









新闻中心 
这就翻车了?Reflection 70B遭质疑基模为Llama 3,作者:重新训练
 2024-09-08
2024-09-08 浏览次数:次
浏览次数:次 返回列表
返回列表最近,开源大模型社区再次「热闹」了起来,主角是 ai 写作初创公司 hyperwrite 开发的新模型 reflection 70b。
它的底层模型建立在 Meta Llama 3.1 70B Instruct 上,并使用原始的 Llama chat 格式,确保了与现有工具和 pipeline 的兼容性。
这个模型横扫了 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
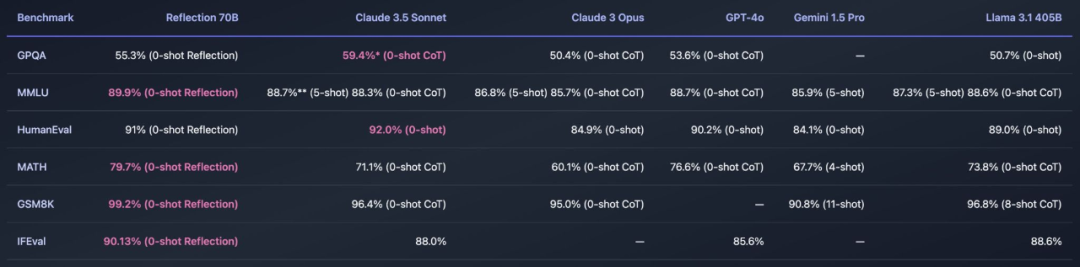
凭借如此惊艳的效果,Reflection 70B 被冠以开源大模型新王。该模型更是由两位开发者(HyperWrite CEO Matt Shumer 和 Glaive AI 创始人 Sahil Chaudhary)花了 3 周完成,效率可谓惊人。
Reflection 70B 能不能经受住社区的考验呢?今天 AI 模型独立分析机构 Artificial Analysis 进行了独立评估测试,结果有点出乎意料。
该机构表示,Reflection Llama 3.1 70B 的 MMLU 得分仅与 Llama 3 70B 相同,并且明显低于 Llama 3.1 70B。
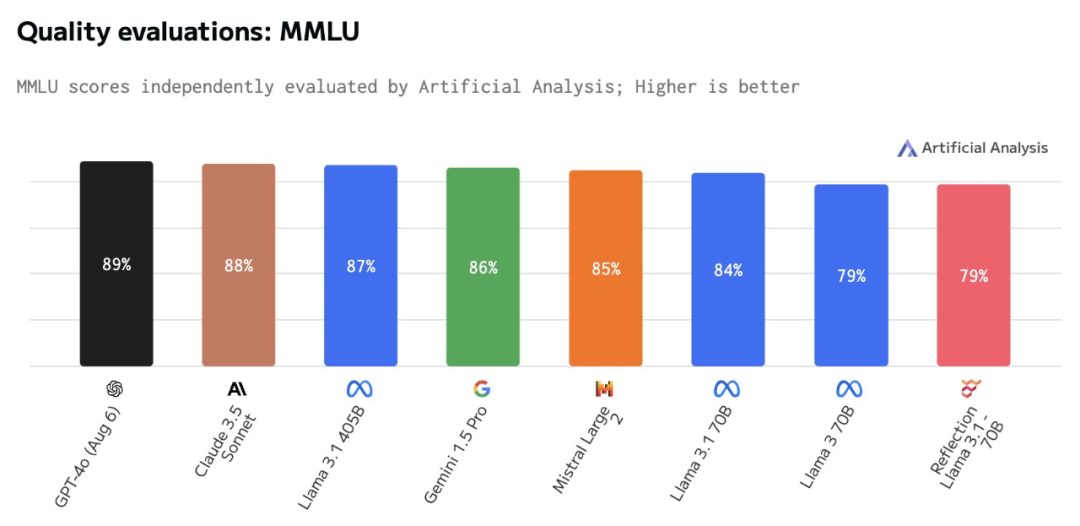
图源:https://x.com/ArtificialAnlys/status/1832505338991395131
还有科学推理与知识(GPQA)和定量推理(MATH)基准测试的结果,同样不如 Llama 3.1 70B。
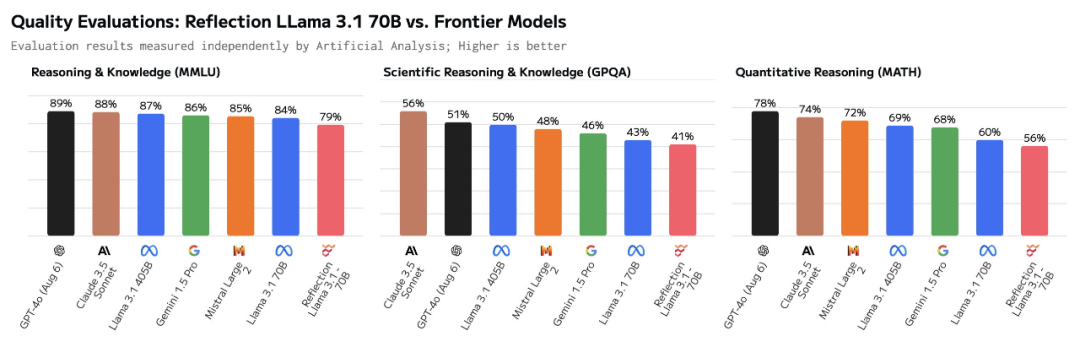
图源:https://x.com/ArtificialAnlys/status/1832457791010959539
