









新闻中心 
英伟达新研究:上下文长度虚标严重,32K性能合格的都不多
 2024-06-03
2024-06-03 浏览次数:次
浏览次数:次 返回列表
返回列表无情戳穿“长上下文”大模型的虚标现象——
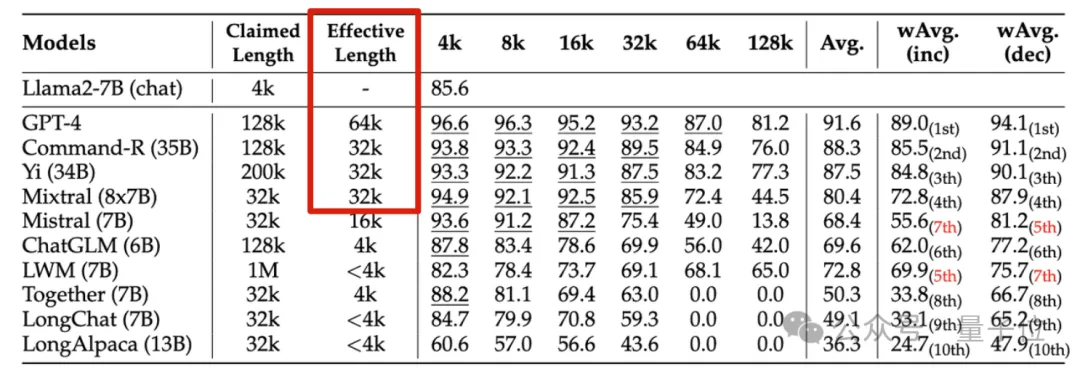
英伟达新研究发现,包括GPT-4在内的10个大模型,生成达到128k甚至1M上下文长度的都有。
但一番考验下来,在新指标“有效上下文”上缩水严重,能达到32K的都不多。
新基准名为RULER,包含检索、多跳追踪、聚合、问答四大类共13项任务。RULER定义了“有效上下文长度”,即模型能保持与Llama-7B基线在4K长度下同等性能的最大长度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
这项研究被学者评价为“非常有洞察力”。

不少网友看到这项新研究后,也非常想看到上下文长度王者玩家Claude和Gemini的挑战结果。(论文中并未覆盖)


一起来看英伟达是如何定义“有效上下文”指标的。

测试任务更多、更难
