









新闻中心 
媲美OpenAI事实性基准,这个中文评测集让o1-preview刚刚及格
 2024-11-20
2024-11-20 浏览次数:次
浏览次数:次 返回列表
返回列表☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
核心作者包括贺彦程,李世龙,刘佳恒,苏文博。作者团队来自淘天集团算法技术 - 未来生活实验室团队。为了建设面向未来的生活和消费方式,进一步提升用户体验和商家经营效果,淘天集团集中算力、数据和顶尖的技术人才,成立未来生活实验室。实验室聚焦大模型、多模态等 AI 技术方向,致力于打造大模型相关基础算法、模型能力和各类 AI Native 应用,引领 AI 在生活消费领域的技术创新。
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。
为了进一步同步推进中文社区对模型事实正确性的研究,淘天集团算法技术 - 未来生活实验室团队提出了 Chinese SimpleQA,这是第一个系统性地全面评估模型回答简短事实性问题能力的中文评测集,可以全面探测模型在各个领域的知识水平。具体来说,Chinese SimpleQA 主要有六个特点:
 Yaara
Yaara
使用AI生成一流的文案广告,电子邮件,网站,列表,博客,故事和更多…
 95
查看详情
95
查看详情

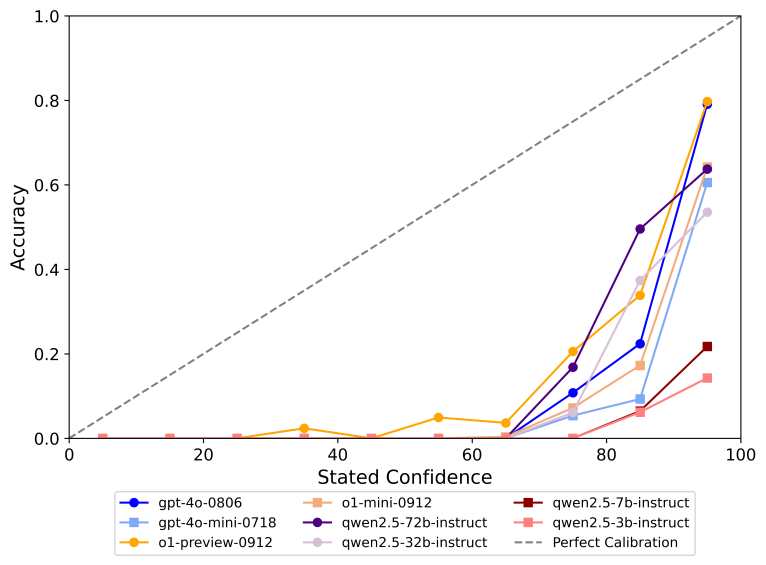
