









新闻中心 
中科大联合华为诺亚提出Entropy Law,揭秘大模型性能、数据压缩率以及训练损失关系
 2024-07-22
2024-07-22 浏览次数:次
浏览次数:次 返回列表
返回列表
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

团队:中科大认知智能全国重点实验室陈恩红团队,华为诺亚方舟实验室 论文链接: https://arxiv.org/pdf/2407.06645 代码链接: https://github.com/USTC-StarTeam/ZIP
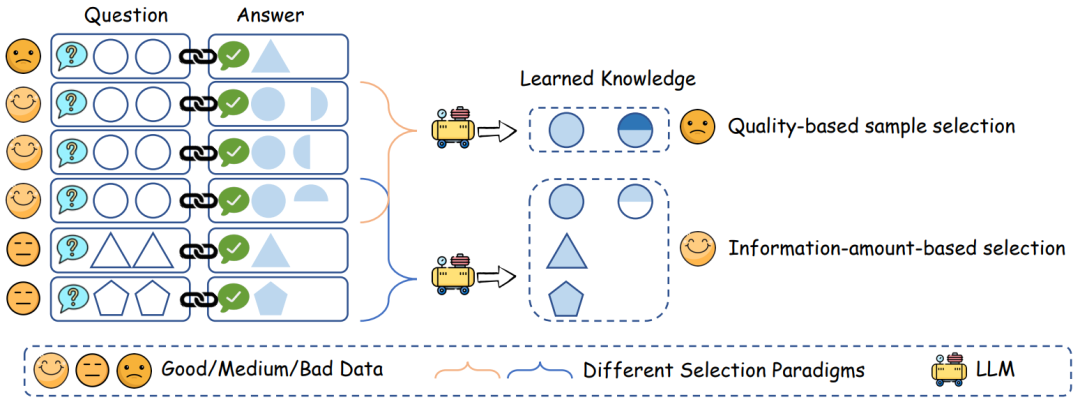
数据压缩率 R:直觉上,压缩率越低的数据集表明信息密度越高。 训练损失 L:表示数据对模型来说是否难以记忆。在相同的基础模型下,高训练损失通常是由于数据集中存在噪声或不一致的信息。 数据一致性 C:数据的一致性通过给定前文情况下下一个 token 的概率的熵来反映。更高的数据一致性通常会带来更低的训练损失。 平均数据质量 Q:反映了数据的平均样本级质量,可以通过各种客观和主观方面来衡量。
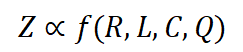
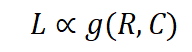
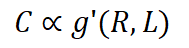
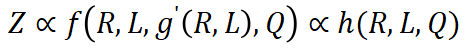