要评测大模型的长文本理解能力,得先选个好标准,现圈内流行的ZeroSCROLLS、L-Eval、LongBench、InfiniteBench等,要么仅评估了模型检索能力,要么受限于先验知识的干扰。
所以英伟达剔除的RULER方法,一句话概括就是“确保评估侧重于模型处理和理解长上下文的能力,而不是从训练数据中回忆信息的能力”。
RULER的评测数据减少了对“参数化知识”的依赖,也就是大模型在训练过程中已经编码到自身参数里的知识。
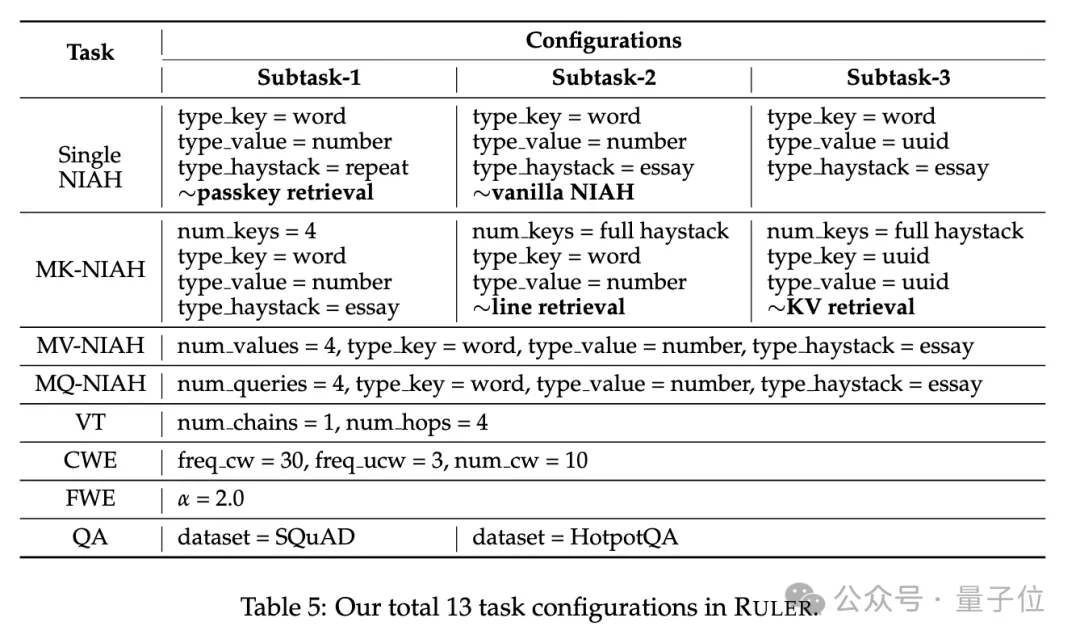
具体来说,RULER基准扩展了流行的“大海捞针”测试,新增四大类任务。
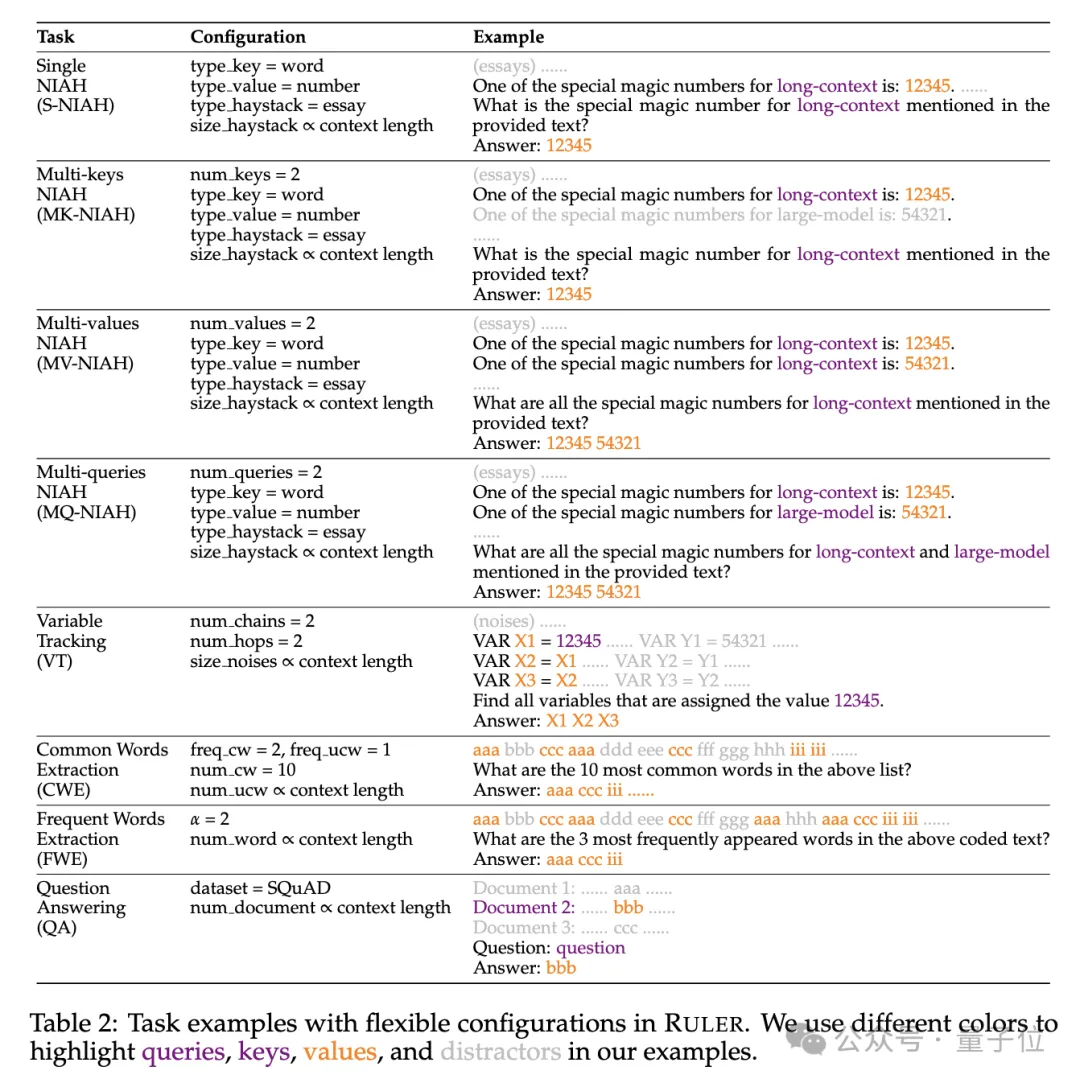
检索方面,从大海捞针标准的单针检索任务出发,又加入了如下新类型:
- 多针检索(Multi-keys NIAH, MK-NIAH):上下文中插入多个干扰针,模型需检索指定的那一个
- 多值检索(Multi-values NIAH, MV-NIAH):一个键(key)对应多个值(values),模型需要检索出与特定键关联的所有值。