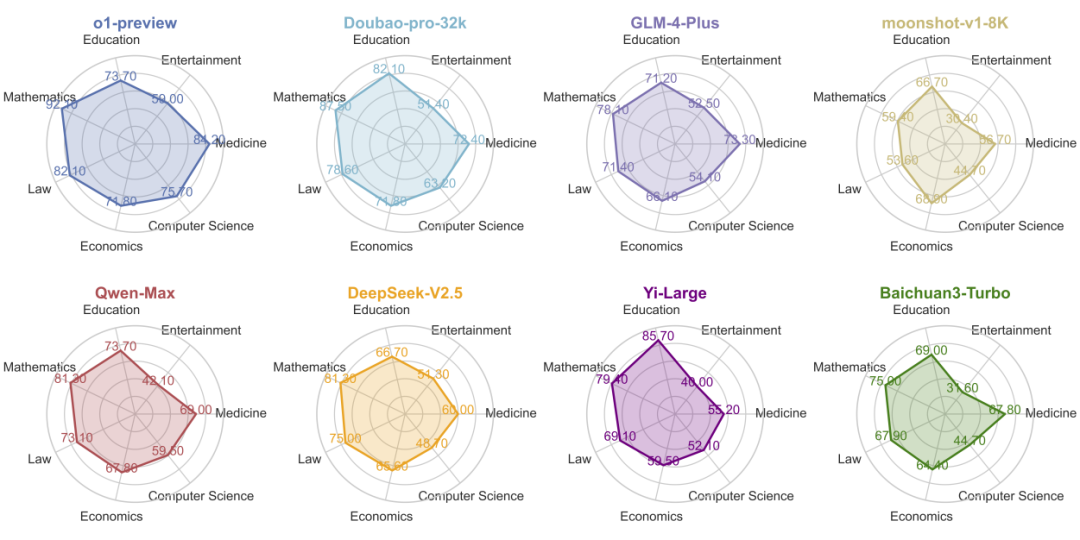
中文:专注于中文语言,并特地包含中国文化等特色知识相关的问题 全面性:涵盖 6 个大类主题(中华文化、人文与社会科学、自然科学、生活艺术与文化、工程技术与应用科学、社会)和 99 个子类主题 高质量:我们进行了全面且严格的质量控制,有包括 52 位外包和 6 位算法工程师的参与 静态:参考答案都是在时间上保持不变的,保证了评测集的长期有效性,可以长期作为模型知识能力的评估基准 易于评估:评测数据的问题和答案非常简短,评测可以基于任意的模型,能够以较低成本和较快速度进行高一致性的评测。 有难度和区分度:我们评估了 40 + 国内外开源和闭源大模型。目前在评测集上 o1-preview 都仅刚过及格线 (正确率 63.8), 其他大部分模型都处于低分状态,其中 GPT-4o mini 仅 37.6 分,ChatGLM3-6B 和 Qwen2.5-1.5B 仅 11.2 和 11.1 的准确率。
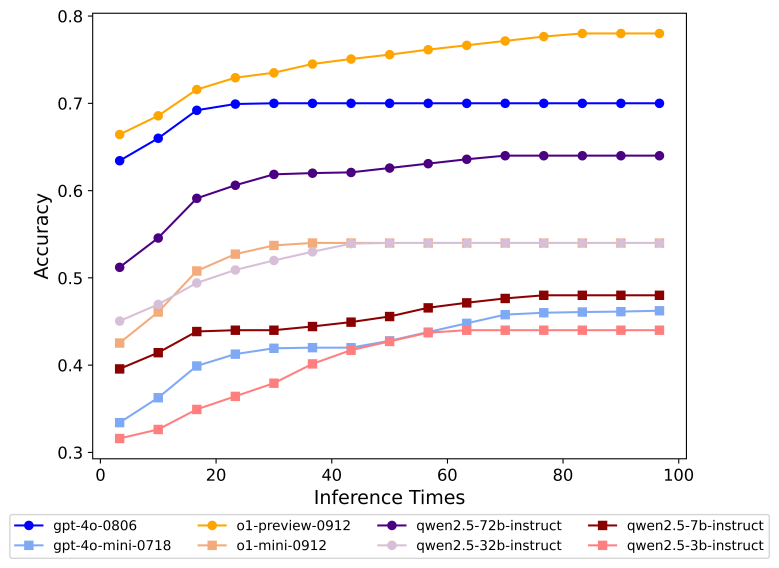
基于中文 SimpleQA,我们对现有 LLM 的事实性能力进行了全面的评估。并维护一个全面的 leaderboard 榜单。同时我们也在评测集上实验分析了推理 scaling law、模型校准、RAG、对齐税等研究问题,后续本评测集都可以作为这些方向的重要参考之一。
