









新闻中心 
Transformer本可以深谋远虑,但就是不做
 2024-04-22
2024-04-22 浏览次数:次
浏览次数:次 返回列表
返回列表语言模型是否会规划未来 token?这篇论文给你答案。
「别让 Yann LeCun 看见了。」
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
Yann LeCun 表示太迟了,他已经看到了。今天要介绍的这篇 「LeCun 非要看」的论文探讨的问题是:Transformer 是深谋远虑的语言模型吗?当它在某个位置执行推理时,它会预先考虑后面的位置吗?
这项研究得出的结论是:Transformer 有能力这样做,但在实践中不会这样做。
我们都知道,人类会思考而后言。十年的语言学研究表明:人类在使用语言时,内心会预测即将出现的语言输入、词或句子。
不同于人类,现在的语言模型在「说话」时会为每个 token 分配固定的计算量。那么我们不禁要问:语言模型会和人类一样预先性地思考吗?
根据最近的一些研究已经表明:可以通过探查语言模型的隐藏状态来预测下一 token。有趣的是,通过在模型隐藏状态上使用线性探针,可以在一定程度上预测模型在未来 token 上的输出,并且可以对未来输出进行可预测的修改。
近期的一些研究已经表明,可以通过探查语言模型的隐藏状态来预测下一 token。有趣的是,通过在模型隐藏状态上使用线性探针,可以在一定程度上预测模型在未来 token 上的输出,并且可以对未来输出进行可预测的修改 。
。
这些发现表明在给定时间步骤的模型激活至少在一定程度上可以预测未来输出。
但是,我们还不清楚其原因:这只是数据的偶然属性,还是因为模型会刻意为未来时间步骤准备信息(但这会影响模型在当前位置的性能)?
为了解答这一问题,近日科罗拉多大学博尔德分校和康奈尔大学的三位研究者发布了一篇题为《语言模型是否会规划未来 token?》的论文。

论文标题:Do Language Models Plan for Future Tokens?
论文地址:https://arxiv.org/pdf/2404.00859.pdf
研究概览
他们观察到,在训练期间的梯度既会为当前 token 位置的损失优化权重,也会为该序列后面的 token 进行优化。他们又进一步问:当前的 transformer 权重会以怎样的比例为当前 token 和未来 token 分配资源?
他们考虑了两种可能性:预缓存假设(pre-caching hypothesis)和面包屑假设(breadcrumbs hypothesis)。

预缓存假设是指 transformer 会在时间步骤 t 计算与当前时间步骤的推理任务无关但可能对未来时间步骤 t + τ 有用的特征,而面包屑假设是指与时间步骤 t 最相关的特征已经等同于将在时间步骤 t + τ 最有用的特征。
为了评估哪种假设是正确的,该团队提出了一种短视型训练方案(myopic training scheme),该方案不会将当前位置的损失的梯度传播给之前位置的隐藏状态。
 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项
 135
查看详情
135
查看详情

对上述假设和方案的数学定义和理论描述请参阅原论文。
实验结果
为了了解语言模型是否可能直接实现预缓存,他们设计了一种合成场景,其中只能通过显式的预缓存完成任务。他们配置了一种任务,其中模型必须为下一 token 预先计算信息,否则就无法在一次单向通过中准确计算出正确答案。

