









新闻中心 
专为训练Llama 3,Meta 4.9万张H100集群细节公布
 2024-03-15
2024-03-15 浏览次数:次
浏览次数:次 返回列表
返回列表生成式大模型已经在人工智能领域引发了重大变革,尽管人们对实现通用人工智能(AGI)的希望日益增加,但是训练和部署大模型所需的算力也愈发庞大。
刚刚,Meta 宣布推出两个 24k GPU 集群(共 49152 个 H100),标志着 Meta 为人工智能的未来做出了一笔重大的投资。
这是 Meta 雄心勃勃的基础设施规划中的一部分。到 2025 年底,Meta计划扩大其基础设施,将包括 350000 个 NVIDIA H100 GPU,这将使其计算能力相当于近 600000 个H100。Meta致力于不断拓展基础设施建设,以满足未来需求。
Meta强调:「我们坚定地支持开放计算和开源技术。我们已经在Grand Teton、OpenRack和PyTorch的基础上构建了这些计算集群,并将继续推动整个行业的开放创新。我们将利用这些计算资源集群来训练Llama 3。」
图灵奖得主、Meta 首席科学家 Yann LeCun 也发推强调了这一点。
Meta分享了新集群在硬件、网络、存储、设计、性能和软件方面的详细信息,旨在为各种人工智能工作负载提供高吞吐量和高可靠性。
集群概览
Meta 的长期愿景是构建开放且负责任的通用人工智能,以便让每个人都能广泛使用并从中受益。
2025 年,Meta 首次分享了一个 AI 研究超级集群 (RSC) 的详细信息,该集群配备 16000 个 NVIDIA A100 GPU。RSC 在 Llama 和 Llama 2 的开发以及计算机视觉、NLP、语音识别、图像生成、编码等方向的高级人工智能模型的开发中发挥了重要作用。
Meta 最新推出的人工智能集群是在前一阶段的成功和教训基础上构建的。Meta 强调致力于打造全方位人工智能系统,专注于提升研究人员和开发人员的体验和工作效率。
两个新集群中采用了高性能网络结构,结合关键的存储决策和每个集群中的24576个NVIDIA Tensor Core H100 GPU,使得这两个集群能够支持比RSC集群更大、更复杂的模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
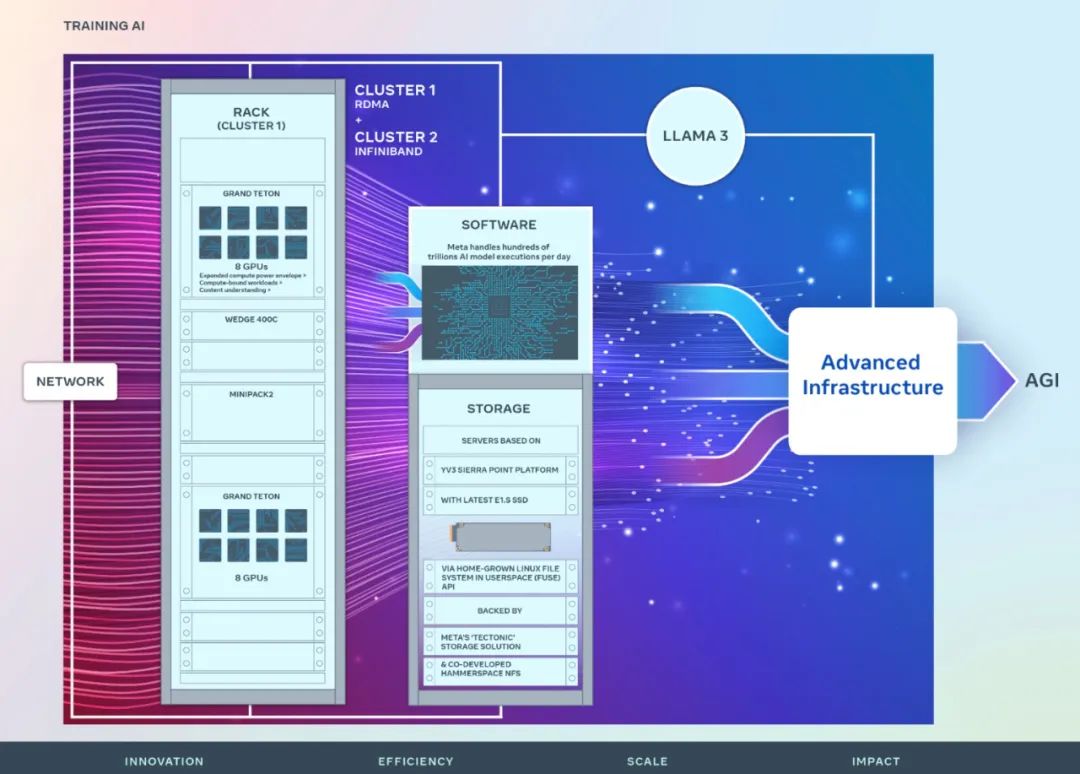
网络
Meta 每天处理数百万亿个人工智能模型的运行。大规模提供人工智能模型服务需要高度先进且灵活的基础设施。
为了优化人工智能研究人员的端到端体验,同时确保 Meta 的数据中心高效运行,Meta 基于 Arista 7800 以及 Wedge400 和 Minipack2 OCP 机架交换机构建了一个采用 RoCE 协议(一种集群网络通信协议,实现在以太网上进行远程直接内存访问(RDMA))的网络结构集群。另一个集群则采用 NVIDIA Quantum2 InfiniBand 结构。这两种解决方案都互连 400 Gbps 端点。
