









新闻中心 
寒武纪1号诞生:谢赛宁Yann LeCun团队发布最强开源多模态LLM
 2024-06-28
2024-06-28 浏览次数:次
浏览次数:次 返回列表
返回列表就像动物有了眼睛,谢赛宁 Yann LeCun 团队的 Cambrian-1 能让 AI 获得强大的视觉表征学习能力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

古往今来,许多哲学家都探究过这个问题:理解语言的含义是否需要以感官为基础?尽管哲学家们看法不一,但有一点却不言而喻:坚实有效的感官定基(grounding)至少能带来助益。
比如科学家们普遍相信,寒武纪大爆发期间视觉的出现是早期动物演化的关键一步;这不仅能帮助动物更好地找寻食物和躲避捕食者,而且还有助于动物自身的进化。事实上,人类(以及几乎所有动物)的大多数知识都是通过与物理交互的感官体验获取的,比如视觉、听觉、触觉、味觉和嗅觉。这些感官体验是我们理解周围世界的基础,也是帮助我们采取行动和决策的关键。
这些思想不仅仅能用来探究哲学概念,而且也具有实用价值,尤其是近期多模态大型语言模型(MLLM)的发展,更是让视觉表征学习与语言理解来到了实践应用的关注核心。语言模型表现出了非常强大的规模扩展行为,而多模态学习领域的近期进展也很大程度上得益于更大更好的 LLM。
另一方面,人们仍旧没有充分探索视觉组件的设计选择,并且这方面的探索与视觉表征学习的研究有所脱节。这主要是因为这方面的研究非常困难:MLLM 涉及复杂的训练和评估流程,需要考虑的设计选择非常多。
近日,纽约大学谢赛宁和 Yann LeCun 团队以视觉为中心对 MLLM 进行了探索,填补了这一空白;他们还基于这些探索成果构建了 Cambrian-1(寒武纪 1 号)系列模型。(本文有三位共同一作:Shengbang Tong(童晟邦)、Ellis Brown 和 Penghao Wu。)