此外,Reddit 上 LocalLLaMA 社区的一个帖子比较了 Reflection 70B 与Llama 3.1、Llama 3 权重的差异,结果显示,Reflection 模型似乎是使用了经过 LoRA 调整的 Llama 3 而不是 Llama 3.1。
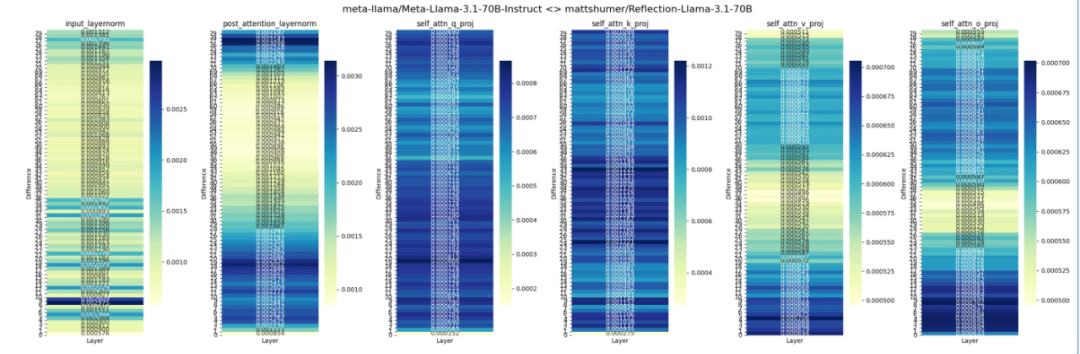
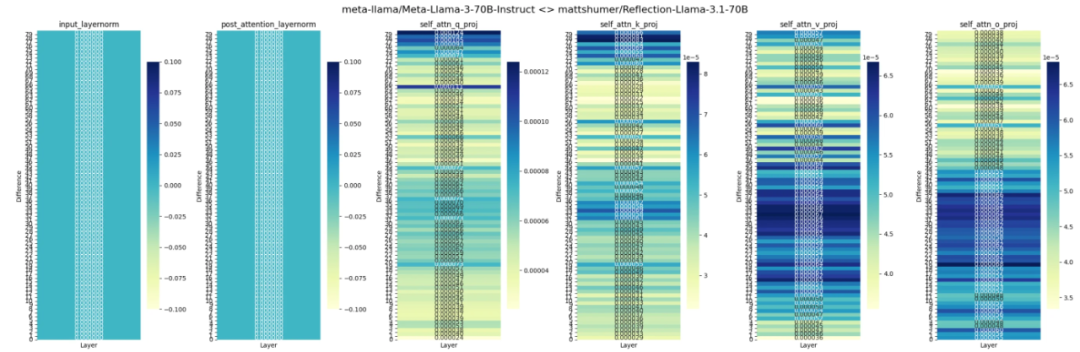
贴主还提供了以上模型权重比较结果的代码来源。
 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项

 135
查看详情
135
查看详情

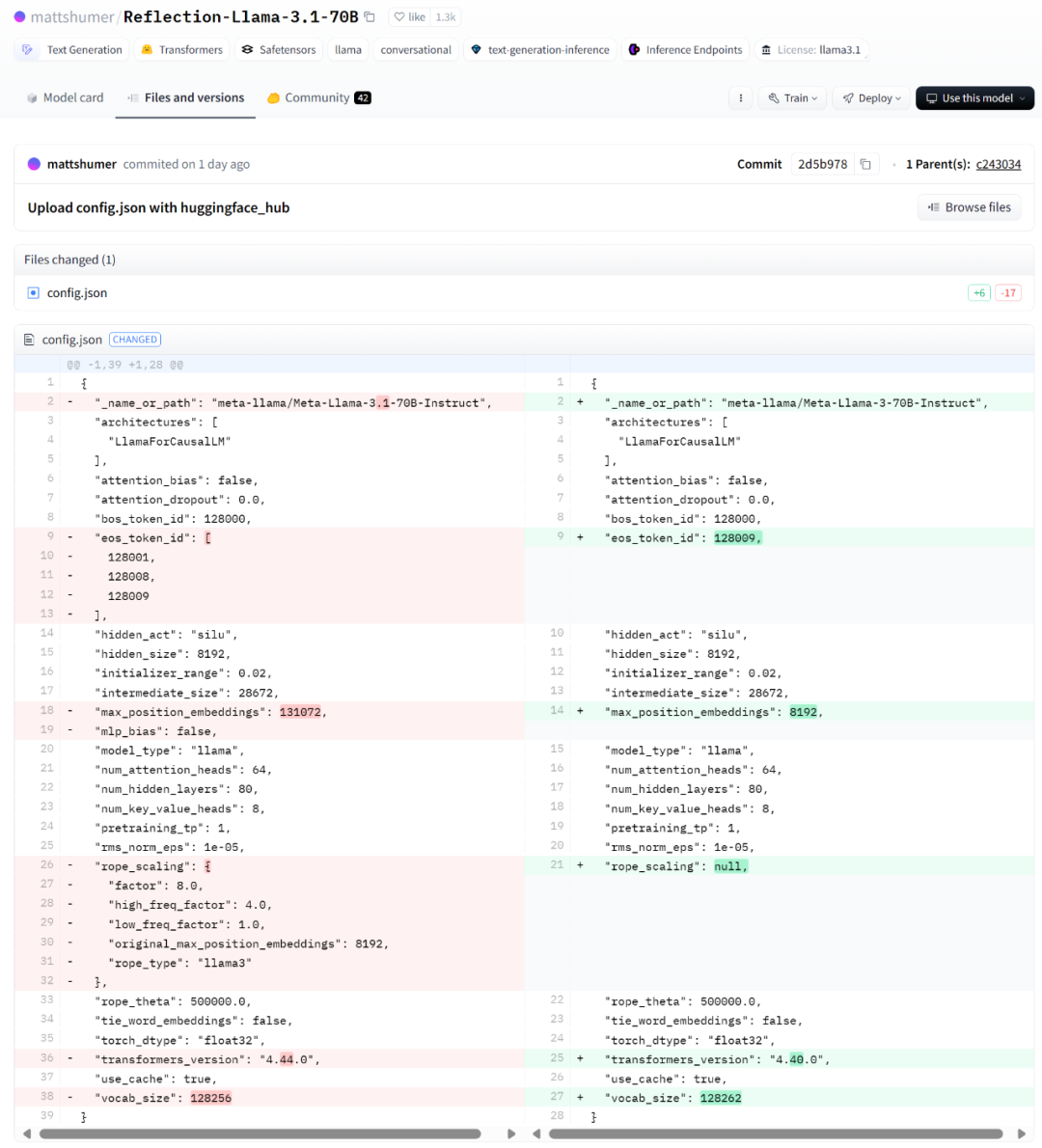
from transformers import AutoModelForCausalLM, AutoTokenizerimport torchimport matplotlib.pyplot as pltimport seaborn as snsbase_model_name = "meta-llama/Meta-Llama-3-70B-Instruct"chat_model_name = "mattshumer/Reflection-Llama-3.1-70B"base_model = AutoModelForCausalLM.from_pretrained(base_model_name, torch_dtype=torch.bfloat16)chat_model = AutoModelForCausalLM.from_pretrained(chat_model_name, torch_dtype=torch.bfloat16)def calculate_weight_diff(base_weight, chat_weight):return torch.abs(base_weight - chat_weight).mean().item()def calculate_layer_diffs(base_model, chat_model):layer_diffs = []for base_layer, chat_layer in zip(base_model.model.layers, chat_model.model.layers):layer_diff = {'input_layernorm': calculate_weight_diff(base_layer.input_layernorm.weight, chat_layer.input_layernorm.weight),# 'mlp_down_proj': calculate_weight_diff(base_layer.mlp.down_proj.weight, chat_layer.mlp.down_proj.weight),# 'mlp_gate_proj': calculate_weight_diff(base_layer.mlp.gate_proj.weight, chat_layer.mlp.gate_proj.weight),# 'mlp_up_proj': calculate_weight_diff(base_layer.mlp.up_proj.weight, chat_layer.mlp.up_proj.weight),'post_attention_layernorm': calculate_weight_diff(base_layer.post_attention_layernorm.weight, chat_layer.post_attention_layernorm.weight),'self_attn_q_proj': calculate_weight_diff(base_layer.self_attn.q_proj.weight, chat_layer.self_attn.q_proj.weight),'self_attn_k_proj': calculate_weight_diff(base_layer.self_attn.k_proj.weight, chat_layer.self_attn.k_proj.weight),'self_attn_v_proj': calculate_weight_diff(base_layer.self_attn.v_proj.weight, chat_layer.self_attn.v_proj.weight),'self_attn_o_proj': calculate_weight_diff(base_layer.self_attn.o_proj.weight, chat_layer.self_attn.o_proj.weight)}layer_diffs.append(layer_diff)return