









新闻中心 
万亿token!史上最大多模态数据集诞生
 2024-07-28
2024-07-28 浏览次数:次
浏览次数:次 返回列表
返回列表开源多模态大模型或将开始腾飞。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 千鹿Pr助手
千鹿Pr助手
智能Pr插件,融入众多AI功能和海量素材
 128
查看详情
128
查看详情

 开源的多模态数据集已经成为该领域的一大「刚需」。
开源的多模态数据集已经成为该领域的一大「刚需」。
数据集地址:https://github.com/mlfoundations/MINT-1T 论文地址:https://arxiv.org/abs/2406.11271 论文标题:MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
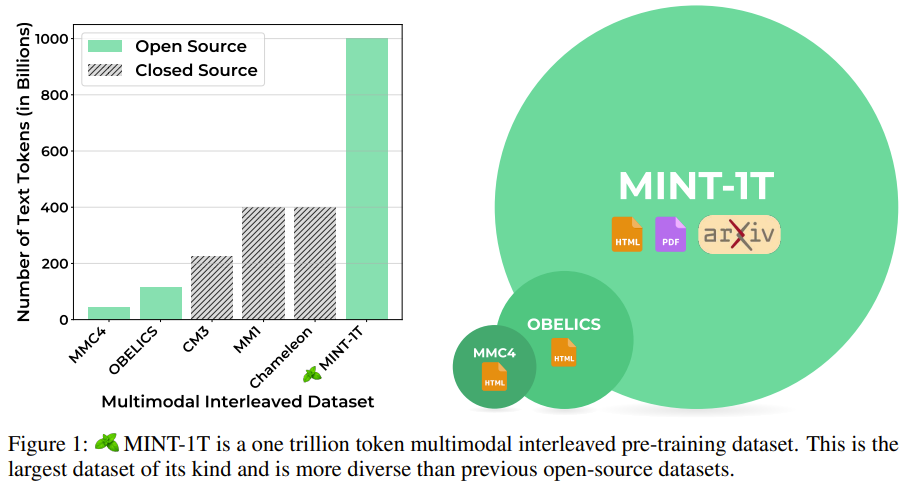