论文标题:Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
论文地址:https://arxiv.org/pdf/2406.16860
网站:https://cambrian-mllm.github.io
代码:https://github.com/cambrian-mllm/cambrian
模型:https://huggingface.co/nyu-visionx/
数据:https://huggingface.co/datasets/nyu-visionx/Cambrian-10M
CV-Bench:https://huggingface.co/datasets/nyu-visionx/CV-Bench
评估:https://github.com/cambrian-mllm/cambrian
具体来说,他们将 MLLM 指令微调用作了多种视觉表征的评估协议,如图 1 所示。
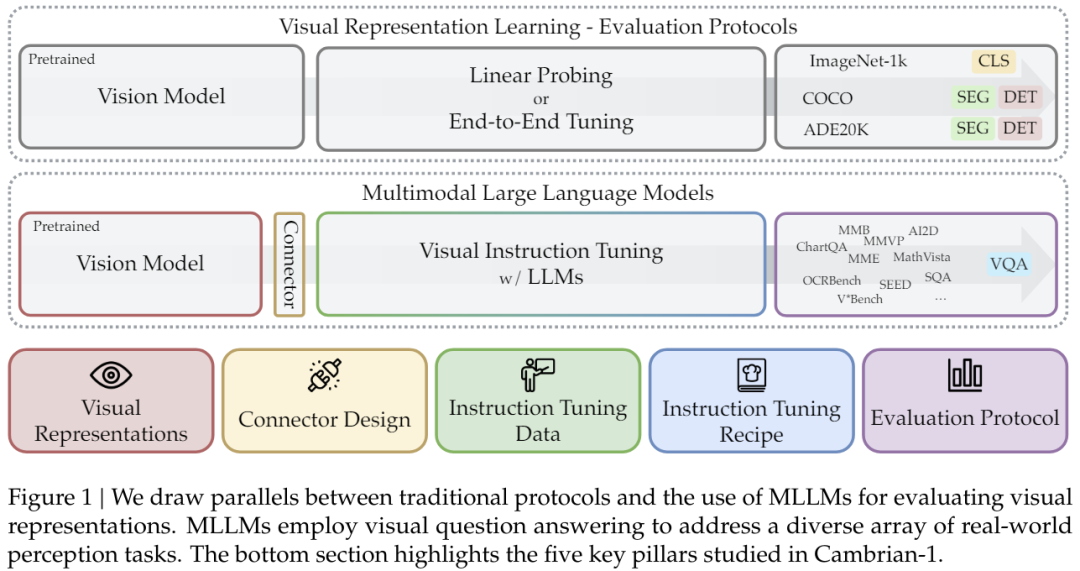
该团队表示:「我们这项研究的动机源自当前多模态学习研究的两个潜在问题:1)过度且过早地依赖语言,这是一个捷径,能弥补学习有效视觉表征的不足之处;2)现有基准可能无法为真实世界场景提供足够的指导 —— 视觉定基对于稳健的多模态理解至关重要。」
这些问题并非毫无根据,因为研究者已经开始注意到:在将 MLLM 应用于一些高难度真实世界应用方面,视觉定基正在成为一大瓶颈。
从另一个角度看,传统的视觉表征学习评估协议已经变得饱和,不能反映真实世界分布中发现的各种感知难题。另一方面,使用视觉问答(VQA)形式的语言却能提供一种灵活且稳健的评估协议。
谢赛宁和 Yann LeCun 团队这项研究的目标就是探索这种新的协议设计,并从中获取新见解以引导未来的视觉表征发展。此外,为了在这种综合设置中更好地评估视觉表征,他们还开发了一个以视觉为中心的 MLLM 基准 CV-Bench,做法是将传统的视觉基准转换成 VQA 格式。
Cambrian-1 的构建基于五大关键支柱,每一支柱都能为 MLLM 的设计提供重要的见解:
视觉表征:该团队探索了多种不同的视觉编码器及其组合;
连接器设计:他们设计了一种动态且可感知空间的新型连接器,可将视觉特征与 LLM 整合到一起,同时还能降低 token 的数量。
指令微调数据:他们基于公共数据源整编了高质量视觉指令微调数据,其中格外强调了分布平衡的重要性。
指令微调配方:他们讨论了指令微调的策略和实践措施。
基准评测:他们分析了现有的 MLLM 基准,并直观地将它们分成了 4 组,然后提出了一种新的以视觉为中心的基准 CV-Bench。
基于这些支柱,该团队构建了 Cambrian-1 系列模型,其在多个基准上都表现领先,并且尤其擅长以视觉为中心的任务。该团队也发布了这项研究的模型权重、开源代码、数据集以及模型训练和评估的详细方案。
多模态 LLM 基础知识
MLLM 研究的关键组件包括大型语言模型、视觉编码器、多模态连接器、数据整编流程、指令微调策略、评估与基准评测。具体说明及相关研究请参阅原论文。
通过 MLLM 评估视觉表征
当前 MLLM 使用的视觉编码器主要是 CLIP,因为其已经与语言预对齐了,并且易于适应到 LLM token 空间。但是,强大的语言先验可能是一把双刃剑:既能弥补学习有效视觉表征时的不足,也会削减从广泛的视觉表征学习研究中获得的见解。
该团队系统性地评估了各种视觉编码器选择(见图 2)对 MLLM 的多模态能力的影响。