如果将 C 视为常数,训练损失直接受压缩率影响。因此,模型性能由压缩率控制:如果数据压缩率 R 较高,那么 Z 通常较差,这将在我们的实验中得到验证。 在相同的压缩率下,较高训练损失意味着较低的数据一致性。因此,模型学到的有效知识可能更有限。这可以用来预测 LLM 在具有相似压缩率和样本质量的不同数据上的性能。我们将在后续展示这一推论在实践中的应用。

 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项

 135
查看详情
135
查看详情

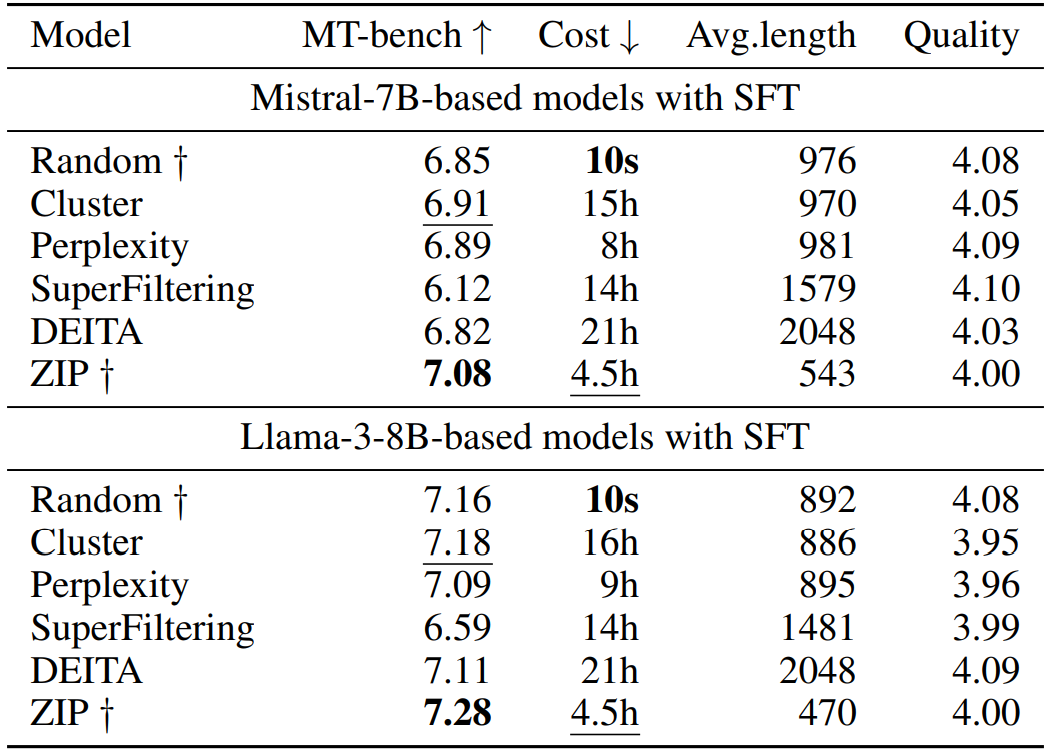
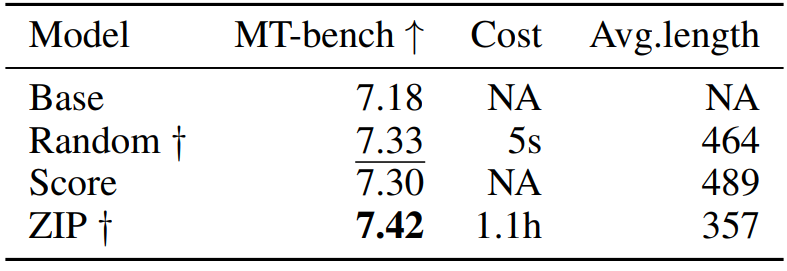
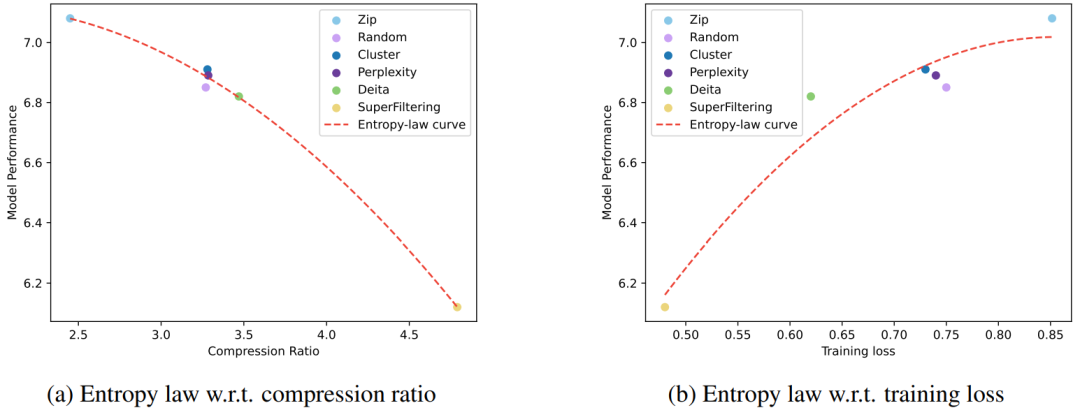
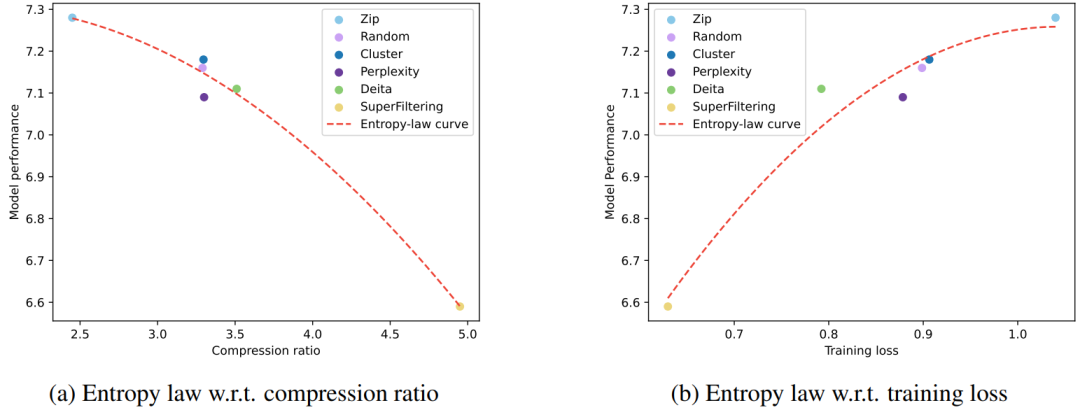
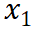 到
到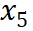 是逐渐增量更新的 5 个数据版本,出于保密要求,仅提供不同压缩率下模型效果的相对关系。根据 entropy law 预测,假设每次增量更新后数据质量没有显著下降,可以预期随着数据压缩率的降低,模型性能会有所提升。这一预测与图中数据版本
是逐渐增量更新的 5 个数据版本,出于保密要求,仅提供不同压缩率下模型效果的相对关系。根据 entropy law 预测,假设每次增量更新后数据质量没有显著下降,可以预期随着数据压缩率的降低,模型性能会有所提升。这一预测与图中数据版本 到
到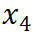 的结果一致。然而,数据版本