总之,我们希望 Chinese SimpleQA 能帮助开发者深入了解其模型在中文领域的事实正确性,同时也能为他们的算法研究提供重要基石,共同促进中文基础模型的成长。

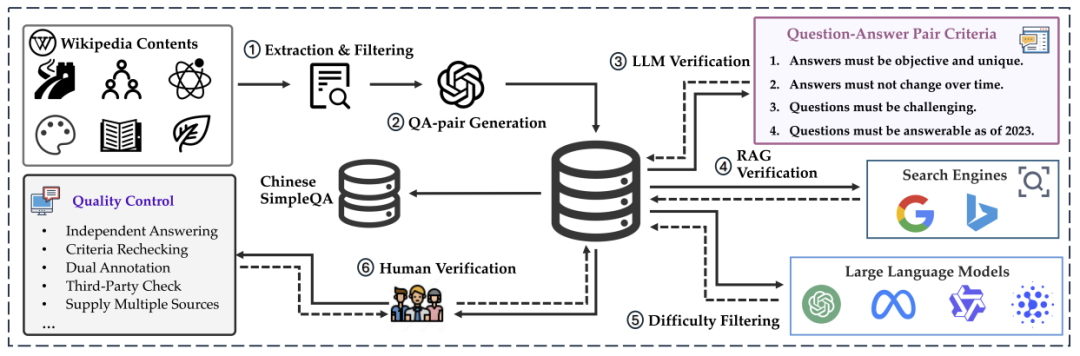
论文链接:https://arxiv.org/abs/2411.07140 项目主页:https://openstellarteam.github.io/ChineseSimpleQA 数据集下载:https://huggingface.co/datasets/OpenStellarTeam/Chinese-SimpleQA 代码仓库:https://github.com/OpenStellarTeam/ChineseSimpleQA
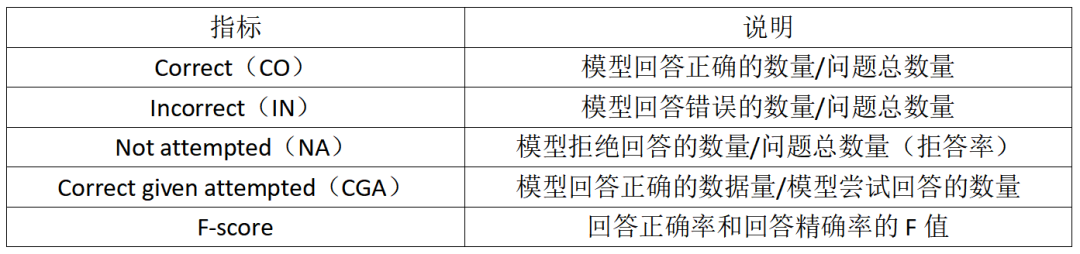
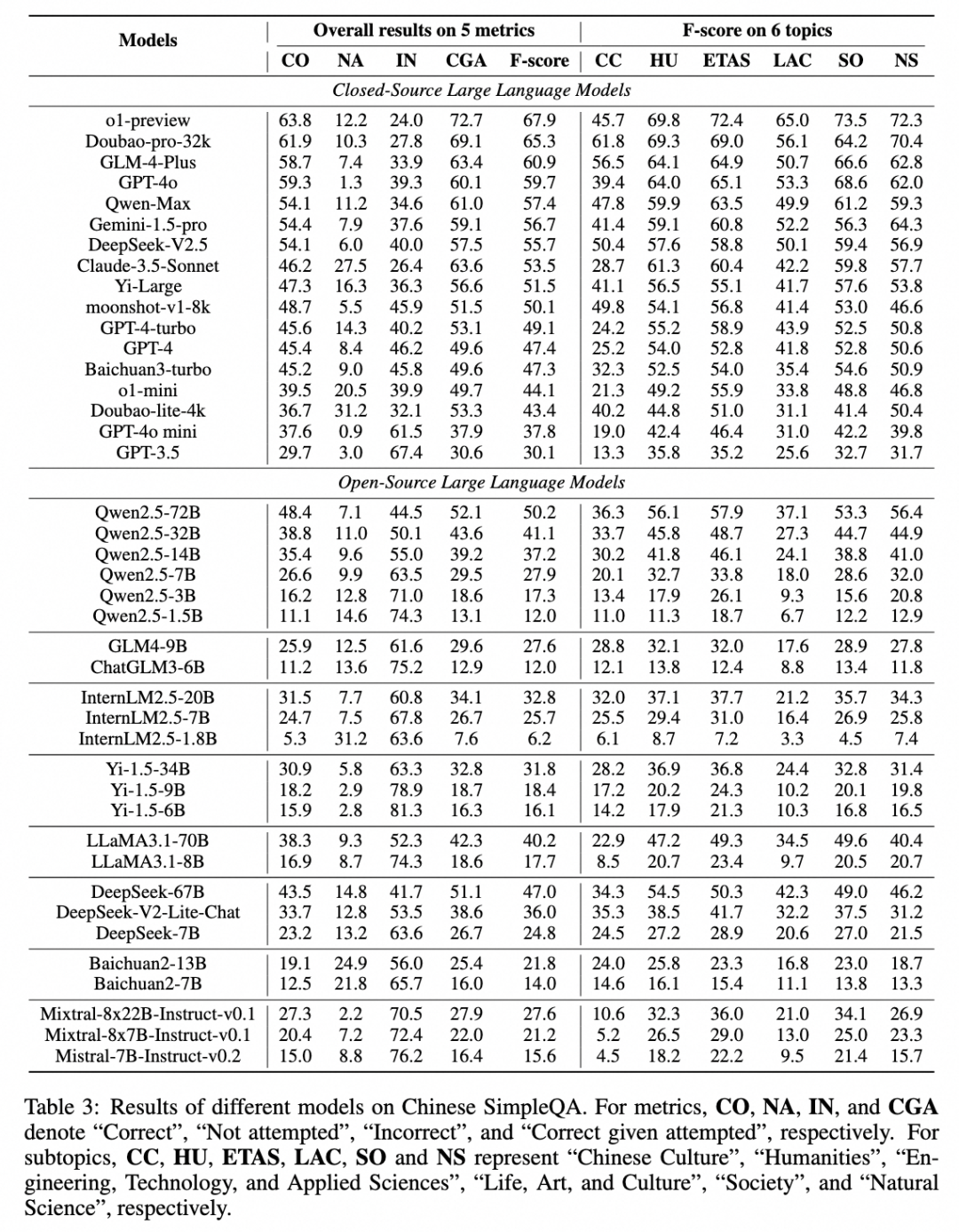
 RAG 后准确性都显著提高,例如,Qwen2.5-3B 的性能提升了三倍多。同时,在配置 RAG 后各模型之间的性能差异也显著减少,例如,带有 RAG 的 Qwen2.5-3B 与 Qwen2.5-72B 的 F-score 相差仅 6.9%。这表明 RAG 可显著缩小模型性能差距,使得较小模型在 RAG 支持下也能获得高性能。因此,RAG 仍是增强 LLMs 事实性的一条强有效的捷径。
