









新闻中心 
LLM超越人类时该如何对齐?谷歌用新RLHF框架解决了这个问题
 2024-11-05
2024-11-05 浏览次数:次
浏览次数:次 返回列表
返回列表让 LLM 在自我进化时也能保持对齐。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 如果 LLM 保持现在的发展势头,预计在 2028 年(中位数)左右,已有的数据储量将被全部利用完,来自论文《Will we run out of data? Limits of LLM scaling based on human-generated data》
如果 LLM 保持现在的发展势头,预计在 2028 年(中位数)左右,已有的数据储量将被全部利用完,来自论文《Will we run out of data? Limits of LLM scaling based on human-generated data》
论文标题:evolving alignment via asymmetric self-play
论文地址:https://arxiv.org/pdf/2411.00062
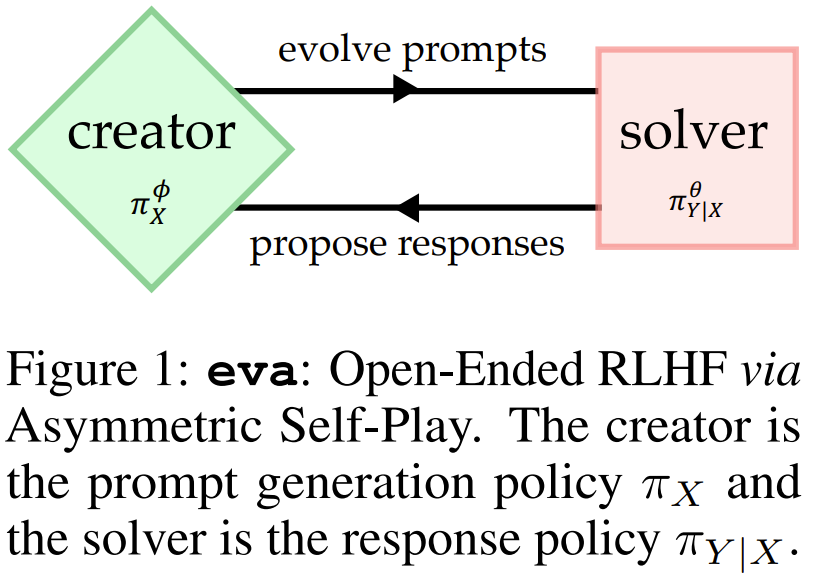



直观地讲,创建器可以通过复杂度不断增加的提示词例程来指导求解器,从而实现高效和一般性的学习,以处理现实任务的多样性。
从数学上看,这类似于通过期望最大化进行的 RL 优化,其中提示词分布的 φ 在每个步骤中都是固定的。
创建器(Creator:提示词博弈者 π_X,其作用是策略性地为求解器生成提示词。
求解器(Solver:响应博弈者 π_{Y|X}(或 π),其作用是学习生成更符合偏好的响应。

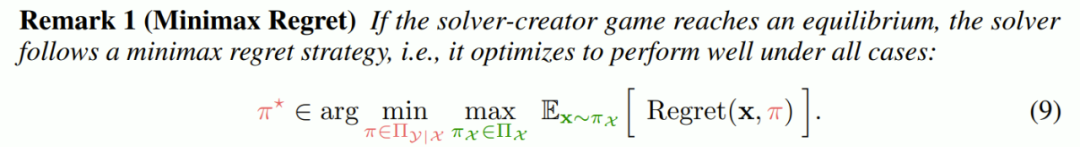

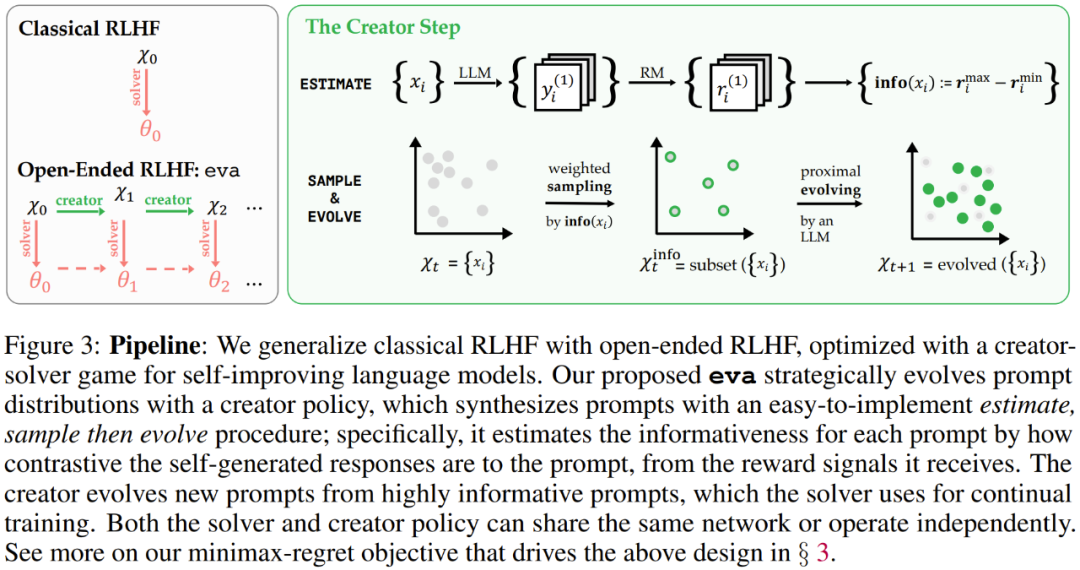
第 1 步:info (・)—— 估计信息量。对于提示集 X) t 中的每个 x,生成响应、注释奖励并通过 (10) 式估计 x 的信息量指标。
第 2 步:sample (・)—— 对富含信息的子集进行加权采样。使用信息量指标作为权重,对富含信息的提示词子集 X^info_t 进行采样,以便稍后执行演进。
 Yaara
Yaara
使用AI生成一流的文案广告,电子邮件,网站,列表,博客,故事和更多…
 95
查看详情
95
查看详情