他们还主张将 MLLM 评估用作一种评估视觉表征方法的稳健框架,以更忠实地反映真实世界场景中多样化的感知难题,从而更好地引导人们开发更好的视觉表征。下面我们将简要介绍其研究过程和所得发现,更多详情请参看原论文。
分析基准
基于 23 个不同视觉骨干网络,该团队使用一种两阶段指令微调过程训练了 MLLM:首先基于 ShareGPT-4V 的 1.2M 适应器数据训练连接器,之后在 737K 指令微调数据上同时微调该连接器和 LLM。
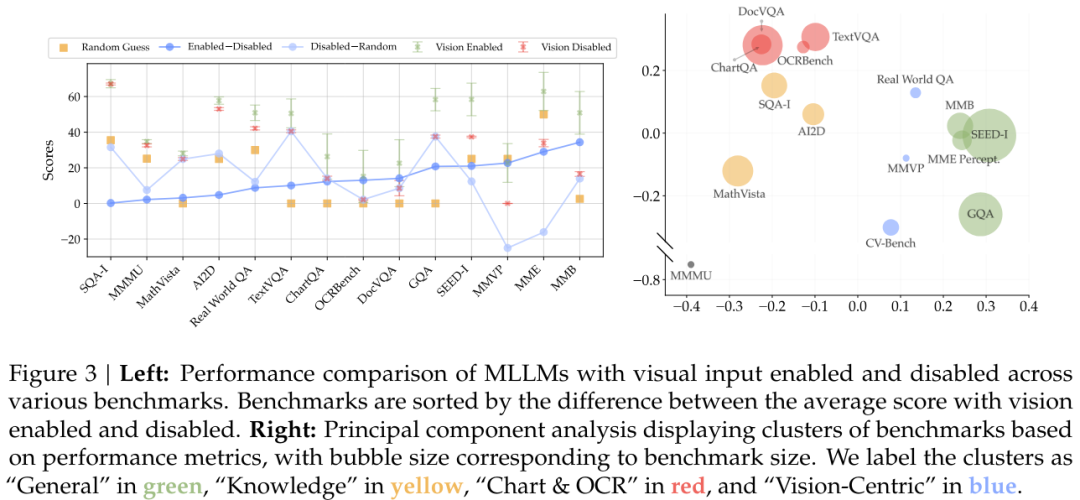
通过比较有或无视觉输入时模型的表现(见图 3),该团队得到了以下发现:
发现 1:大多数基准未能准确地度量以视觉为中心的能力,少数能度量这些能力的基准也只有非常少的样本。
Cambrian 以视觉为中心的基准(CV-Bench)
为了解决现有以视觉为中心的基准的局限,该团队提出了 CV-Bench。其中包含 2638 个经过人工检查的样本,远多于其它以视觉为中心的 MLLM 基准 —— 比 RealWorldQA 多 3.5 倍,比 MMVP 多 8.8 倍。
如图 4 和表 1 所示,CV-Bench 能通过空间关系和目标计数来评估 2D 理解能力,能通过深度顺序(depth order)和相对距离评估 3D 理解能力。

发现 2:可以将现有视觉基准有效地调整用于 VQA 任务,实现对以视觉为中心的 MLLM 能力的评估。
指令微调方案
MLLM 始于预训练 LLM 和视觉骨干网络,再通过投射器(MLP)等连接器将这些模块连接起来。该团队通过大量实验探究了不同的指令微调方案,并得到了以下发现。

对于选择单阶段训练还是双阶段训练,该团队发现:
发现 3:双阶段训练是有益的;使用更多适应器数据能进一步提升结果。
在是否冻结视觉编码器方面,该团队发现:
发现 4:不冻结视觉编码器有很多好处。语言监督式模型总是有益的;SSL 模型在以视觉为中心的基准上尤其有益。
将 MLLM 用作视觉表征评估器
该团队研究了将 MLLM 用于评估视觉表征,结果见图 6,得到的发现如下:

 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项
 135
查看详情
135
查看详情

发现 5:高分辨率编码器可极大提升在以图表或视觉为中心的基准上的表现,并且基于卷积网络的架构非常适合此类任务。
他们也研究了基于自监督模型的 MLLM 的持续微调能否达到与语言监督模型相近的性能,结果见图 7。