RAG 后准确性都显著提高,例如,Qwen2.5-3B 的性能提升了三倍多。同时,在配置 RAG 后各模型之间的性能差异也显著减少,例如,带有 RAG 的 Qwen2.5-3B 与 Qwen2.5-72B 的 F-score 相差仅 6.9%。这表明 RAG 可显著缩小模型性能差距,使得较小模型在 RAG 支持下也能获得高性能。因此,RAG 仍是增强 LLMs 事实性的一条强有效的捷径。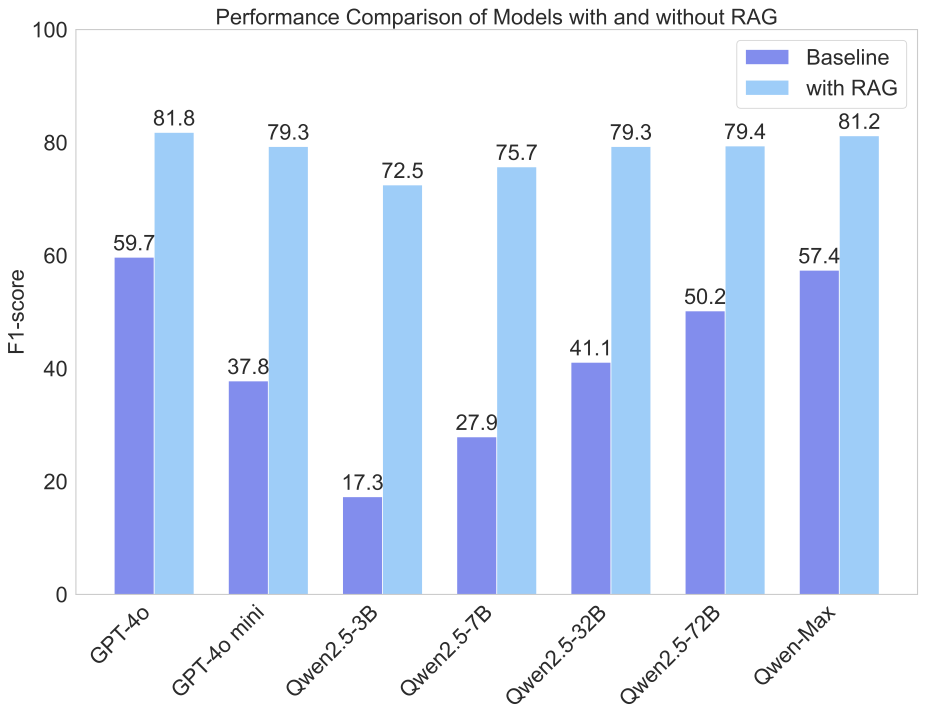
以上就是媲美OpenAI事实性基准,这个中文评测集让o1-preview刚刚及格的详细内容,更多请关注其它相关文章!
# 淘天集团
# git
# 谷歌
# 工程
# 应用科学
# 质量控制
# 也能
# 两位
# 寿光网络推广 网络营销
# 汕尾网站优化怎么做好
# 刷搜索关键词排名靠前
# 泌阳seo
# 监控类网站建设规划方案
# 微信公众号案例网站推广
# 营销策划市场推广方案
# 火麦营销专业seo推广
# seo网站运营公司排名
# 开源
# 这一
# 未来
# 子类
# 榜单
# 高质量
# type
# llama
# qwen
# deepseek
# 邮箱
# 百度
# ai
# 本地seo排名自学
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
juice是什么意思
固态硬盘2m如何修复
单身聊天app有哪些软件 2025最靠谱的单身交友软件推荐
typescript与es6学哪个
