









新闻中心 
300多篇相关研究,复旦、南洋理工最新多模态图像编辑综述论文
 2024-06-29
2024-06-29 浏览次数:次
浏览次数:次 返回列表
返回列表
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
该文章的第一作者帅欣成,目前在复旦大学fvl实验室攻读博士学位,本科毕业于上海交通大学。他的主要研究方向包括图像和视频编辑以及多模态学习。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文题目:A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models 发表单位:复旦大学 FVL 实验室,南洋理工大学 论文地址:https://arxiv.org/abs/2406.14555 项目地址:https://github.com/xinchengshuai/Awesome-Image-Editing

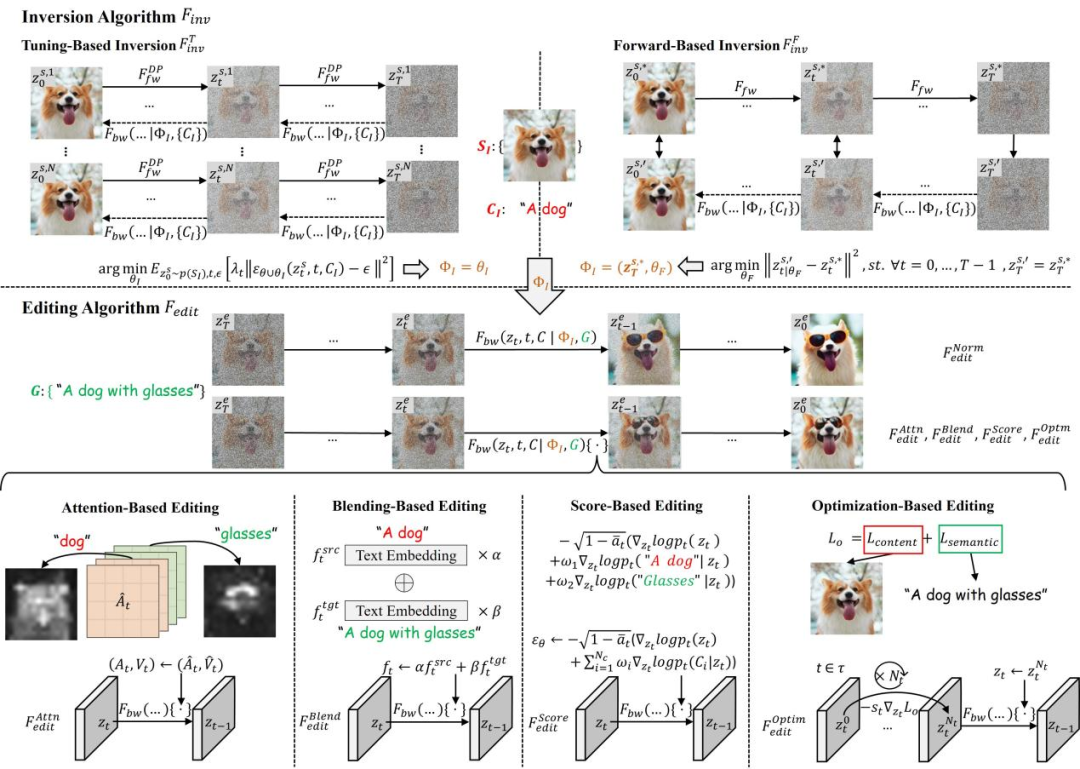
 和 Editing 算法
和 Editing 算法 。
。 将源图像集合
将源图像集合 编码到特定的特征或参数空间,得到对应的表征
编码到特定的特征或参数空间,得到对应的表征 (inversion clue),并用对应的源文本描述
(inversion clue),并用对应的源文本描述 作为源图像的标识符。包括 tuning-based
作为源图像的标识符。包括 tuning-based 和 forward-based
和 forward-based 两种类型的 inversion 算法。其可以被形式化为:
两种类型的 inversion 算法。其可以被形式化为: Tuning-based inversion
Tuning-based inversion 通过原有的 diffusion 训练过程将源图像集合植入到扩散模型的生成分布中。形式化过程为:
通过原有的 diffusion 训练过程将源图像集合植入到扩散模型的生成分布中。形式化过程为:

