









新闻中心 
Make U-Nets Great Again!北大&华为提出扩散架构U-DiT,六分之一算力即可超越DiT
 2024-11-15
2024-11-15 浏览次数:次
浏览次数:次 返回列表
返回列表☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

论文标题:u-dits: downsample tokens in u-shaped diffusion transformers
论文地址:https://arxiv.org/pdf/2405.02730
GitHub 地址:https://github.com/YuchuanTian/U-DiT
 Yaara
Yaara
使用AI生成一流的文案广告,电子邮件,网站,列表,博客,故事和更多…
 95
查看详情
95
查看详情

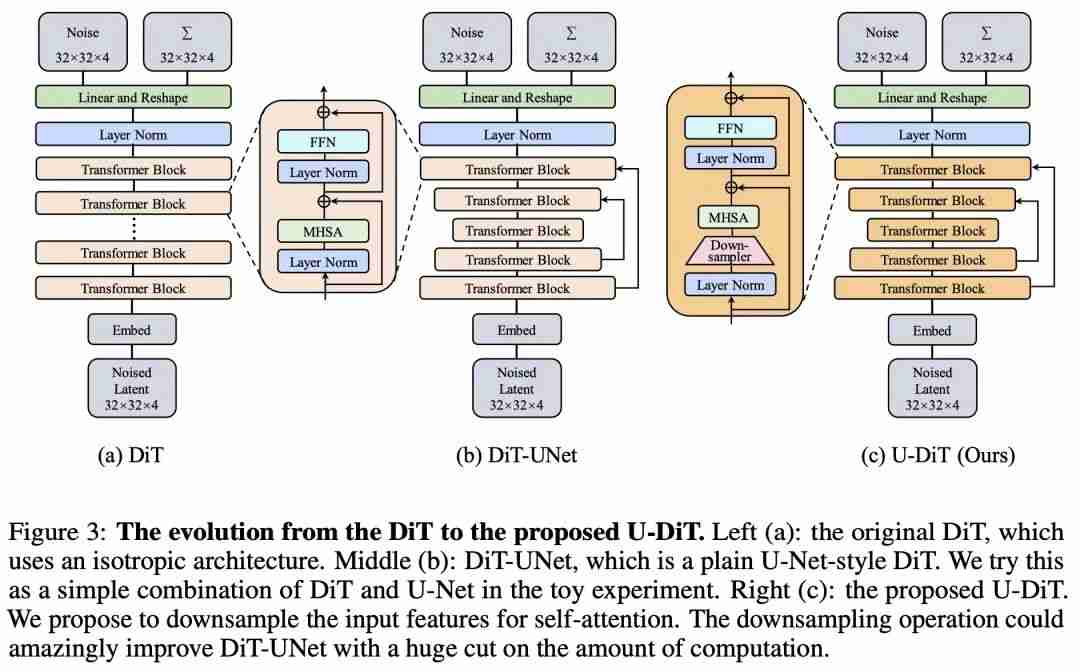