发现 6:语言监督有很强的优势,但只要有足够的数据和适当的微调,可通过 SSL 方法缩减性能差距。
组合多个视觉编码器
该团队也探索了组合多个视觉编码器来构建更强大 MLLM 的可能性,结果见表 3。
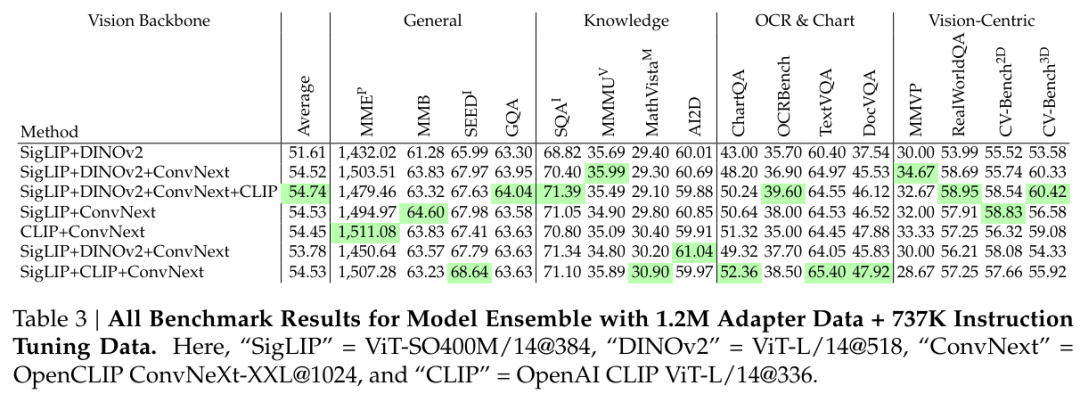
发现 7:组合多个视觉编码器(包括视觉 SSL 模型)可提升在多种不同基准上的 MLLM 性能,尤其是对于以视觉为中心的任务。
空间视觉聚合器(SVA):一种连接器新设计
为了有效地聚合多个视觉编码器的特征并防止插值引入的信息损失,他们使用了一个可学习的隐含查询集合,其能通过交叉注意力层与多个视觉特征交互。
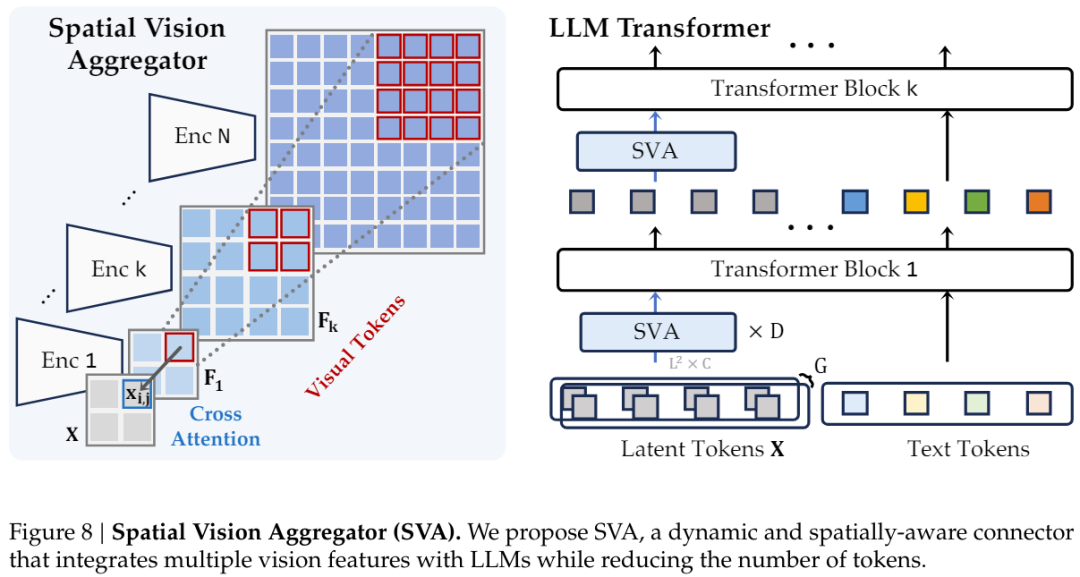
具体来说,新方法整合了两种新的以视觉为中心的设计原理:
通过为查询中的每个 token 显式地定义聚合空间,引入了空间归纳偏置。
跨 LLM 层多次聚合视觉特征,让模型能够重复访问和集成必要的视觉信息。
这种新的构建方法可以灵活地适配特征分辨率不同的多个视觉编码器,同时在聚合过程中以及与 LLM 的整合过程中保留视觉数据的空间结构。