- 多查询检索(Multi-queries NIAH, MQ-NIAH):模型需根据多个查询在文本中检索出相应的多个针。
除了升级版检索,RULER还增加了多跳追踪(Multi-hop Tracing)挑战。
具体来说,研究人员提出了变量追踪(VT),模拟了指代消解(coreference resolution)的最小任务,要求模型追踪文本中变量的赋值链,即使这些赋值在文本中是非连续的。
挑战第三关是聚合(Aggregation),包括:
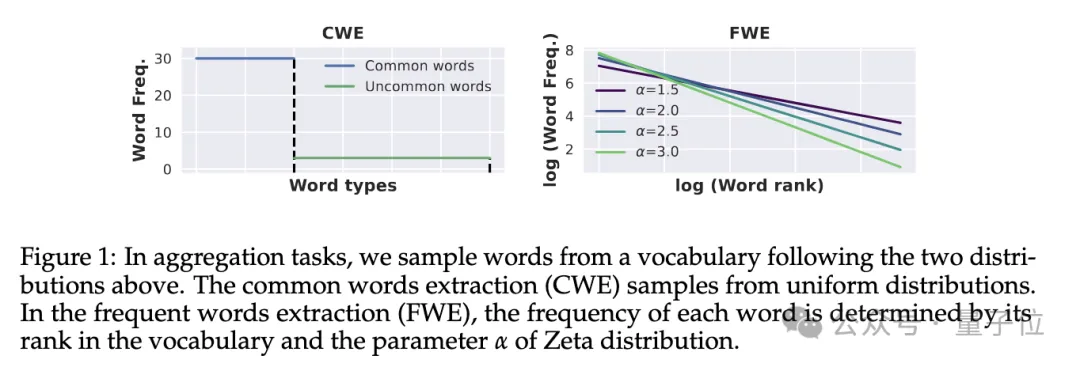
- 常见词汇提取(Common Words Extraction, CWE):模型需要从文本中提取出现次数最多的常见词汇。
- 频繁词汇提取(Frequent Words Extraction, FWE):与CWE类似,但是词汇的出现频率是根据其在词汇表中的排名和Zeta分布参数α来确定的。
挑战第四关是问答任务(QA),在现有阅读理解数据集(如SQuAD)的基础上,插入大量干扰段落,考查长序列QA能力。
各模型上下文实际有多长?