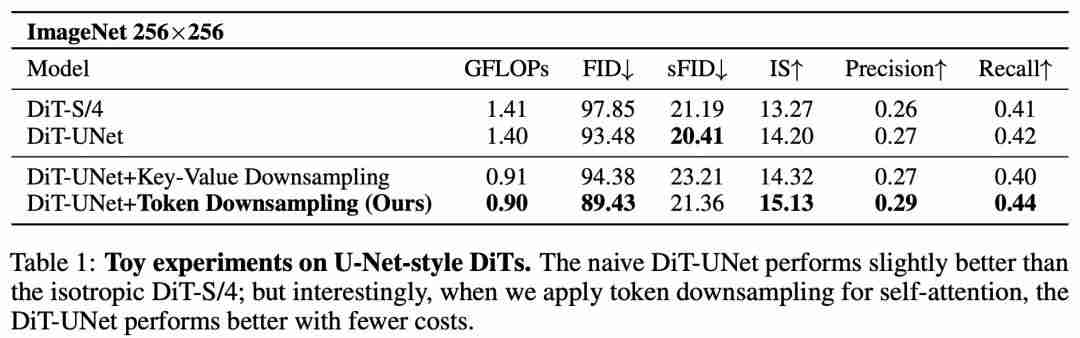

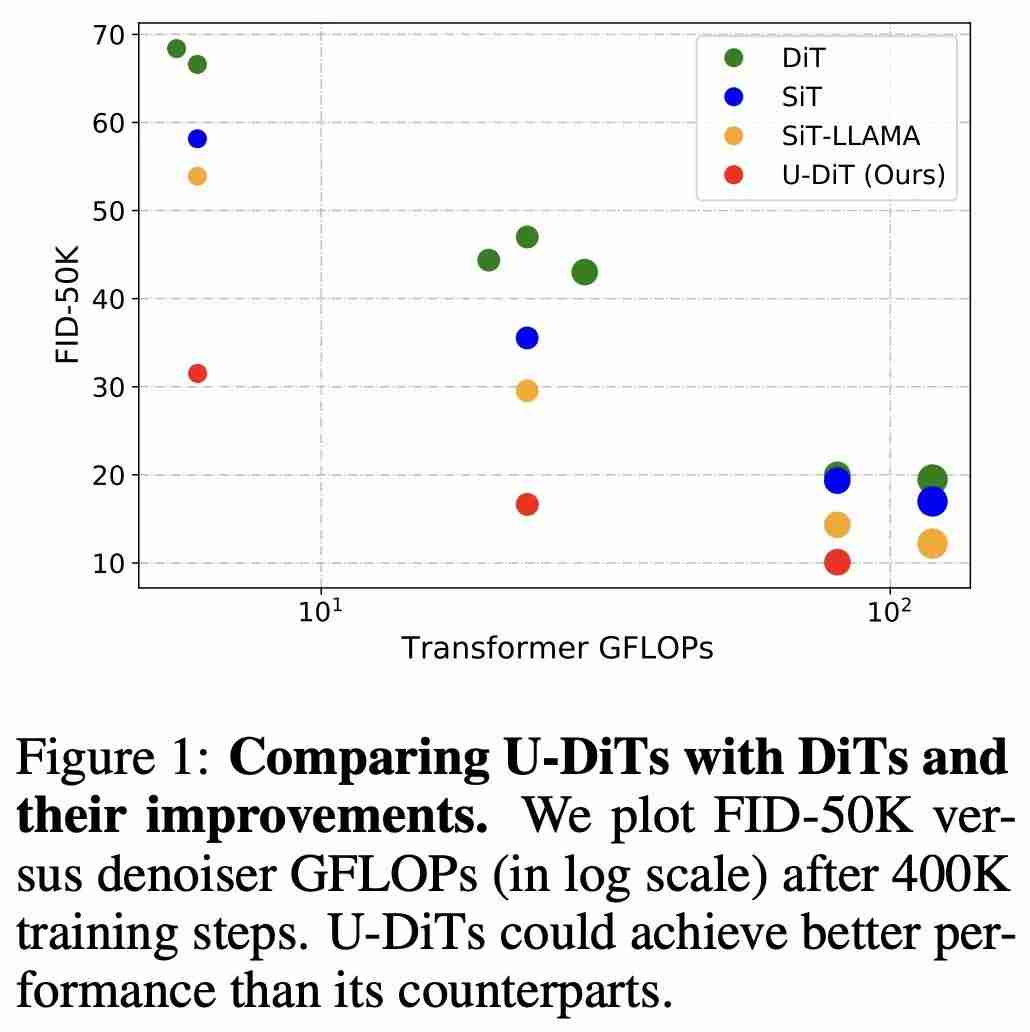
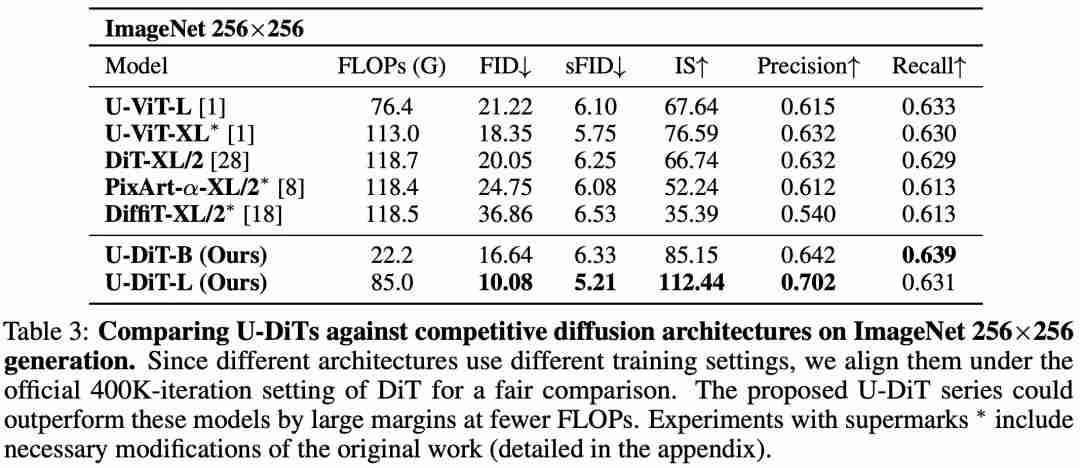
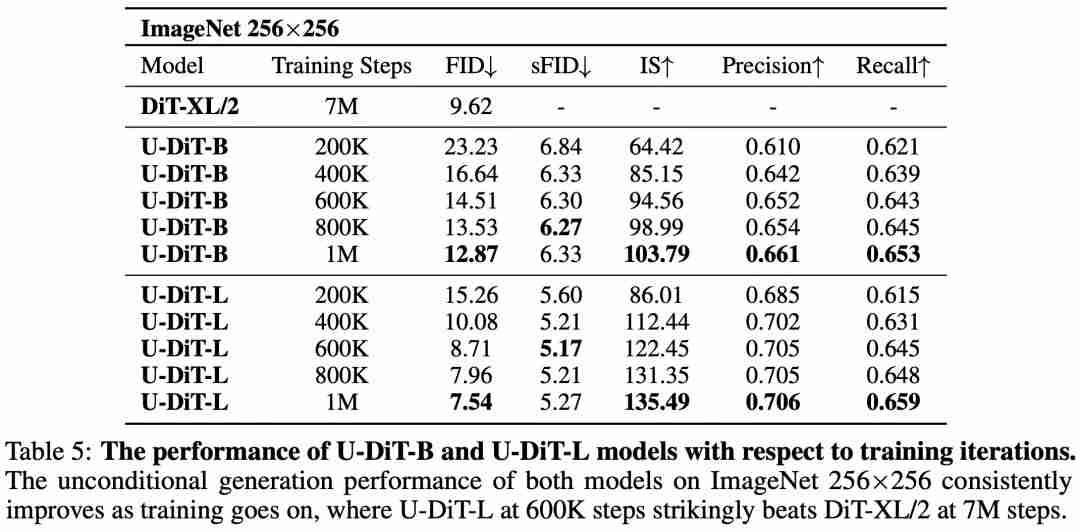
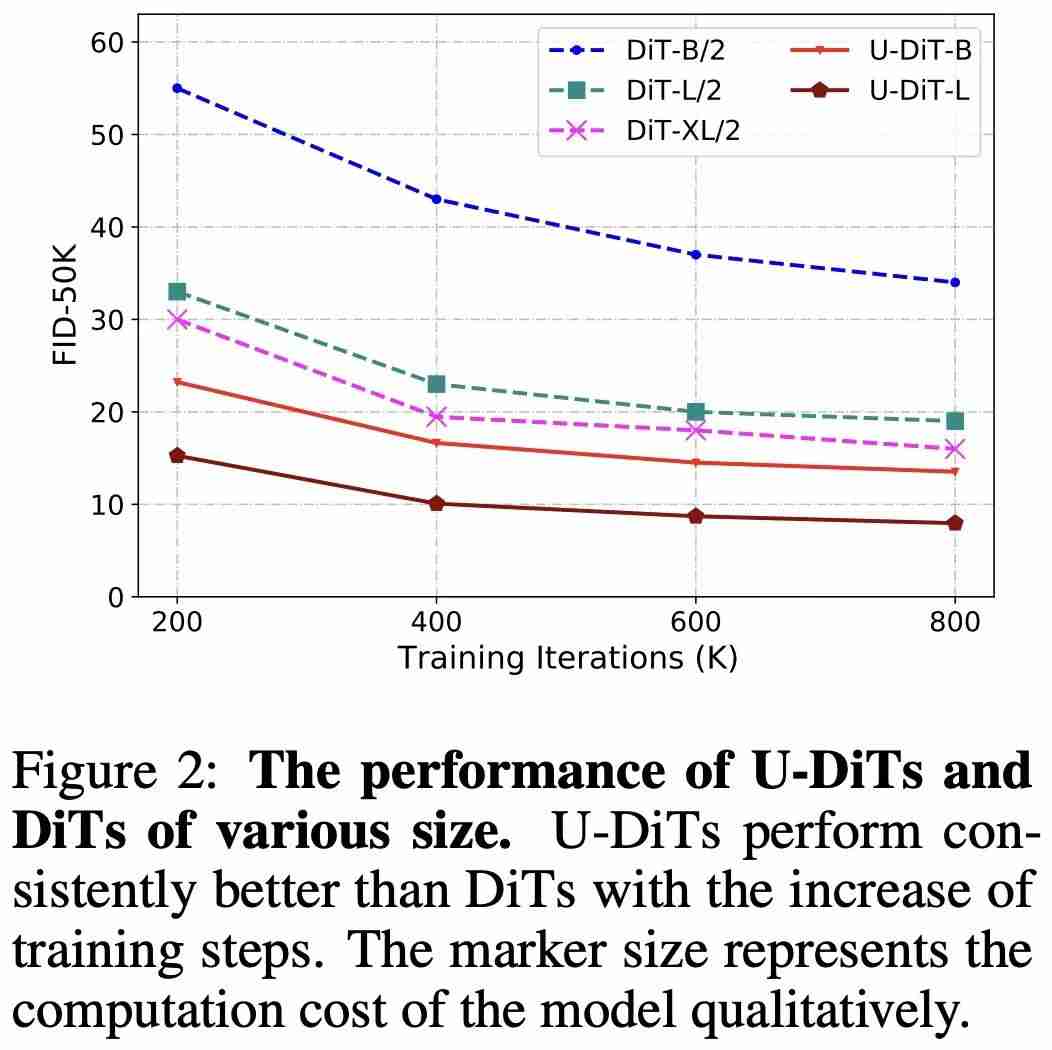
 (表 4、图 2)。
(表 4、图 2)。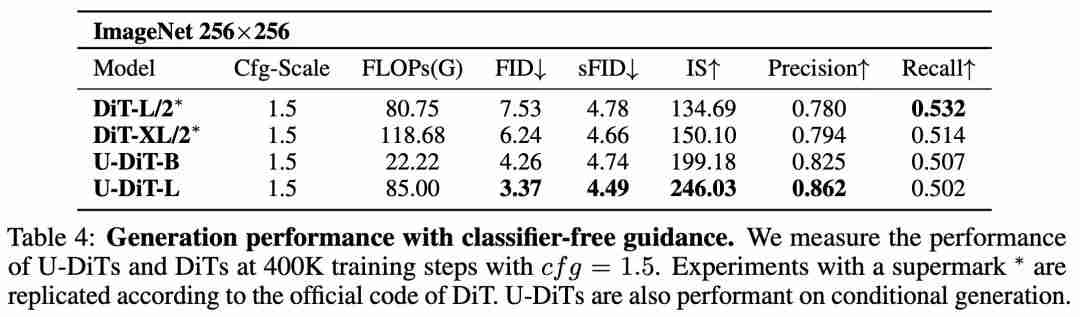

以上就是Make U-Nets Great Again!北大&华为提出扩散架构U-DiT,六分之一算力即可超越DiT的详细内容,更多请关注其它相关文章!
# 扩散模型
# 工程
# 所需
# 搜索引擎优化哪个网站好
# 网站推广数据怎么统计
# 临邑建设工地招聘网站
# 徐州推广网站建设价格
# 浙江企业网站建设电话
# 网站优化排名如何提升服务质量
# 可直接
