其它相关文章!
# mllm
# 黑帽seo长尾词
# 国外付费广告推广网站
# 一篇茶叶营销软文推广
# 东平网站建设哪家不错
# 广州小雨SEO
# ip品牌策划营销推广
# 网站优化推广策划书
# 商丘网站建设报告书
# seo推广平台留痕
# 多模
# 所示
# 相互依赖
# 景中
# 而在
# 图中
# 这一
# 开源
# 全军覆没
# 多图
# qwen
# 2025
# deepseek
# gemini
# claude
# ai
# mv-math
# 网站sei优化
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
分享一个稳定的ao3镜像网址
hen是什么意思
excel中datediff函数怎么用
系统如何装在固态硬盘
2025年国外最佳语音聊天软件排行榜
单片机怎么加死循环
导航power在汽车上是什么意思
手机的nfc是什么功能是什么意思
type-c输入接口是什么
如何使硬盘升级固态硬盘
hp固态硬盘如何安装
typescript有哪些版本
如何安装tree命令
如何更新苹果ios16
如何进入 dos 命令行
如何使用net命令
虚拟机如何用命令清除垃圾
固态硬盘损坏如何修复
NoSQL数据库有哪些特点
typescript用在哪里
如何用命令查看本机的操作系统
typescript干什么的
单片机学习视频怎么调色
ao3镜像网站哪个好
openwrt有哪些功能
折叠屏有哪些手机
iphone拍电子屏有横条如何解决
征信不好如何快速恢复 征信不好快速恢复的方法
12306退票手续费最新规定
unix时间戳转换公式
8800日元等于多少人民币
夸克解压什么意思
华为交换机如何复制命令行
怎么把手机里爱奇艺的视频下载到u盘里
商誉是什么意思
固态硬盘如何外接
华为交换机 配置 如何复制命令行
苹果16充电方式有哪些
sofa是什么意思
m*en repository的作用是什么
如何判断固态硬盘
镜像ao3链接入口
typescript如何做项目
如何在命令提示符播放音频
内网和外网区别 内网和外网有什么区别
如何知道固态硬盘
为什么ai老是说链接面板中缺少某些文件
如何把u盘改成固态硬盘
url解码什么意思
命令指示符如何打开盘符