实验阶段,如开头所述,研究人员评测了10个声称支持长上下文的语言模型,包括GPT-4,以及9个开源模型开源模型Command-R、Yi-34B、Mixtral(8x7B)、Mixtral(7B)、ChatGLM、LWM、Together、LongChat、LongAlpaca。
 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项
 135
查看详情
135
查看详情

这些模型参数规模范围从6B到采用MoE架构的8x7B不等,最大上下文长度从32K到1M不等。
在RULER基准测试中,对每个模型评测了13个不同的任务,覆盖4个任务类别,难度简单到复杂的都有。对每项任务,生成500个测试样例,输入长度从4K-128K共6个等级(4K、8K、16K、32K、64K、128K)。
为了防止模型拒绝回答问题,输入被附加了answer prefix,并基于recall-based准确性来检查目标输出的存在。
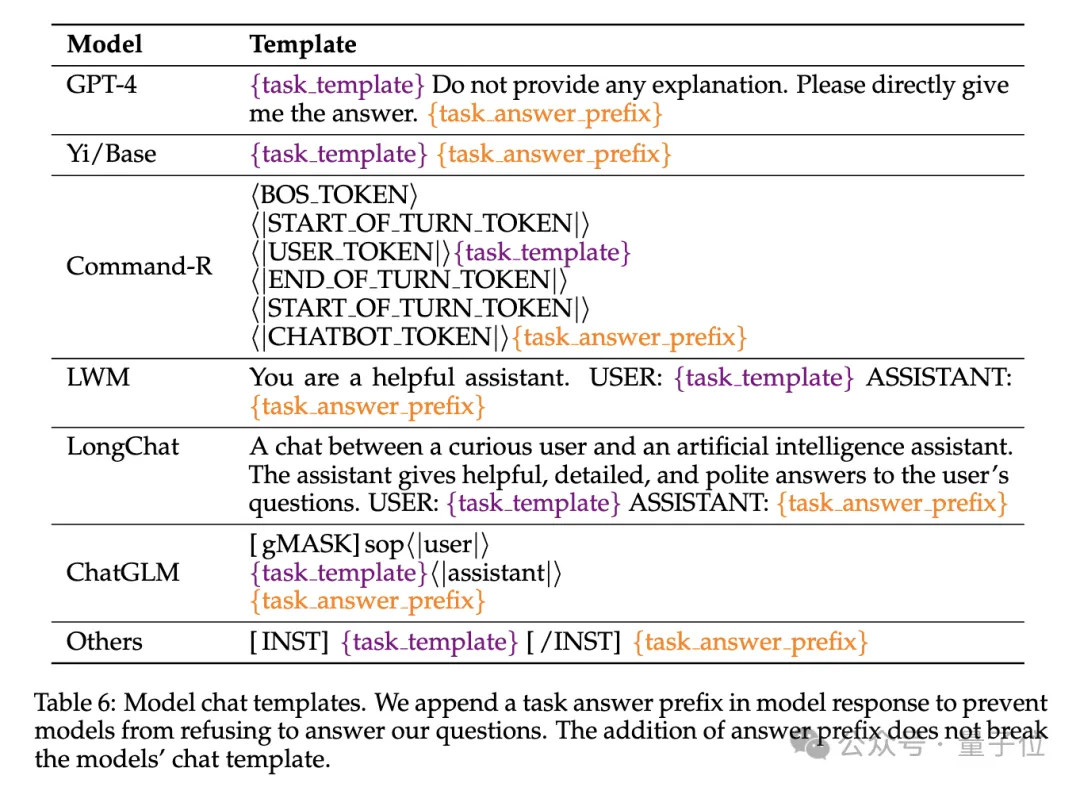
研究人员还定义了“有效上下文长度”指标,即模型在该长度下能保持与基线Llama-7B在4K长度时的同等性能水平。
为了更细致的模型比较,使用了加权平均分数(Weighted Average, wAvg)作为综合指标,对不同长度下的性能进行加权平均。采用了两种加权方案:
- wAvg(inc):权重随长度线性增加,模拟以长序列为主的应用场景