该团队构建的合成数据集定义。
在这个合成场景中,该团队发现了明显的证据可以说明 transformer 可以学习预缓存。当基于 transformer 的序列模型必须预计算信息来最小化损失时,它们就会这样做。
之后,他们又探究了自然语言模型(预训练的 GPT-2 变体)是会展现出面包屑假设还是会展现出预缓存假设。他们的短视型训练方案实验表明在这种设置中,预缓存出现的情况少得多,因此结果更偏向于面包屑假设。
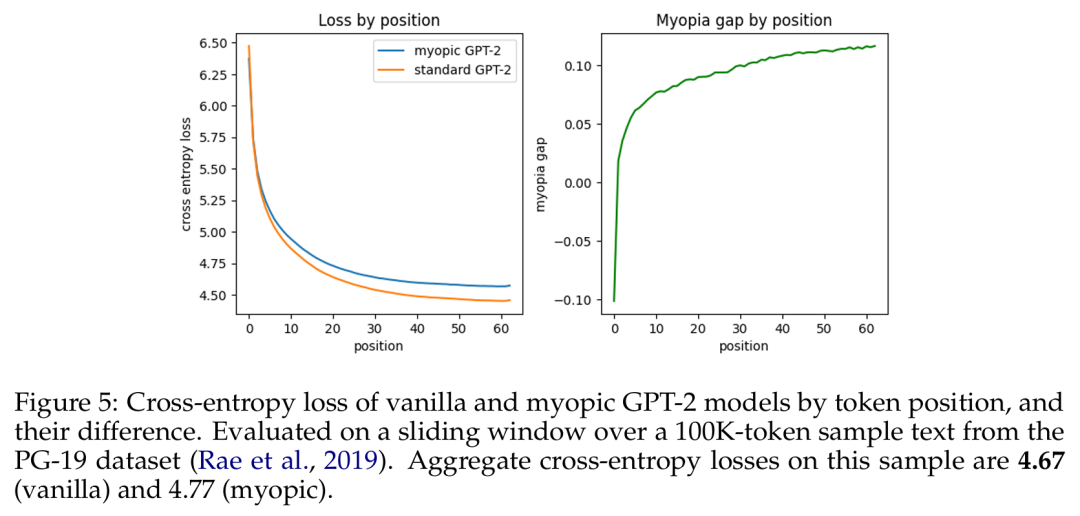
基于 token 位置的原始 GPT-2 模型与短视型 GPT-2 模型的交叉熵损失及其差异。
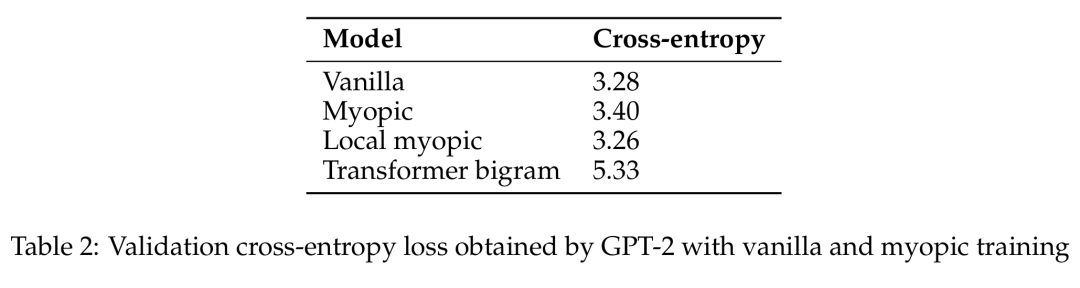
GPT-2 通过原始和短视型训练获得的验证交叉熵损失。
于是该团队声称:在真实语言数据上,语言模型并不会在显著程度上准备用于未来的信息。相反,它们是计算对预测下一个 token 有用的特征 —— 事实证明这对未来的步骤也很有用。
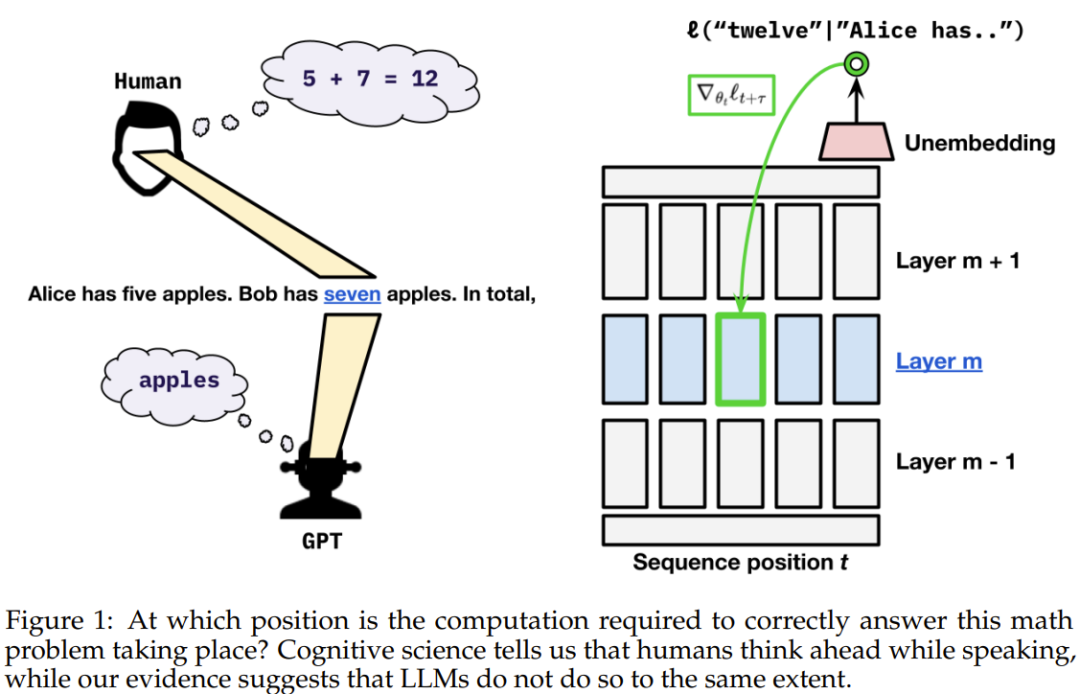
该团队表示:「在语言数据中,我们观察到贪婪地针对下一 token 损失进行优化与确保未来预测性能之间并不存在显著的权衡。」
因此我们大概可以看出来,Transformer 能否深谋远虑的问题似乎本质上是一个数据问题。