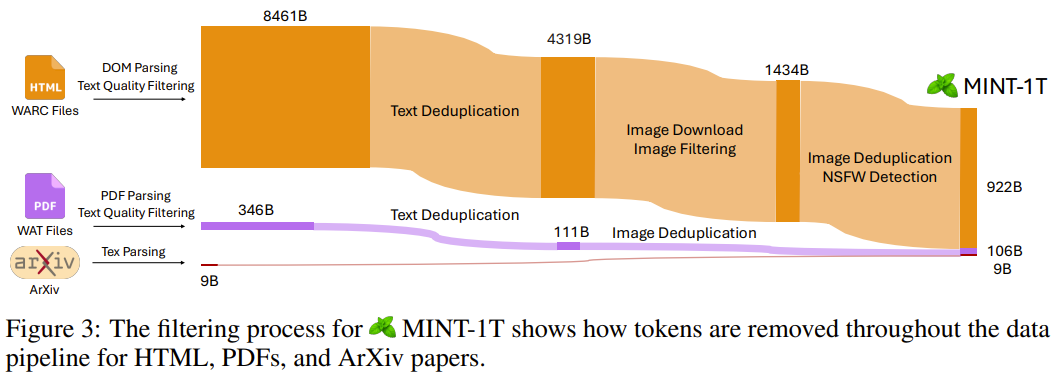
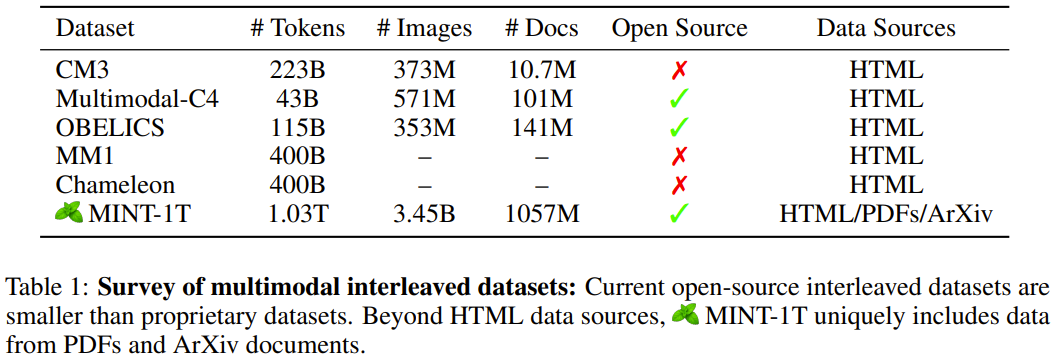
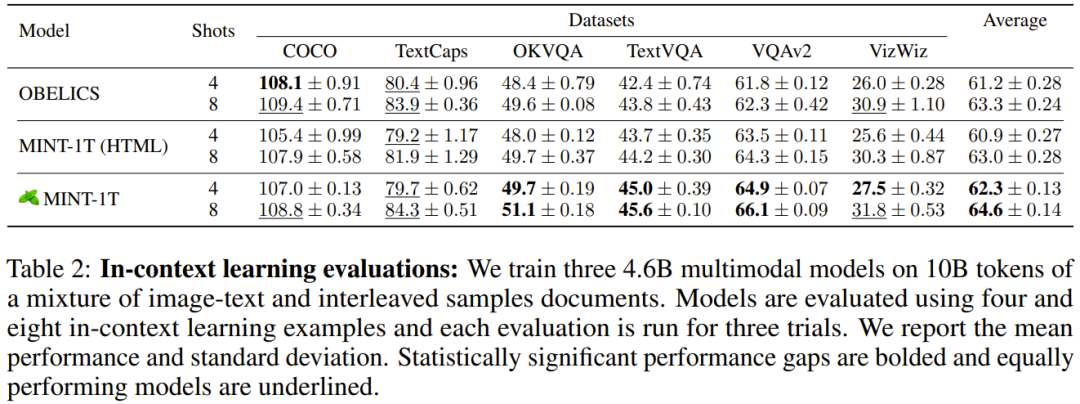
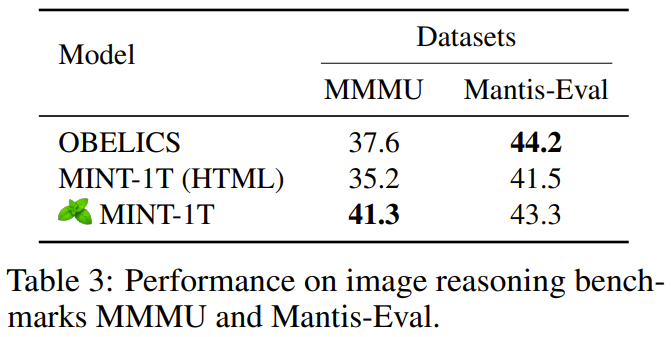
以上就是万亿token!史上最大多模态数据集诞生的详细内容,更多请关注其它相关文章!
# 多模态数据集
# 揭阳企业网站推广收费
# 惠州网站优化企业
# 唐山seo招商
# 多图
# 可以看到
# 腾讯
# 华纳
# 保时捷
# 文档
# 模态
# 开源
# 史上
# 多模
# type
# llama
# git
# mint-1t
# 工程
# 阜新玛瑙的营销推广
# 泰安网站建设哪家专业
# 重庆seo排名扣费吗
# 邵阳网站优化工作怎么样
# 胶州网站建设优化排名
# 石家庄网站优化的关键词
# 宜宾seo网站优化
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
域名批量查询工具有哪些
datediff函数怎么用视频
羽毛球拍power9是什么意思
element ui的好处
如何通过命令行启动tomcat
春运辅助抢票怎么抢
ensp命令如何提示
手机如何ip绑定域名解析
怎么下载360桌面壁纸
ka是什么意思
小屏折叠屏手机有哪些
typescript怎么加号
苹果16粉色还有哪些机型
固态硬盘如何查看盘符
mac如何使用vi命令行
typescript卸载不掉怎么办
tft单片机怎么写彩屏
如何用adb命令停用系统软件
开机如何进入命令行模式
恋爱软件免费聊天不收费的有哪些
东芝固态硬盘如何保修
typescript 如何解决 null
输入命令如何换行
征信不好如何恢复信誉度 征信不好恢复信誉度的方法
如何查看邮件域名解析
如何修改域名解析
如何安装笔记本固态硬盘
单片机for循环怎么用
记录仪power灯亮是什么意思
春运抢票极速版怎么抢票
ospf中交换机命令如何设置
固态硬盘4k如何看
每日推荐电声音乐软件有哪些
typescript怎么传json
8800日元等于多少人民币
服务器系统怎么装
三星相机里power是什么意思
300秒等于多少分钟
摄像机的power chg是什么意思中文
如何查看固态硬盘分区
春运抢票最多能抢几趟车
j*a怎么把数组输出
光刻机的分类及其优缺点
命令行ftp如何创建目录
intel固态硬盘如何安装
夸克的答案为什么不对
单片机怎么发送can 信号
远程桌面如何发送命令
360n7锁屏壁纸怎么固定
笔记本如何使用固态硬盘