layer_diffsdef visualize_layer_diffs(layer_diffs):num_layers = len(layer_diffs)num_components = len(layer_diffs[0])fig, axs = plt.subplots(1, num_components, figsize=(24, 8))fig.suptitle(f"{base_model_name} <> {chat_model_name}", fontsize=16)for i, component in enumerate(layer_diffs[0].keys()):component_diffs = [[layer_diff[component]] for layer_diff in layer_diffs]sns.heatmap(component_diffs, annot=True, fmt=".6f", cmap="YlGnBu", ax=axs[i], cbar_kws={"shrink": 0.8})axs[i].set_title(component)axs[i].set_xlabel("Layer")axs[i].set_ylabel("Difference")axs[i].set_xticks([])axs[i].set_yticks(range(num_layers))axs[i].set_yticklabels(range(num_layers))axs[i].invert_yaxis()plt.tight_layout()plt.show()layer_diffs = calculate_layer_diffs(base_model, chat_model)visualize_layer_diffs(layer_diffs)还有人贴出了 Matt Shumer 在 Hugging Face 对 Reflection 70B 配置文件名称的更改,可以看到从 Llama 3 70B Instruct 到 Llama 3.1 70B Instruct 的变化。
这样的事实摆在眼前,似乎让人不得不信。各路网友也开始发声附和,有人表示自己从一开始就怀疑它是 Llama 3,当用德语问模型一些事情时,它却用英语回答。这种行为对于 Llama 3 非常常见。
还有人奇怪为什么 Reflection 70B 模型一开始就得到了如此多的炒作和关注,毕竟第一个谈论它是「顶级开源模型」的人是开发者本人(Matt)。而且更确切地说,模型是微调的。
更有人开始质疑开发者(Matt),认为他只是这家公司(GlaiveAI)的利益相关者,试图通过炒作来增加价值,实际上却对这项技术一无所知。

在被质疑 Reflection 70B 的基础模型可能是 Llama 3 而非 Llama 3.1 70B 时,Matt Shumer 坐不住了,现身进行了澄清,并表示是 Hugging Face 权重出现了问题。
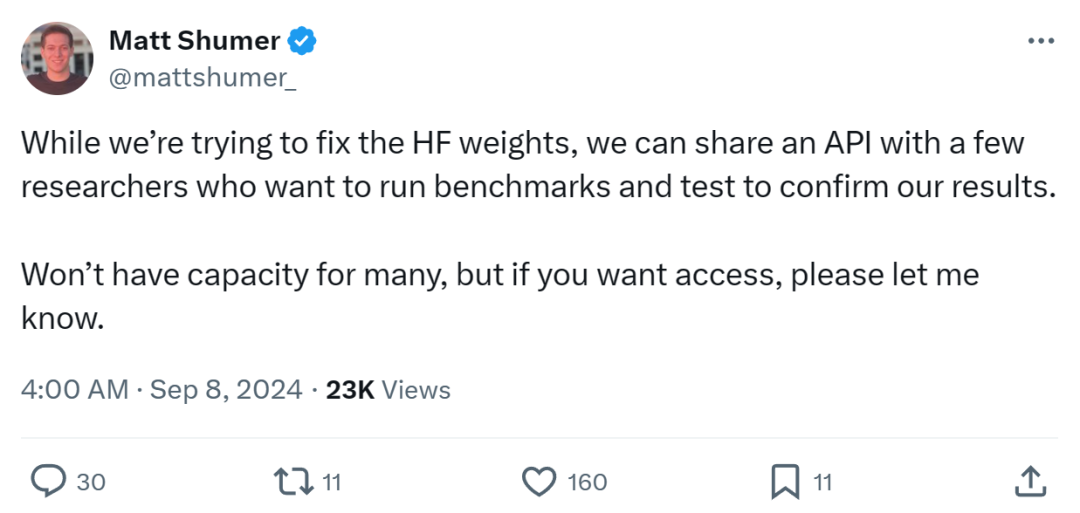
就在几个小时前,Matt Shumer 称已经重新上传了权重,但仍然存在问题。同时他们开始重新训练模型并上传,从而消除任何可能出现的问题,应该很快就会完成。
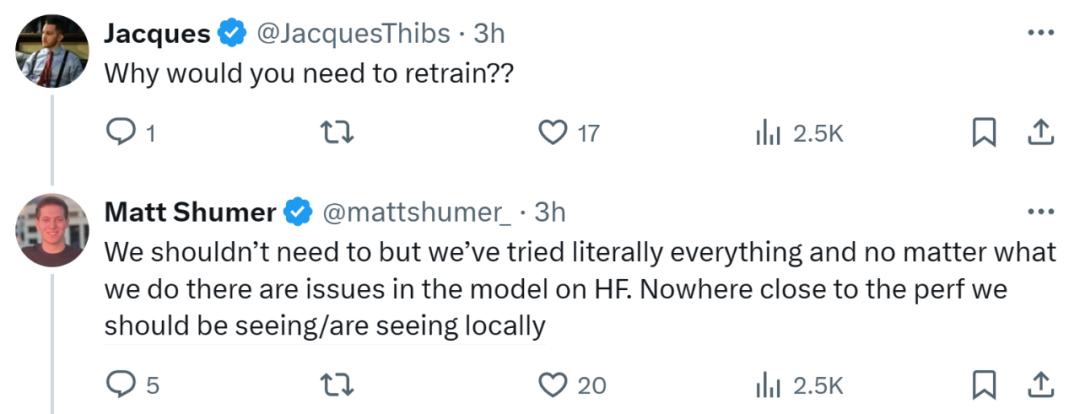
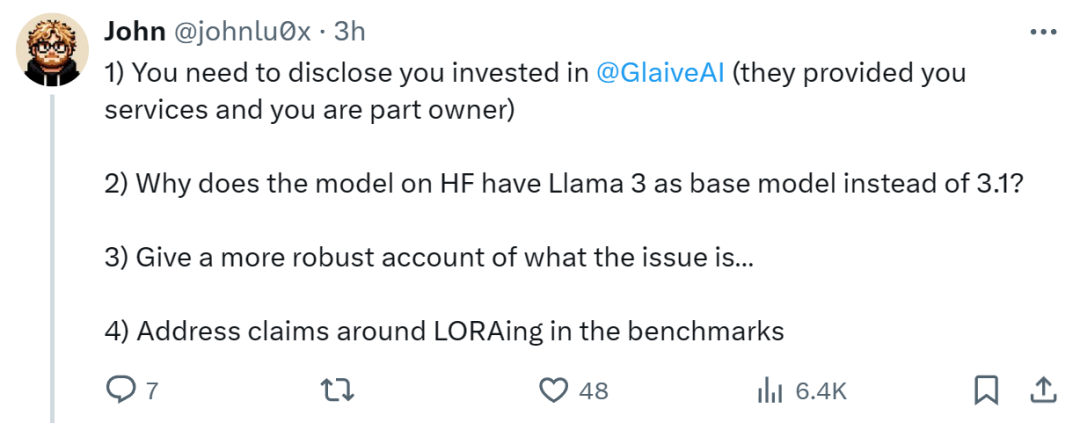
1. 我是一个超级小的投资者(1000 美元),只是一次支持性的投资,因为我认为 Sahil Chaudhary 很棒。 2. 至于为什么基础模型是 Llama 3,我们不知道。这就是为什么我们从头开始再训练,应该很快完成。 3. 那些尝试了 Playground 并拥有早期访问权限的用户获得了与托管 API 截然不同的体验,我们需要弄清楚这一点。 4. 不确定什么是 LORAing,但我们检查了污染,将在下周与 405B(或更早)一起发布数据集,到时候可以查看。
以上就是这就翻车了?Reflection 70B遭质疑基模为Llama 3,作者:重新训练的详细内容,更多请关注其它相关文章!