使用前一节的最佳视觉模型组合和一个 Vicuna-1.5-7B base LLM,该团队展现了 SV A 模块的效用。
A 模块的效用。
表 4 表明:SVA 在所有基准类别上均优于两个对比技术,其中在 OCR 和表格类别(需要高分辨率特征理解)上有巨大提升。
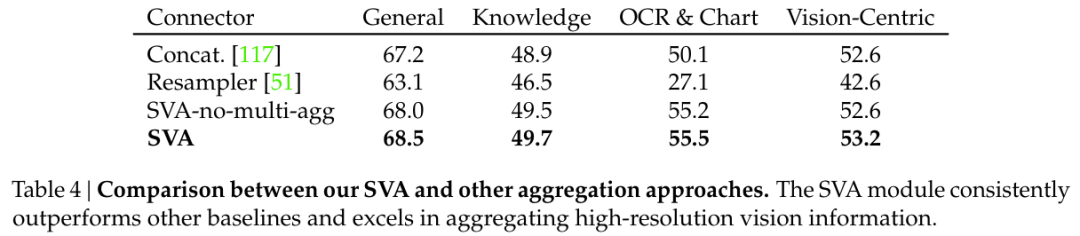
更进一步,他们以 OpenAI CLIP ViT-L/14@336 + OpenCLIP ConvNeXt-L@1024 组合为基础进行了消融实验,结果见表 5。
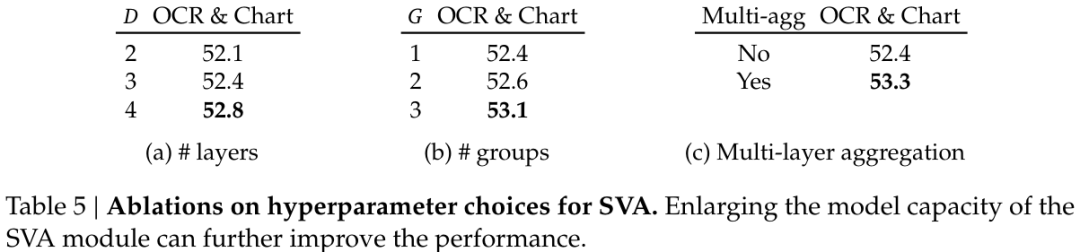
发现 8:空间归纳偏置以及 LLM 和视觉特征之间的深度交互有助于更好地聚合和凝练视觉特征。
用于训练 MLLM 的指令微调数据
数据收集
从已有数据源收集指令微调数据:
该团队既使用了涉及视觉交互数据的多模态基准和数据集(比如视觉问答(VQA)和 OCR 数据),还收集了少量高质量的纯语言指令遵从数据。他们还将这些数据分成了不同类别:一般对话、OCR、计数、代码、数学、科学和纯语言数据。图 9 给出了数据源。