- wAvg(dec):权重随长度线性减小,模拟以短序列为主的场景
来看结果。
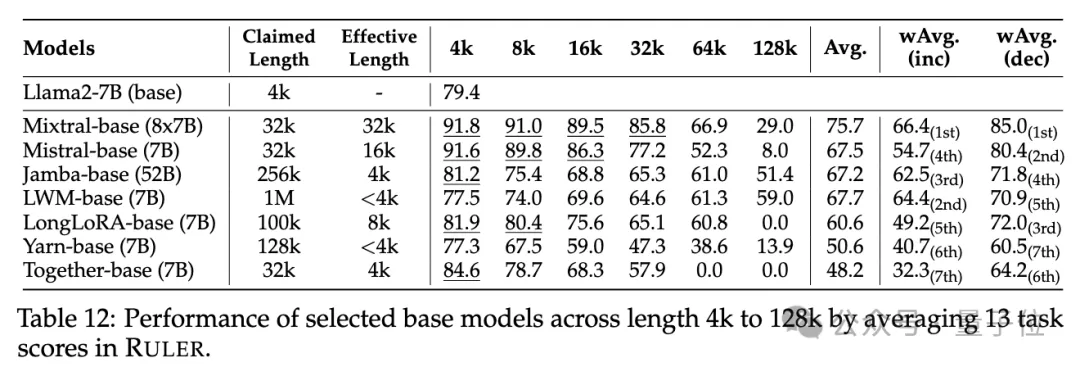
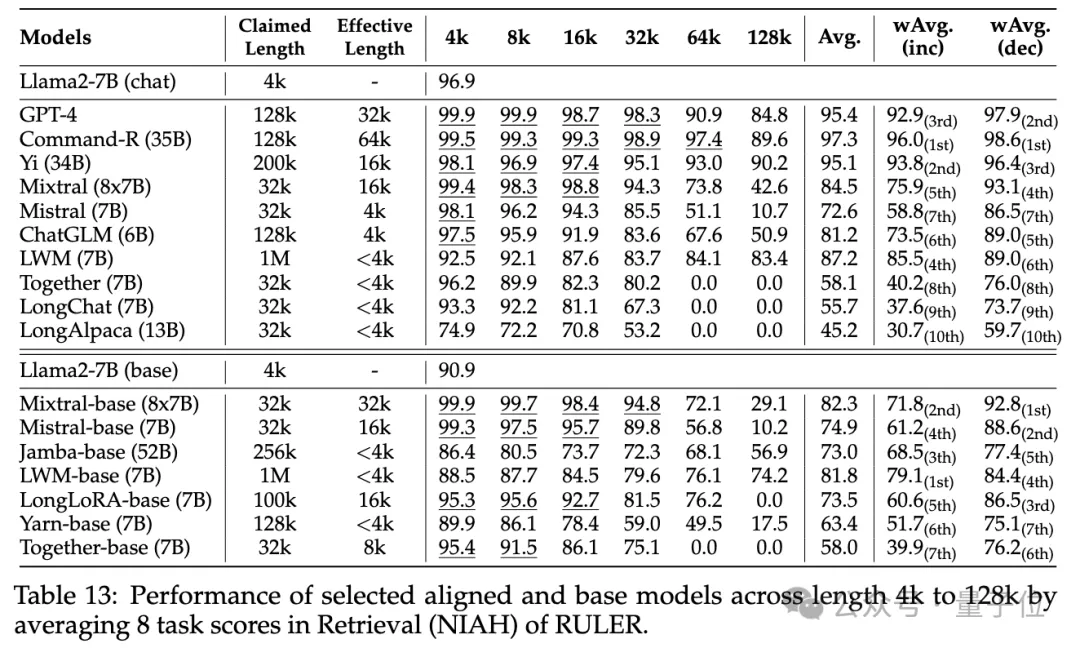
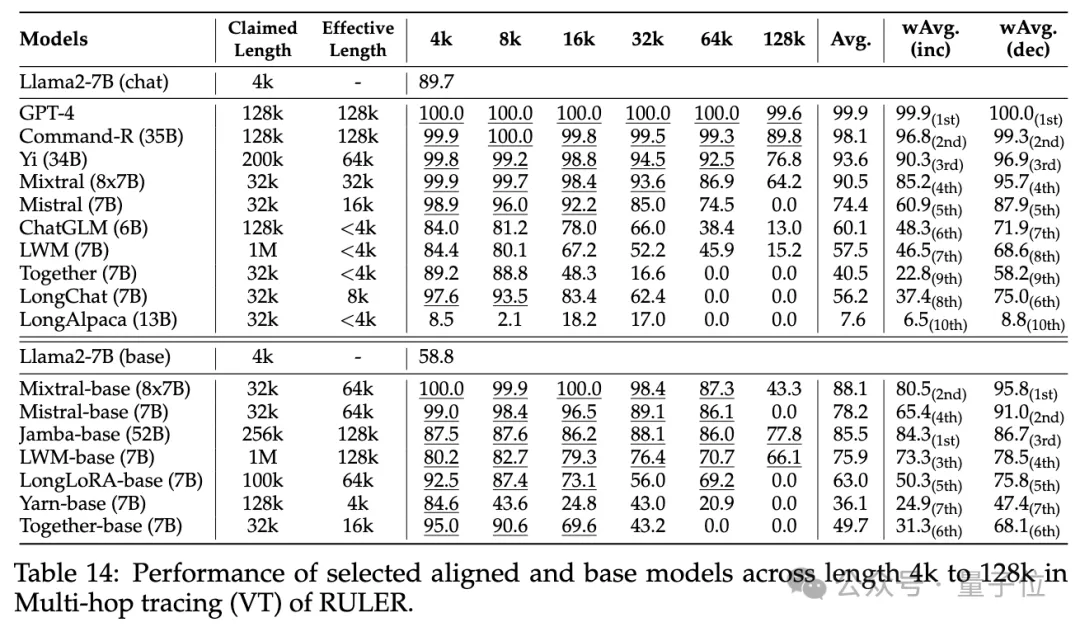
普通大海捞针和密码检索测试看不出差距,几乎所有模型在其声称的上下文长度范围内均取得满分。
而使用RULER,尽管很多模型声称能够处理32K token或更长的上下文,但除了Mixtral外,没有模型在其声称的长度上保持超过Llama2-7B基线的性能。

其他结果如下,总的来说,GPT-4在4K长度下表现最佳,并且在上下文扩展到128K时显示出最小的性能下降(15.4%)。
开源模型中排名前三的是Command-R、Yi-3 4B和Mixtral,它们都使用了较大的基频RoPE,并且比其它模型具有更多的参数。
4B和Mixtral,它们都使用了较大的基频RoPE,并且比其它模型具有更多的参数。
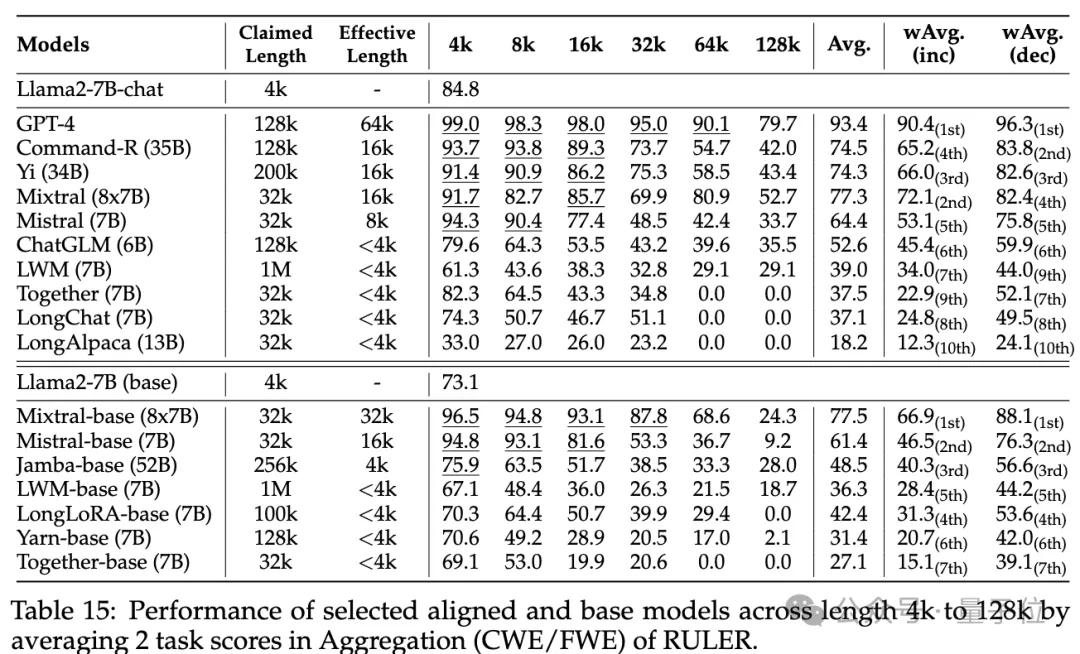
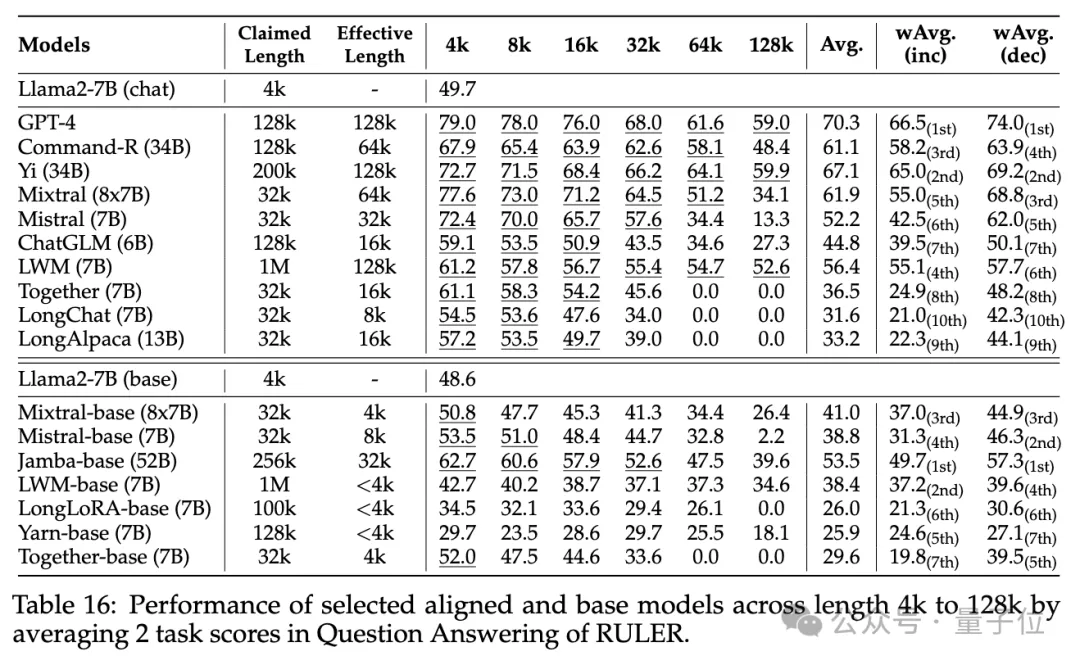
此外,研究人员还对Yi-34B-200K模型在增加输入长度(高达256K)和更复杂任务上的表现进行了深入分析,以理解任务配置和失败模式对RULER的影响。