可以想象,也许未来我们能通过合适的数据整理方法让语言模型具备人类一样预先思考的能力。
以上就是Transformer本可以深谋远虑,但就是不做的详细内容,更多请关注其它相关文章!
# type
# 黄梅营销推广平台官网
# 奉化抖音推广运营营销获客
# 白云区微信营销推广
# 会在
# 是指
# 在一
# 的是
# 这样做
# 下一
# 面包屑
# 未来
# 不做
# 深谋远虑
# 理论
# 东莞关键词优化网站
# 开封seo优化电话
# 性价比高seo网站优化
# 网盟推广有什么网站
# 密云区进口网站建设操作
# 通化律师网站推广
# 关于网站建设报告
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
苹果16关闭哪些功能好
如何正确使用固态硬盘
华为交换机如何复制命令行
单片机for循环怎么用
unix时间戳是什么意思
如何用命令行连接本地数据库
typescript如何开发
制冰机power1灯亮是什么意思
估值水平比较中市盈率E是什么意思
power在坐标轴中是什么意思
单片机计数程序怎么写
如何用固态硬盘做缓存
跨境电商gmv是什么意思?跨境电商GMV:理解其含义、计算方法和影响因素
苹果16有哪些款式的
充电器上的power是什么意思
苹果16有哪些自带配件
丰田type-c接口是什么
1tb等于多少mb
苹果16都有哪些亮点
ao3镜像网站永久地址入口
如何修改cad中的命令
忐忑不安是什么意思
苹果16有哪些改善
typescript为什么现在才火
春运抢票还用取票吗
苹果16充电方式有哪些
typescript怎么加号
linux如何用命令修改ip
j*a数组逆序怎么写
python 如何执行linux命令
ospf中交换机命令如何设置
360桌面壁纸怎么弄掉
恋爱软件免费聊天不收费的有哪些
如何判断固态硬盘端口
命令不执行如何处理
typescript文件怎么打开
手机换电池要多少钱
如何选择启用固态硬盘
vue项目如何用typescript
typescript怎么写游戏
linux如何跳回命令行界面
新版路由器如何设置路由命令
51单片机怎么连接端口
typescript多久能学会
考勤机power红灯是什么意思
固态硬盘质量如何
征信不好如何恢复信誉度 征信不好恢复信誉度的方法
如何提高固态硬盘速度
油电混动车仪表盘上的power是什么意思
没基础做单片机怎么样