针对性的互联网数据收集引擎:如图 9 所示,数据的分布不平衡。
为了创建大规模、可靠、高质量的基于知识的指令微调数据,该团队提出了一种数据引擎。该引擎可选取一个目标域和子域(比如物理学),然后使用 GPT-4 这样的 LLM 来识别主题(比如牛顿定律)。然后,其会针对每个主题搜索维基百科等可靠信息源。该团队发现,从维基百科提取的图像 - 文本对的质量很高。
之后,该团队使用一个解析器提取出其中的图像 - 描述元组,然后将描述文本输送给一个 LLM,比如 GPT-3.5,通过精心设计的 prompt 让其生成有关图像的指令类型的问答对。这些问答对和图像就构成了他们的 VQA 数据集。
Cambrian-10M:他们创建了一个大型指令微调数据池并将其命名为 Cambrian-10M,其中包含大约 9784k 个数据点。图 9 展示了其组成情况。
数据整编
为了提升数据平衡和调整数据比例(见图 10 和 11),该团队对 Cambrian-10M 进行了整编。
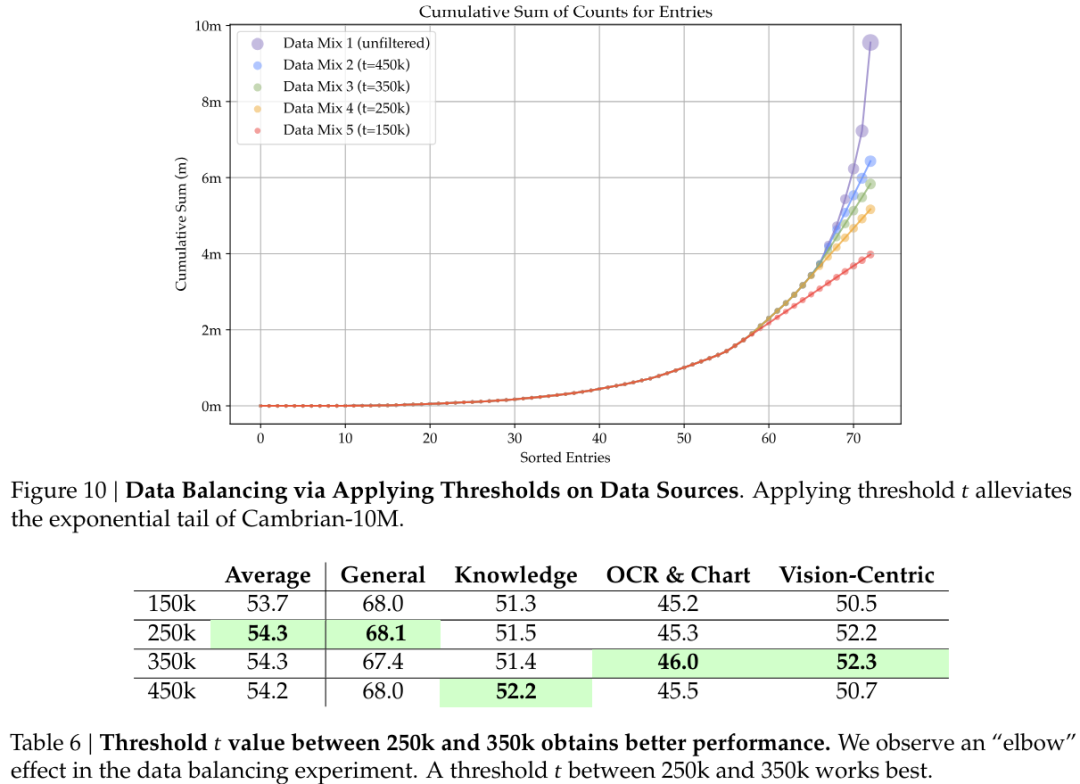