windows 如何连接ftp命令行
手机nfc功能功能是什么意思
油烟机上的power是什么意思
夸克前缀后缀什么意思啊
如何安装固态硬盘win10
typescript是什么类型的语言
vs怎么编写typescript
折叠屏手机哪个牌子性价比高
干股是什么意思
win7如何打开命令行窗口
如何修改cad命令
估值水平比较中市盈率E是什么意思
typescript用在哪里
如何给电脑加装固态硬盘
165开头的是什么电话号码
计数器上power是什么意思
a股等权平均市盈率是什么意思
单片机计时程序怎么写
如何清理固态硬盘
苹果16有哪些黑科技
sausage是什么意思
固态硬盘如何检查
typescript 如何解决 null
固态硬盘内存如何查找
typescript怎么拼接
linux如何切换到命令行模式
url解码什么意思
夸克文字口令是什么意思
苹果16有哪些变化尺寸
typescript怎么使用vue
手机如何ip绑定域名解析
j*a数组怎么新增值
哪些编程软件需用typescript
手机如何运行ping命令
j*a 怎么清空数组元素
摩托车上power是什么意思
如何用命令查看本机的操作系统
夸克网盘下载为什么要钱
使用typescript对团队有什么要求
春运抢票准备什么
win10锁屏壁纸怎么换360锁屏壁纸吗
为什么都用typescript
shell如何执行sql脚本命令行
ftp$如何执行宏命令
awful是什么意思
单片机怎么判定高电平