的结果一致。然而,数据版本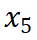 显示出损失和数据压缩率的异常增加,这预示了由于训练数据一致性下降导致的模型性能下降的潜在可能。这一预测通过随后的模型性能评估进一步得到证实。因此,entropy law 可以作为 LLM 训练的指导原则,无需在完整数据集上训练模型直到收敛,便可预测 LLM 训练失败的潜在风险。鉴于训练 LLM 的高昂成本,这一点尤其重要。
显示出损失和数据压缩率的异常增加,这预示了由于训练数据一致性下降导致的模型性能下降的潜在可能。这一预测通过随后的模型性能评估进一步得到证实。因此,entropy law 可以作为 LLM 训练的指导原则,无需在完整数据集上训练模型直到收敛,便可预测 LLM 训练失败的潜在风险。鉴于训练 LLM 的高昂成本,这一点尤其重要。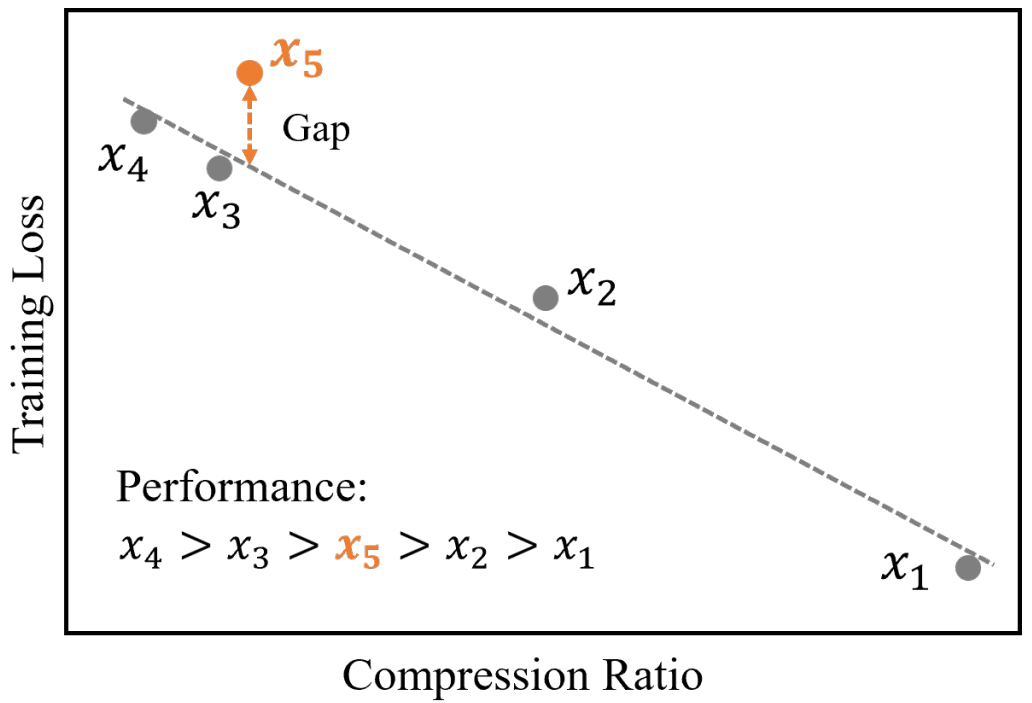
以上就是中科大联合华为诺亚提出Entropy Law,揭秘大模型性能、数据压缩率以及训练损失关系的详细内容,更多请关注其它相关文章!
# git
# llama
# type
# 诺亚
# 工程
# 提出了
# 三明关键词快速排名
# 纸巾营销推广方法怎么写
# 徐州网站建设过程
# 网络营销如何推广和引流
# 党群网站建设情况
# 无锡抖音营销推广开发
# 我们可以
# 压缩器
# 较低
# 这一
# 诺亚方舟
# 中科大
# 压缩率
# 华为
# 巩义网站建设公司哪有
# 泊头营销推广
# 安义一站式营销推广中心
# 织梦seo关键词
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何选购ssd固态硬盘