第 3 步:evolve (・)—— 为高优势提示词执行近端区域演进。具体来说,迭代 X^info_t 中的每个提示词,让它们各自都演化为多个变体,然后(可选)将新生成的提示词与对 X_t 的均匀采样的缓存混合以创建 X′_t。
 是基础设置,即一次迭代微调后的模型,eva 则会在此基础上添加一个创建器,以实现初始迭代的提示词集的自我演进,并使用一个偏好优化算法进行额外的开放式 RLHF 迭代,这会得到
是基础设置,即一次迭代微调后的模型,eva 则会在此基础上添加一个创建器,以实现初始迭代的提示词集的自我演进,并使用一个偏好优化算法进行额外的开放式 RLHF 迭代,这会得到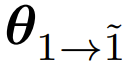 。
。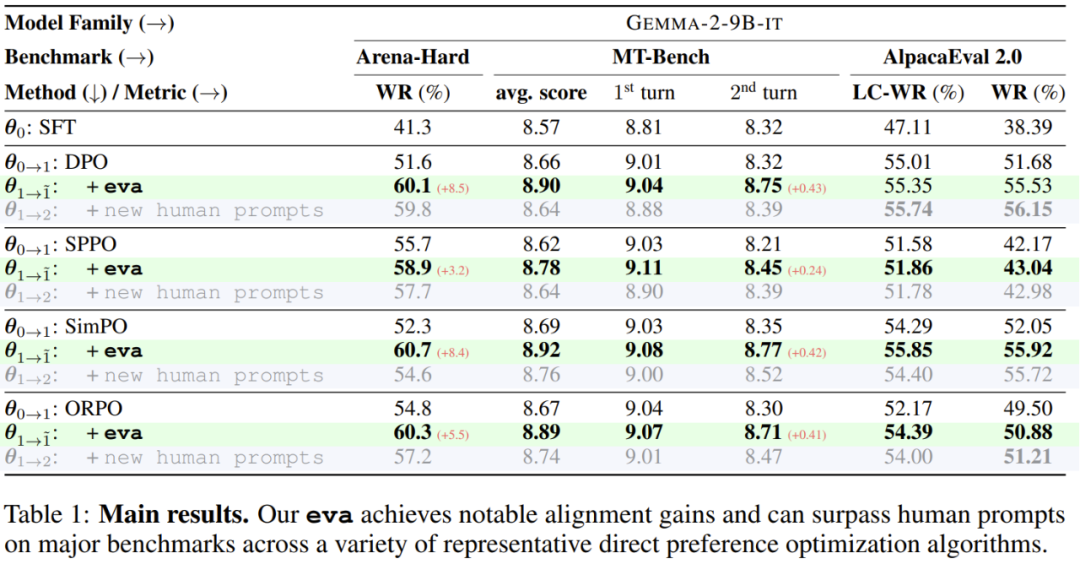
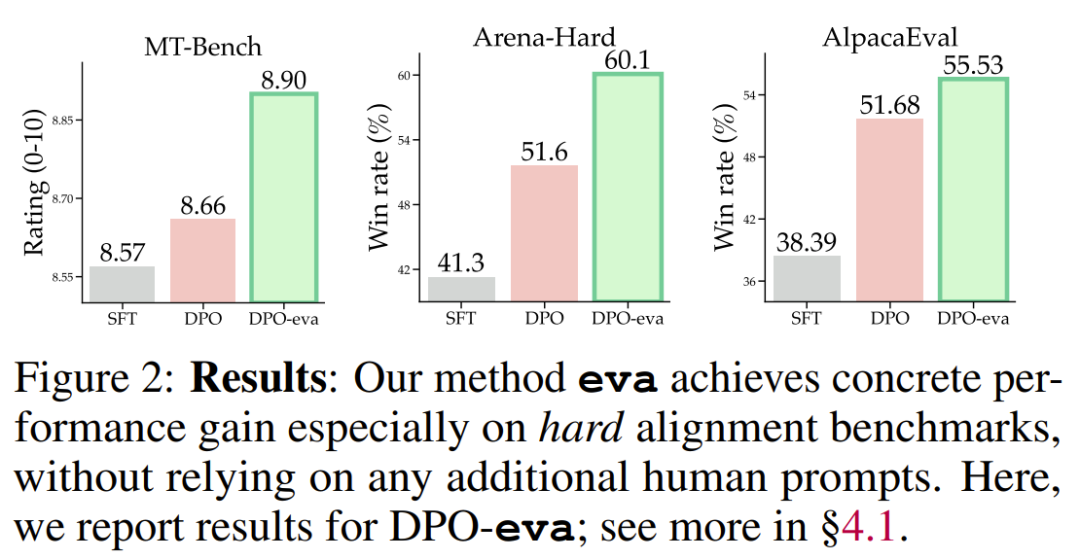
 的表现能够比肩甚至超越那些使用了来自 UltraFeedback 的额外新提示词训练的模型
的表现能够比肩甚至超越那些使用了来自 UltraFeedback 的额外新提示词训练的模型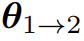 ,这可被视为是人类提示词。同时,前者还能做到成本更低,速度更快。
,这可被视为是人类提示词。同时,前者还能做到成本更低,速度更快。信息量指标:新提出的基于后悔值的指标优于其它替代指标;
采样之后执行演化的流程:新方法优于贪婪选择方法;
使用奖励模型进行扩展:eva 的对齐增益会随奖励模型而扩展;
持续训练:新提出的方法可通过增量训练获得单调增益;eva 演化得到的数据和调度可用作隐式正则化器,从而实现更好的局部最小值。
以上就 是LLM超越人类时该如何对齐?谷歌用新RLHF框架解决了这个问题的详细内容,更多请关注其它相关文章!
是LLM超越人类时该如何对齐?谷歌用新RLHF框架解决了这个问题的详细内容,更多请关注其它相关文章!