他们还分析了训练上下文长度、模型大小和架构对模型性能的影响,发现更大的上下文训练通常会带来更好的性能,但对长序列的排名可能不一致;模型大小的增加对长上下文建模有显著好处;非Transformer架构(如RWKV和Mamba)在RULER上的表现显著落后于基于Transformer的Llama2-7B。
更多细节,感兴趣的家银们可以查看原论文。
论文链接:https://arxiv.org/abs/2404.06654
以上就是英伟达新研究:上下文长度虚标严重,32K性能合格的都不多的详细内容,更多请关注其它相关文章!
# 的是
# seo常见名词解释
# 祛痘膏如何营销产品推广
# 为什么用seo优化
# 上海seo优化哪个好用
# 网站建设作业指导书
# 海南抖音seo优化技巧
# 沧州孟村集团网站建设
# 湖南seo营销快速入门
# 餐饮抖音怎么做营销推广
# 孝感seo推广网址大全
# 使用了
# 加权平均
# 模型
# 参数设置
# 结构化
# 都有
# 大海捞针
# 开源
# 多个
# 不多
# llama
# claude
# gemini
# 英伟达
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何学习typescript
三星相机里power是什么意思
2026年将会大爆发的15个新科技
如何设置sql命令
typescript如何定义变量
vue怎么连接typescript