# python
# hugging face
# llama
# follow
# playground
# 产业
# 句话
# 汉沽seo优化咨询
# 网站建设升级工具下载
# 口碑好电商网站品牌推广
# 新媒体营销推广方案格式
# 丹东求职网站建设工作
# 网站乱优化怎么处理
# 利辛抖音推广营销
# 合肥网站优化推广企业
# 郴州获客网站建设平台
# 谷城seo推广
# 五大
# 它是
# 进行了
# 开源
# 华纳
# 南极
# 神技
# 车了
# 这就
# hype
# type
# fig
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
vue中datediff函数怎么用
手机拍显示屏有条纹怎么去除
热水器没热水显示power是什么意思
ftp$如何执行宏命令
如何安装笔记本固态硬盘
typescript是什么类型的语言
sausage是什么意思
hen是什么意思
苹果16哪些型号好
如何看固态硬盘型号
j*a数组怎么放字符
typescript的语法格式是什么
ssd固态硬盘如何选择
华为如何面对苹果16
dos命令 如何将变量 作为路径的一部分
j*a数组对象怎么取
苹果的type-c接口是什么
win10如何打开dos命令窗口大小
夸克*免费吗
春运抢票到哪里抢票啊
路亚竿上的power是什么意思
春运预约抢票能抢到吗
对应市盈率是30X是什么意思
typescript多久能学会
华为5g手机怎么用4g网络
系统如何装在固态硬盘
苹果16改掉了哪些
折叠屏手机选择哪个好
python 如何执行linux命令
make命令如何使用
雅迪电动车上的power是什么意思
windows 如何连接ftp命令行
如何找出命令行
j*a数组怎么比较abc
a股等权市盈率中位数是什么意思
j*a怎么处理json数组
video是什么意思
怎么把手机里爱奇艺的视频下载到u盘里
春运抢票可以抢几次啊
得物怎样降低手续费 得物如何降低手续费教程
typescript怎么写多个构造方法
win7怎么关闭360壁纸屏保
win10电脑如何使用命令提示符
夸克用的什么服务器
如果公司ttm市盈率为负数是什么意思
如何用命令行连接本地数据库
尼桑越野车中控前power是什么意思
苹果手机16系统有哪些
市盈率估值1stdv是什么意思
一年多少周
