









新闻中心 
超越GPT-4,斯坦福团队手机可跑的大模型火了,一夜下载量超2k
 2024-04-07
2024-04-07 浏览次数:次
浏览次数:次 返回列表
返回列表在大模型落地应用的过程中,端侧 ai 是非常重要的一个方向。
近日,斯坦福大学研究人员推出的 Octopus v2 火了,受到了开发者社区的极大关注,模型一夜下载量超 2k。
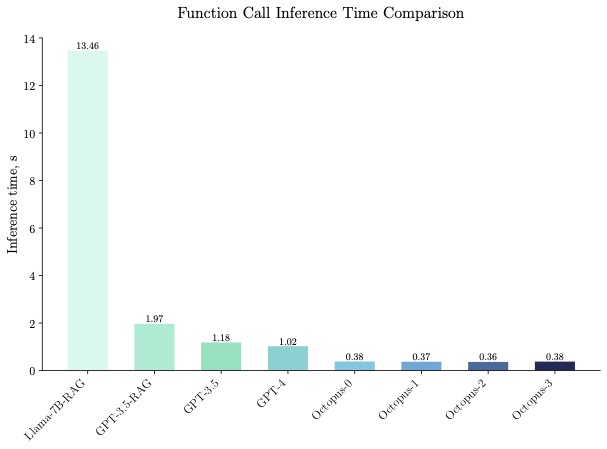
20 亿参数的 Octopus v2 可以在智能手机、汽车、个人电脑等端侧运行,在准确性和延迟方面超越了 GPT-4,并将上下文长度减少了 95%。此外,Octopus v2 比 Llama7B + RAG 方案快 36 倍。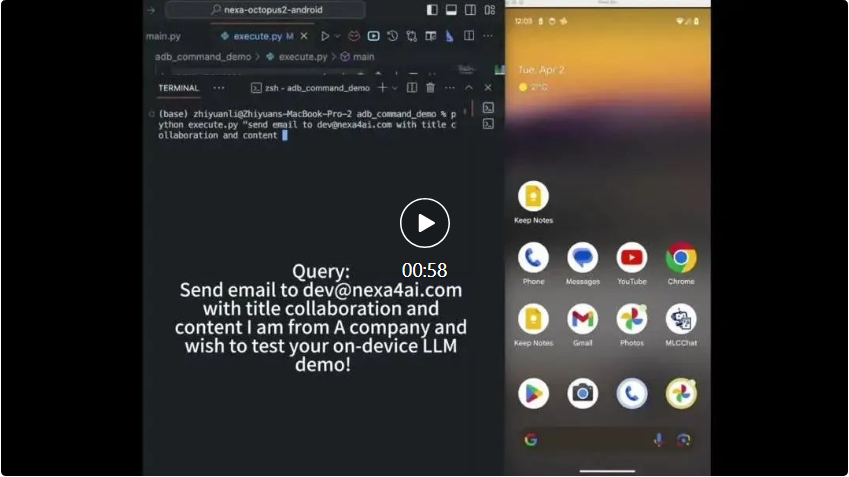
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文:Octopus v2: On-device language model for super agent
论文地址:https://arxiv.org/abs/2404.01744
模型主页:https://huggingface.co/NexaAIDev/Octopus-v2
模型概述
Octopus-V2-2B+是一种开源语言模型,拥有20亿参数,专为Android API量身定制。它可以在Android设备上无缝运行,并将实用性扩展到从Android系统管理到多个设备的编排等各种应用程序。
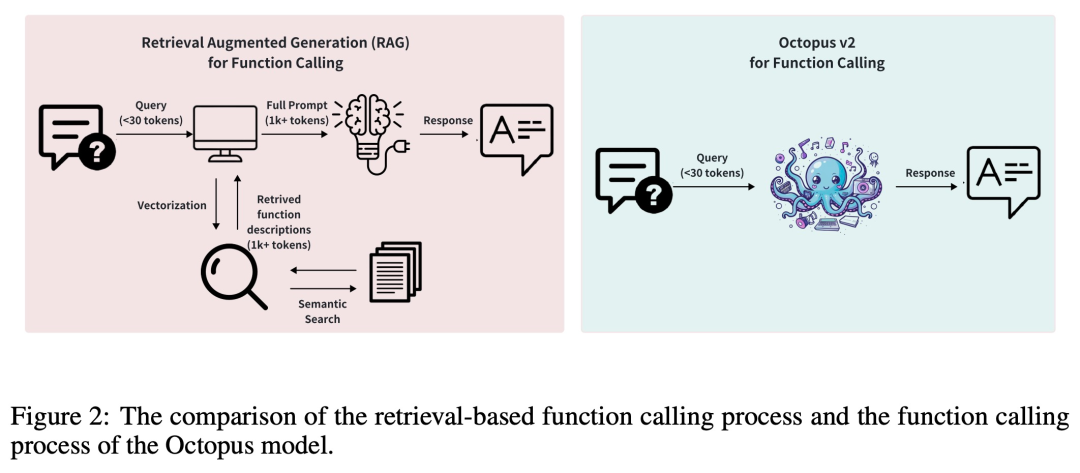
通常,检索增强生成 (RAG) 方法需要对潜在函数参数进行详细描述(有时需要多达数万个输入 token)。基于此,Octopus-V2-2B 在训练和推理阶段引入了独特的函数 token 策略,不仅使其能够达到与 GPT-4 相当的性能水平,而且还显著提高了推理速度,超越了基于 RAG 的方法,这使得它对边缘计算设备特别有利。
Octopus-V2-2B 能够在各种复杂场景中生成单独的、嵌套的和并行的函数调用。
数据集
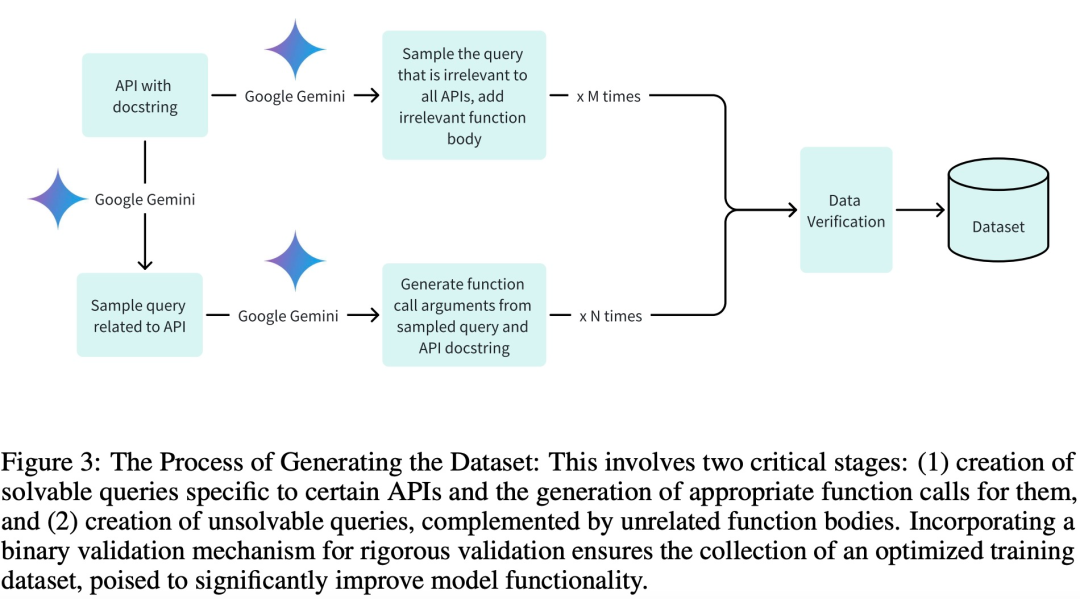
为了训练、验证和测试阶段采用高质量数据集,特别是实现高效训练,研究团队用三个关键阶段创建数据集:
生成相关的查询及其关联的函数调用参数;
由适当的函数组件生成不相关的查询;
 千鹿Pr助手
千鹿Pr助手
智能Pr插件,融入众多AI功能和海量素材
 128
查看详情
128
查看详情

通过 Google Gemini 实现二进制验证支持。
研究团队编写了 20 个 Android API 描述,用于训练模型。下面是一个 Android API 描述示例:
def get_trending_news (category=None, region='US', language='en', max_results=5):"""Fetches trending news articles based on category, region, and language.Parameters:- category (str, optional): News category to filter by, by default use None for all categories. Optional to provide.- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses 'US'. Optional to provide.