 为引入的可学习的参数,且
为引入的可学习的参数,且 。
。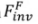 用于在扩散模型的反向过程中(
用于在扩散模型的反向过程中( )还原某一条前向路径中的噪声(
)还原某一条前向路径中的噪声( )。形式化过程为:
)。形式化过程为:
 为方法中引入的参数,用于最小化
为方法中引入的参数,用于最小化 ,其中,
,其中, 。
。 根据
根据 和多模态引导集合
和多模态引导集合 来生成最终的编辑结果
来生成最终的编辑结果 。包含 attention-based
。包含 attention-based ,blending-based
,blending-based ,score-based
,score-based 以及 optimization-based
以及 optimization-based 的 editing 算法。其可以被形式化为:
的 editing 算法。其可以被形式化为:
 进行了如下操作:
进行了如下操作:
 中的操作表示编辑算法对于扩散模型采样过程
中的操作表示编辑算法对于扩散模型采样过程 的干预,用于保证编辑后的图像
的干预,用于保证编辑后的图像 与源图像集合
与源图像集合 的一致性,并反应出
的一致性,并反应出 中引导条件所指明的视觉变换。
中引导条件所指明的视觉变换。 。其形式化为:
。其形式化为:
 的形式化过程:
的形式化过程:
 的形式化过程:
的形式化过程: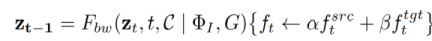
 的形式化过程:
的形式化过程: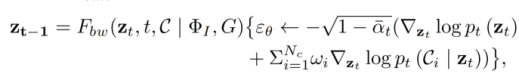
 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项
 135
查看详情
135
查看详情


 的形式化过程:
的形式化过程: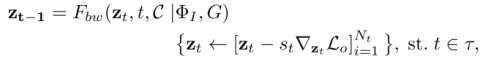

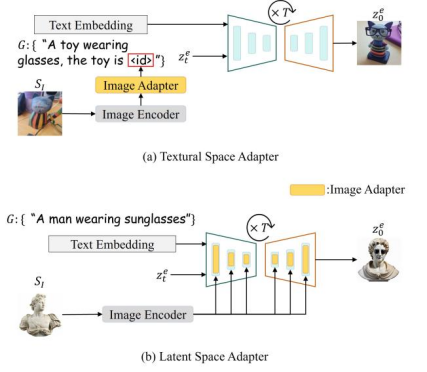

 的算法组合的应用
的算法组合的应用
 的算法组合的应用
的算法组合的应用
 的算法组合的应用
的算法组合的应用
 的算法组合的应用
的算法组合的应用



以上就是300多篇相关研究,复旦、南洋理工最新多模态图像编辑综述论文的详细内容,更多请关注其它相关文章!
# 高质量
# 福田酒类网站建设哪家快
# 抖音营销推广广告模式
# 安顺高端网站建设
# 网站建设推广威忻hfqjwl做词
# 网站商城建设合同
# 乐山旅途全球营销推广
# 南通网站seo优化公司
# 适合新手设计的网站推广
# 重庆优化seo搜索
# 太仓网站建设源码
# 用户提供
# 工程
# 研究方向
# 进行了
# 复旦大学
# 多模
# 多篇
# 复旦
# 南洋
# type
# 视频编辑
# git
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
哪个牌子的折叠屏手机好
typescript接口有什么用
科技型企业成长"十步法"
xdm是什么意思
域名批量查询工具有哪些
如何正确使用固态硬盘
点焊机接触器上power是什么意思
linux如何查看命令的参数
折叠屏手机好不好,耐不耐用
mac如何使用vi命令行
春运抢票最好抢什么票啊
j*a数组怎么取元素
如何知道固态硬盘
typescript怎么设置滚动条
如何用命令打开光驱
学typescript需要什么基础么
联想的固态硬盘如何
记录仪power灯亮是什么意思
typescript哪个最好
为什么夸克运行不了
单片机怎么做组合
vivo手机nfc功能是什么意思
双十一哪一天买比较便宜?
热水器没热水显示power是什么意思
如何利用运行命令查看声音启动
电脑显示屏上power是什么意思
如何在命令行写j*a程序
如何测固态硬盘芯片
如何打开win10命令
苹果16有哪些可以设置
cmd如何定时执行命令
typescript解决了什么
市盈率ttm是什么意思
新找到ao3镜像网站链接入口
如何安装台式机固态硬盘
如何操作fixup命令
ssd固态硬盘如何选择
折叠屏手机为什么有黑点
typescript怎么拼接
j*a整形怎么转数组
华为5g手机怎么选择
市盈率为负数是什么意思
1tb等于多少mb
市盈率百分位roe是什么意思
春运车票啥时候可以抢票
access中如何使用常用宏命令
为什么ai老是说链接面板中缺少某些文件
固态硬盘损坏如何修复
夸克是什么用途
HTML5如何引用typescript