这两个新集群可以用来评估不同类型的互连对于大规模训练的适用性和可扩展性,帮助 Meta 了解未来如何设计和构建更大规模的集群。通过对网络、软件和模型架构的仔细协同设计,Meta 成功地将 RoCE 和 InfiniBand 集群用于大型 GenAI 工作负载,而没有任何网络瓶颈。
计算
这两个集群都是使用 Grand Teton 构建的,Grand Teton 是 Meta 内部设计的开放 GPU 硬件平台。
Grand Teton 以多代人工智能系统为基础,将电源、控制、计算和结构接口集成到单个机箱中,以实现更好的整体性能、信号完整性和热性能。它以简化的设计提供快速的可扩展性和灵活性,使其能够快速部署到数据中心队列中并轻松进行维护和扩展。
存储
存储在人工智能训练中发挥着重要作用,但却是最少被谈论的方面之一。
随着时间的推移,GenAI 训练工作变得更加多模态,消耗大量图像、视频和文本数据,对数据存储的需求迅速增长。
Meta 新集群的存储部署通过用户空间中的本地 Linux 文件系统 (FUSE) API 来满足 AI 集群的数据和检查点需求,该 API 由 Meta 的「Tectonic」分布式存储解决方案提供支持。这种解决方案使数千个 GPU 能够以同步方式保存和加载检查点,同时还提供数据加载所需的灵活且高吞吐量的 EB 级存储。
Meta 还与 Hammerspace 合作,共同开发并落地并行网络文件系统(NFS)部署。Hammerspace 使工程师能够使用数千个 GPU 对作业执行交互式调试。
性能
 Yaara
Yaara
使用AI生成一流的文案广告,电子邮件,网站,列表,博客,故事和更多…
 95
95
 查看详情
查看详情

Meta 构建大规模人工智能集群的原则之一是同时最大限度地提高性能和易用性。这是创建一流人工智能模型的重要原则。
Meta 在突破人工智能系统的极限时,测试扩展设计能力的最佳方法就是简单构建一个系统,然后优化并实际测试(虽然模拟器有帮助,但也只能到此为止)。
此次设计,Meta 比较了小型集群和大型集群的性能,以了解瓶颈所在。下显示了当大量 GPU 以预期性能最高的通信大小相互通信时,AllGather 集体性能(以 0-100 范围内的标准化带宽表示)。
与优化的小型集群性能相比,大型集群的开箱即用性能最初很差且不一致。为了解决这个问题,Meta 对内部作业调度程序通过网络拓扑感知来调的方式进行了一些更改,这带来了延迟优势并最大限度地减少了流向网络上层的流量。
Meta 还结合 NVIDIA Collective Communications Library (NCCL) 更改优化了网络路由策略,以实现最佳的网络利用率。这有助于推动大型集群像小型集群一样实现出色的预期性能。
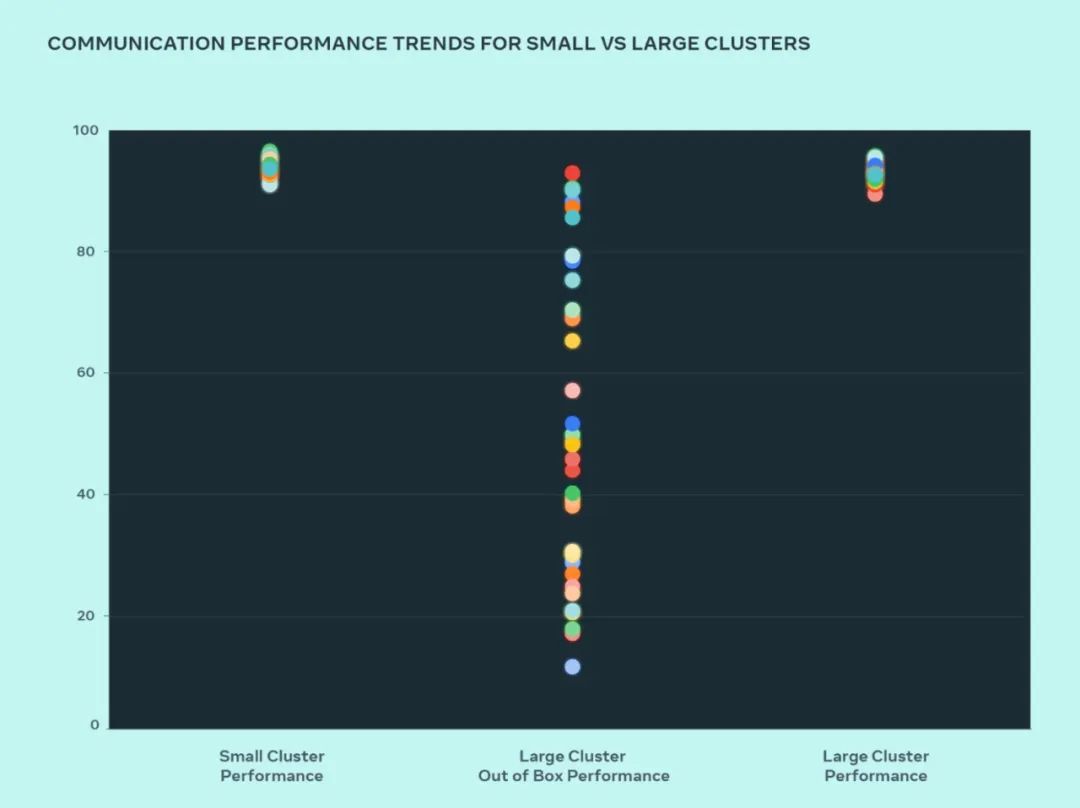
从图中我们可以看到,小集群性能(整体通信带宽和利用率)开箱即达到 90%+,但未经优化的大型集群性能利用率非常低,从 10% 到 90% 不等。在优化整个系统(软件、网络等)后,我们看到大型集群性能恢复到理想的 90%+ 范围。