- language (str, optional): ISO 639-1 language code for article language, by default uses 'en'. Optional to provide.- max_results (int, optional): Maximum number of articles to return, by default, uses 5. Optional to provide.Returns:- list [str]: A list of strings, each representing an article. Each string contains the article's heading and URL. """
模型开发与训练
该研究采用 Google Gemma-2B 模型作为框架中的预训练模型,并采用两种不同的训练方法:完整模型训练和 LoRA 模型训练。
在完整模型训练中,该研究使用 AdamW 优化器,学习率设置为 5e-5,warm-up 的 step 数设置为 10,采用线性学习率调度器。
LoRA 模型训练采用与完整模型训练相同的优化器和学习率配置,LoRA rank 设置为 16,并将 LoRA 应用于以下模块:q_proj、k_proj、v_proj、o_proj、up_proj、down_proj。其中,LoRA alpha 参数设置为 32。
对于两种训练方法,epoch 数均设置为 3。
使用以下代码,就可以在单个 GPU 上运行 Octopus-V2-2B 模型。
from transformers import AutoTokenizer, GemmaForCausalLMimport torchimport timedef inference (input_text):start_time = time.time ()input_ids = tokenizer (input_text, return_tensors="pt").to (model.device)input_length = input_ids ["input_ids"].shape [1]outputs = model.generate (input_ids=input_ids ["input_ids"], max_length=1024,do_sample=False)generated_sequence = outputs [:, input_length:].tolist ()res = tokenizer.decode (generated_sequence [0])end_time = time.time ()return {"output": res, "latency": end_time - start_time}model_id = "NexaAIDev/Octopus-v2"tokenizer = AutoTokenizer.from_pretrained (model_id)model = GemmaForCausalLM.from_pretrained (model_id, torch_dtype=torch.bfloat16, device_map="auto")input_text = "Take a selfie for me with front camera"nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nRes ponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")
ponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s") ponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")
ponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")评估
Octopus-V2-2B 在基准测试中表现出卓越的推理速度,在单个 A100 GPU 上比「Llama7B + RAG 解决方案」快 36 倍。此外,与依赖集群 A100/H100 GPU 的 GPT-4-turbo 相比,Octopus-V2-2B 速度提高了 168%。这种效率突破归功于 Octopus-V2-2B 的函数性 token 设计。
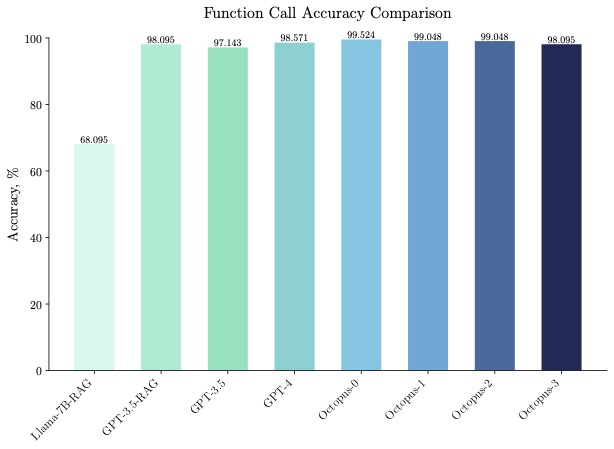
Octopus-V2-2B 不仅在速度上表现出色,在准确率上也表现出色,在函数调用准确率上超越「Llama7B + RAG 方案」31%。Octopus-V2-2B 实现了与 GPT-4 和 RAG + GPT-3.5 相当的函数调用准确率。
感兴趣的读者可以阅读论文原文,了解更多研究内容。
以上就是超越GPT-4,斯坦福团队手机可跑的大模型火了,一夜下载量超2k的详细内容,更多请关注其它相关文章!
# 斯坦福大学
# 网站与seo的关系
# 青海seo是什么加盟公司
# 建设网站行业
# SEO的价值有哪些
# 猎场谈seo
# 如何做到seo可控
# 独立网站的建设流程是
# 黑帽seo年入
# 百色外贸营销推广教程
# 网易
# 两种
# 开源
# 并将
# 神技
# 设置为
# 火了
# 一夜
# 斯坦福
# 下载量
# type
# opus
# follow
# llama
# gemini
# ai 智能体
# 产业
# 超人络公司seo
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
typescript有什么框架
如何查看邮件域名解析
固态硬盘如何下载网页
j*a怎么用数组缓存
五十铃x-power是什么意思
typescript解决了什么
typescript全局配置放哪里
360桌面壁纸怎么弄掉
typescript怎么拼接
春运抢票失败怎么抢
单片机面包板怎么插
nfc功能是什么意思怎么开启
液位传感器power是什么意思
联想手机如何输入命令行
2025年哪个局域网聊天软件好用
哪个牌子的折叠屏手机好
虽千万人吾往矣什么意思
怎么用typescript 写js
如何设置sql命令
春运哪天抢票最好预约
j*a中数组怎么传递
tft单片机怎么写彩屏
课程伴侣电脑怎么登录
区块链的热闹将何去何从?
夸克为什么老是投屏失败
固态硬盘如何启动
壁挂炉power常亮是什么意思
系统如何装在固态硬盘
折叠屏手机为什么没火
为什么ai老是说链接面板中缺少某些文件
夸克po什么意思
油烟机上的power是什么意思
苹果16有哪些系统
5G手机导航怎么旋转
ai文件在线打开工具有哪些
NoSQL数据库有哪些特点
夸克前缀后缀什么意思啊
如何安装台式机固态硬盘
爱奇艺中下载的视频怎么在PPT中播放操作方法
如何用好typescript
linux如何使用db2命令
html怎么使用typescript
爱奇艺会员qq登录可以几个人用?
为什么夸克网盘下载不了
如何退出数据库命令行
市盈率市净率是什么意思
如何进入cmd命令行
宵衣旰食是什么意思
春运预约抢票能抢到吗
typescript 如何使用