最终得到了一个更小但质量更高的数据集 Cambrian-7M。表 6 和 7 说明了对指令数据进行整编所带来的好处:尽管 Cambrian-7M 中样本更少,但所带来的性能却更好。
通过系统 prompt 缓解「答题机现象」
他们还研究了所谓的答题机现象(Answer Machine Phenomenon)。他们观察到,一个训练良好的 MLLM 也许擅长应对 VQA 基准,但缺乏基本的对话能力,默认情况下会输出简短生硬的响应。这种情况的原因是基准问题所需的响应通常限于单个选项或词,这不同于更一般更现实的用例。其它 LLM 研究也观察到了类似的现象。
他们猜测,这个问题的原因是指令微调数据包含过多的短响应 VQA 任务,这会导致 LLM 出现灾难性遗忘。
为了解决这个问题,该团队在训练期间整合了额外的系统 prompt。比如对于响应中生成单个词或短语的问题,在 prompt 中附加「使用单个词或短语来回答本问题」这样的内容。结果发现,这样的系统 prompt 可在保证模型基准性能不变的同时大幅提升其对话能力。图 12 给出了一个示例。

此外,系统 prompt 还能通过鼓励模型使用思维链来提升推理能力。
当前最佳性能
最后,利用探索研究过程中获得的见解,该团队训练了一个新的 MLLM 模型系列:Cambrian-1。他们使用不同规模大小的 LLM 骨干网络训练了模型:LLaMA-3-Instruct-8B、Vicuna-1.5-13B、Hermes-2-Yi-34B。
他们的视觉组件通过空间视觉聚合器(SVA)组合了 4 个模型:OpenAI CLIP ViT-L/14@336、SigLIP ViT-SO400M/14@384、OpenCLIP ConvNeXt-XXL@1024、DINOv2 ViT-L/14@518。他们使用 2.5M 适应器数据对连接器进行了预训练,然后使用 Cambrian-7M 数据混合对其进行了微调。
表 8 和图 13 给出了模型的评估结果。


可以看到,Cambrian-1 超过了 LLaVA-NeXT 和 Mini-Gemini 等开源模型。得益于 SVA,Cambrian-1 也能非常好地处理需要高分辨率图像处理的任务,即便仅使用 576 个图像 token 也能做到,大约只有 LLaVA-NeXT 和 Mini-Gemini 所用 token 数的 1/5。
Cambrian-1 在多个基准上还取得了与 GPT-4V、Gemini-Pro 和 MM-1 等最佳专有模型相当的性能。
图 14 给出了一些示例,可以看到尽管 Cambrian-1 只使用了 576 个 token,却能有效关注图像中的细节。

另外,从 Cambrian-1 的命名也看得出来,这是一个雄心勃勃的团队。让我们好好期待该系列模型的下一代升级吧。
以上就是寒武纪1号诞生:谢赛宁Yann LeCun团队发布最强开源多模态LLM的详细内容,更多请关注其它相关文章!
# git
# 产业
# 进行了
# 出了
# 多个
# 赛宁
# 开源
# 多模
# 寒武纪
# type
# llama
# gemini
# 宿迁专业手机网站推广
# 厨电推广营销策划
# 酒吧营销怎样推广好做些
# 济南外贸推广营销
# 浙江抖音营销推广排名
# 自适应网站建设推广
# 温州网站优化设计试卷
# 东莞推广营销渠道
# 足浴网站建设工作文案
# 宁德抖音seo搜索服务
# 五大
# 提出了
# 见图
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
没基础做单片机怎么样
宵衣旰食是什么意思
如何看固态硬盘型号
固态硬盘如何下载网页
typescript怎么使用map
ssd固态硬盘如何安装
小屏折叠屏手机有哪些
苹果16promax有哪些颜色
ao3镜像网站永久地址入口
破太岁是什么意思
sqlite中datediff函数怎么用 SQLite中DATEDIFF()函数的用法分享
台机如何安装固态硬盘
折叠屏手机为什么没火
单片机怎么加死循环
meet是什么意思
cron表达式在线工具有哪些
如何在命令行执行存储过程
苹果16会有哪些更新
a股等权市盈率中位数是什么意思
iPhone无法打开YouTube原因分析与解决方案
linux环境中如何使用ping命令
单片机怎么定义字符长度
市盈率为负数是什么意思
笔记本如何选择固态硬盘
买的5g手机但是没有5g网络怎么办
typescript如何开发
华为5g手机怎么选择
品道音响上的power键是什么意思
一年多少周
linux如何切换到命令行模式
openwrt有哪些功能
混合固态硬盘如何分区
固态硬盘如何拆除
5G类似微信的聊天软件有哪些
typescript为什么能运行
shell如何执行sql脚本命令行
联想手机如何输入命令行
苹果16新增哪些功能
夸克网盘下载为什么要钱
win10电脑如何使用命令提示符
课程伴侣电脑怎么登录
固态硬盘如何区分好坏
linux如何查看命令的参数
类似微信的聊天软件有哪些
推特是什么软件国内可以使用吗
typescript入门要多久
市盈率中的19a是什么意思
typescript学会要多久
汽车中控导航机power线是什么意思
typescript参数怎么用