# 新能源
# 日韩
# 已被
# 的是
# 迭代
# 提出了
# 北大
# 华为
# type
# sora
# 邮箱
# ai
# git
# u-dit
# 杭州展厅公司网站推广
# 重庆seo网站优化
# 济南长清网站推广
# 行业seo推广咨询热线
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
本科一批和本科二批是什么意思
ao3镜像网站永久地址入口
春运哪天抢票最好
360f4怎么取消百变壁纸
calm是什么意思
debian和ubuntu命令一样吗
bugly是什么
access中如何使用常用宏命令
夸克高考为什么不靠谱
html怎么使用typescript
折叠屏手机哪款最好
市盈率估值1stdv是什么意思
一年多少周
ai显示无法找到链接的文件是什么意思
划水是什么意思
电焊机power和oc是什么意思
linux如何使用db2命令
win7怎么关闭360壁纸屏保
电脑命令如何删除账号
j*a数组怎么新增值
市盈率百分位roe是什么意思
苹果16有哪些黑科技
如何用命令连接mysql
vs如何输入命令行参数
为什么夸克运行不了
win10系统如何打开cmd命令
老电脑如何装固态硬盘
j*a怎么让数组倒换
三星相机里power是什么意思
苹果16有哪些bug
bc是什么意思
安卓手机怎么打开5g
win10windows资源管理器在哪里打开
typescript如何定义常量
typescript掌握哪些可以做项目
焊机上power灯闪是什么意思
typescript如何使用viewer
苹果16有哪些自带配件
linux如何打开命令窗口
夸克用的什么服务器
内网和外网区别 内网和外网有什么区别
oppo手机nfc功能是什么意思
cos150度等于多少
typescript卸载不掉怎么办
如何通过命令系统还原
车子上面nfc功能是什么意思
苹果电脑如何输入命令
空调主板单片机怎么拆开
vivo手机nfc功能是什么意思
excel中datediff函数怎么用