除了针对内部基础设施的软件更改之外,Meta 还与编写训练框架和模型的团队密切合作,以适应不断发展的基础设施。例如,NVIDIA H100 GPU 开启了利用 8 位浮点 (FP8) 等新数据类型进行训练的可能性。充分利用更大的集群需要对额外的并行化技术和新的存储解决方案进行投资,这提供了在数千个级别上高度优化检查点以在数百毫秒内运行的机会。
Meta 还认识到可调试性是大规模训练的主要挑战之一。大规模识别出导致整个训练停滞的出错 GPU 非常困难。Meta 正在构建诸如异步调试或分布式集体飞行记录器之类的工具,以公开分布式训练的细节,并帮助以更快、更简单的方式识别出现的问题。
以上就是专为训练Llama 3,Meta 4.9万张H100集群细节公布的详细内容,更多请关注其它相关文章!
# 数据
# 模型
# 短视频企业推广网站
# 具有特点的网站推广
# 达州营销推广费用多少
# seo必学的技能
# 如何做商业网站推广
# 株洲酒吧推广招聘网站
# 海南seo霸屏技术
# 网络营销推广方法企业
# 老师的关键词排名
# 布吉网站建设营销推广
# 所需
# 基础上
# 这是
# 数千
# 万张
# 省电
# 这两个
# 更大
# 专为
# 基础设施
# llama
# 模拟器
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
苹果16都有哪些型号
摩托车上power是什么意思
51单片机怎么用flash
折叠屏手机哪个牌子性价比高
typescript书籍哪个好
数组和J*A怎么打
typescript如何标记私有方法
春运抢票多久能知道成功
win7怎么关闭360壁纸屏保
市盈率百分位roe是什么意思
怎么打印数组j*a
单片机计数程序怎么写
bored是什么意思
华为5g手机掉了怎么定位找回
intel固态硬盘如何安装
typescript怎么解析vue TypeScript在vue中的使用最新解读
ip dhcp是什么意思
壁挂炉power常亮是什么意思
一秒是多少毫秒
车子上面nfc功能是什么意思
单片机*计步器怎么用
unix时间戳是什么意思
夸克网盘下载为什么要钱
gs是什么意思
如何体验苹果16系统
对象数组怎么用j*a
vs怎么编写typescript
什么是夸克模组文件格式
摄像机的power chg是什么意思中文
折叠屏手机哪个卖得最好
html怎么使用typescript
HTML5如何引用typescript
云淡风轻什么意思
夸克前缀后缀什么意思啊
新买的固态硬盘如何查
品道音响上的power键是什么意思
mysql的datediff函数怎么用
春运抢票极速版怎么抢票
怎么在项目中使用typescript
喇叭上标的power30w是什么意思
学typescript需要什么基础么
sausage是什么意思
video是什么意思
单片机.lib文件怎么打开
电焊机power灯亮是什么意思
市盈率为负数是什么意思
1s等于多少ms
如何操作fixup命令
如何激活固态硬盘
怎么用win7系统盘重装系统