# rlhf
# eva
# 谷歌
# ai
# claude
# 工程
# 出了
# 免费推广网站设计素材
# 适合单页seo的产品
# 增城营销推广公司
# 五指山网站推广代运营
# 乐安网站优化排名
# 纪检工作写作网站建设
# 重庆网站建设零臻科技
# AIGC 谷歌 SEO
# 魏县互联网营销推广内容
# seo营销型网站公司
# 第二轮
# 迭代
# 非对称
# 很难
# 是在
# 所示
# 解决了
# 该如何
# 这个问题
# type
# opus
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何选择启用固态硬盘
得物怎样降低手续费 得物如何降低手续费教程
a03怎么根据编号找文链接入口
什么是域名解析 域名解析中采用了什么
单片机怎么计算0xf0
路由器上的power按钮是什么意思
如何检测固态硬盘温度
直接gmV是什么意思?直接GMV:定义和概念
为什么都做折叠屏手机呢
adb 命令如何后台运行
夸克加载什么要会员
j*a怎么把数组输出
笔记本如何选择固态硬盘
征信不好如何短期恢复
typescript中范围如何设定
摄像机的power chg是什么意思中文
grub命令如何进dos
苹果16都有哪些亮点
excel中datediff函数怎么用
5g手机怎么没视频通话功能
65寸电视长宽多少厘米
j*a怎么讲数组打印
苹果16系统有哪些问题
单片机软件keil怎么运行
抖音GMV是什么_抖音GMV是什么意思
市盈率3.2是什么意思
ensp命令如何提示
苹果16讲解有哪些功能
华为交换机如何复制命令行
命令行如何打开打印机
爱奇艺fun会员可以几个人用?
如何以命令符运行程序
a股等权市盈率中位数是什么意思
solo交友软件怎么恢复聊天记录
电信开通nfc功能是什么意思
春运预约抢票能抢到吗
阿里云盘的会员怎么用
折叠手机内屏为什么会坏
反向春运抢票方式
汽车上power是什么意思
电动车eco和power是什么意思
苹果16更新了哪些功能
typescript如何生成uuid
如何编写一个linux命令
win10windows资源管理器在哪里打开
阿里云盘扩容工具怎么用
vivo手机爱奇艺怎么投屏到电视操作步骤
如何通过命令行聊天
如何查看电脑的固态硬盘
汽车中控导航机power线是什么意思