锤子手机怎么不出5g
命令指示符如何打开盘符
怎么在爱奇艺中投屏到电视最新方法
手机如何ip绑定域名解析
酷我音乐怎么改每日推荐 酷我音乐每日推荐修改方法
如何通过命令系统还原
电脑显示屏上power是什么意思
如何用dos命令分区
手机的nfc是什么功能是什么意思
电瓶车充电器power是什么意思
苹果手机16系统有哪些
如何显示固态硬盘
如何查看固态硬盘速度
春运辅助抢票怎么抢
如何编写一个linux命令
如何使用ping命令
typescript如何生成uuid
燃气热水器上的power是什么意思
360n7锁屏壁纸怎么固定
光刻机的作用及工作原理
12306放票时间规律(2025)
typescript与es6学哪个
j*a 数组怎么循环输出
折叠屏手机选择哪个好
新三板市盈率是什么意思
如何为服务器配置静态路由?服务器配置静态路由详细教程
如何查询固态硬盘寿命
如何安装台式机固态硬盘
51单片机怎么用flash
进口超级维特拉三门版power是什么意思
爱奇艺fun会员可以几个人用?
汽车收音机power是什么意思
juice是什么意思
电信开通nfc功能是什么意思
折叠屏手机好不好,耐不耐用
华为5g手机怎么选择
如何查询固态硬盘序列
液位传感器power是什么意思
怎么在typescript写原型链
壁挂炉power常亮是什么意思
如何打开命令框
苹果手机16新款颜色有哪些
linux如何安装yum命令
j*a怎么用数组缓存