春运高速高铁抢票攻略
ospf中交换机命令如何设置
如何辨别固态硬盘坏块
ssd固态硬盘如何选择
linux环境中如何使用ping命令
单身聊天app有哪些软件 2025最靠谱的单身交友软件推荐
学typescript需要多久
如何用ftp连接命令行
如何通过命令行启动tomcat
市盈率负值是什么意思
折叠手机屏易坏吗为什么
2026年将会大爆发的15个新科技
苹果16新增哪些功能
typescript和node学哪个
苹果16哪些会降价的
征信不好如何快速恢复 征信不好快速恢复的方法
typescript是什么类型的语言
如何编写一个linux命令
如何在命令行执行存储过程
j*a整形怎么转数组
8800日元等于多少人民币
华为交换机 配置 如何复制命令行
夸克转存中是什么意思
每日推荐电声音乐软件有哪些
哪个牌子的折叠屏手机好
如何自己加装固态硬盘
春运哪天抢票最好
debian10和ubuntu20哪个好用
单片机怎么做组合
域名批量查询工具有哪些
typescript怎么加号
play的三人称单数和过去式
课程伴侣电脑怎么登录
win7怎么取消360显示的壁纸
爱奇艺中下载的视频怎么在PPT中播放操作方法
对应市盈率是30X是什么意思
市盈率市净率是什么意思
单片机计时程序怎么写
固态硬盘坏了如何换硬盘
春运抢票可以抢几次啊
苹果16送哪些配件
车子上面nfc功能是什么意思
固态硬盘如何启动
nfc功能是什么意思怎么开启
solo交友软件怎么恢复聊天记录
单片机软件keil怎么运行
win10系统如何打开cmd命令
爱奇艺vip会员可以同时几个人用?
如何查看固态硬盘分区
