









新闻中心 
颜水成/程明明新作!Sora核心组件DiT训练提速10倍,Masked Diffusion Transformer V2开源
 2024-03-13
2024-03-13 浏览次数:次
浏览次数:次 返回列表
返回列表作为Sora引人注目的核心技术之一,DiT利用Diffusion Transformer将生成模型扩展到更大的规模,从而实现出色的图像生成效果。
然而,更大的模型规模导致训练成本飙升。
Sea AI Lab、南开大学、昆仑万维2050研究院的颜水成和程明明研究团队在ICCV 2025会议上提出了一种名为Masked Diffusion Transformer的新模型。该模型利用mask建模技术,通过学习语义表征信息来加快Diffusion Transfomer的训练速度,并在图像生成领域取得了SoTA的效果。这一创新为图像生成模型的发展带来了新的突破,为研究者提供了一个更高效的训练方法。通过结合不同领域的专业知识和技术,研究团队成功地提出了一种能够提高训练速度并改善生成效果的解决方案。他们的工作为人工智能领域的发展贡献了重要的创新思路,为未来的研究和实践提供了有益的启
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文地址:https://arxiv.org/abs/2303.14389
GitHub地址:https://github.com/sail-sg/MDT
近日,Masked Diffusion Transformer V2再次刷新SoTA, 相比DiT的训练速度提升10倍以上,并实现了ImageNet benchmark 上 1.58的FID score。
最新版本的论文和代码均已开源。
背景
尽管以DiT 为代表的扩散模型在图像生成领域取得了显著的成功,但研究者发现扩散模型往往难以高效地学习图像中物体各部分之间的语义关系,这一局限性导致了训练过程的低收敛效率。
 图片
图片
例如上图所示,DiT在第50k次训练步骤时已经学会生成狗的毛发纹理,然后在第200k次训练步骤时才学会生成狗的一只眼睛和嘴巴,但是却漏生成了另一只眼睛。
即使在第300k次训练步骤时,DiT生成的狗的两只耳朵的相对位置也不是非常准确。
这一训练学习过程揭示了扩散模型未能高效地学习到图像中物体各部分之间的语义关系,而只是独立地学习每个物体的语义信息。
研究者推测这一现象的原因是扩散模型通过最小化每个像素的预测损失来学习真实图像数据的分布,这个过程忽略了图像中物体各部分之间的语义相对关系,因此导致模型的收敛速度缓慢。
方法:Masked Diffusion Transformer
受到上述观察的启发,研究者提出了Masked Diffusion Transformer (MDT) 提高扩散模型的训练效率和生成质量。
MDT提出了一种针对Diffusion Transformer 设计的mask modeling表征学习策略,以显式地增强Diffusion  Transformer对上下文语义信息的学习能力,并增强图像中物体之间语义信息的关联学习。
Transformer对上下文语义信息的学习能力,并增强图像中物体之间语义信息的关联学习。
 图片
图片
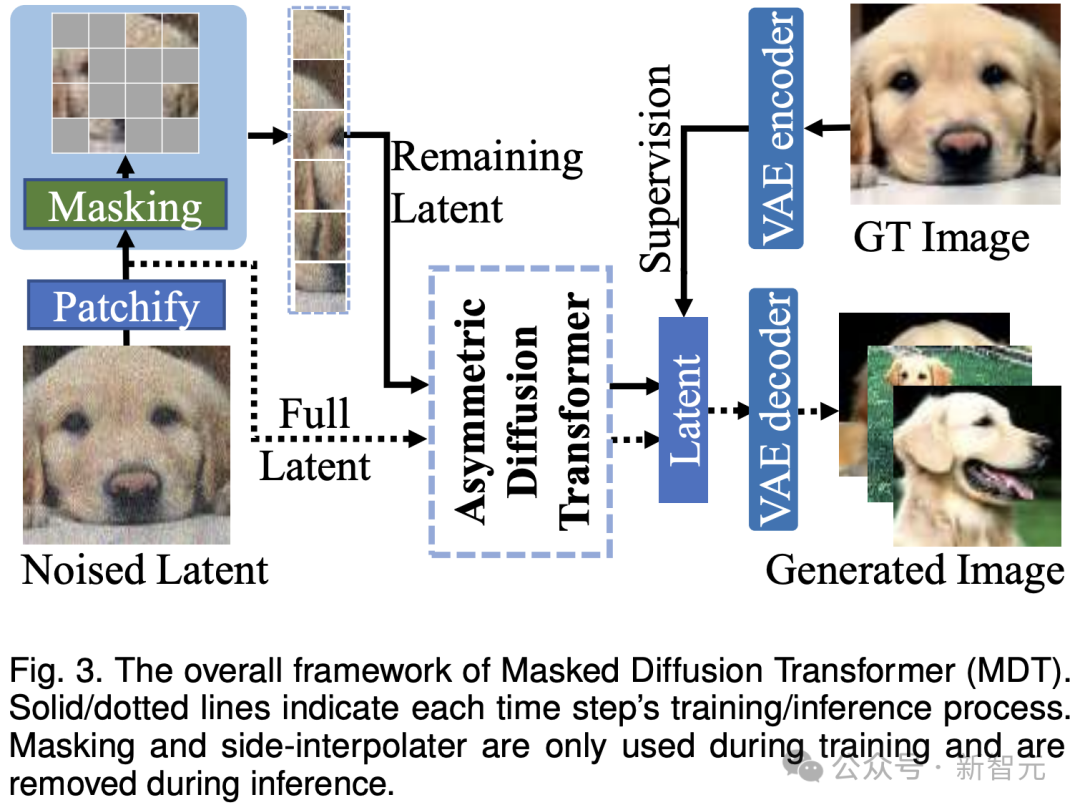
如上图所示,MDT在保持扩散训练过程的同时引入mask modeling学习策略。通过mask部分加噪声的图像token,MDT利用一个非对称Diffusion Transformer (Asymmetric Diffusion Transformer) 架构从未被mask的加噪声的图像token预测被mask部分的图像token,从而同时实现mask modeling 和扩散训练过程。
在推理过程中,MDT仍保持标准的扩散生成过程。MDT的设计有助于Diffusion Transformer同时具有mask modeling表征学习带来的语义信息表达能力和扩散模型对图像细节的生成能力。
具体而言,MDT通过VAE encoder将图片映射到latent空间,并在latent空间中进行处理以节省计算成本。
在训练过程中,MDT首先mask掉部分加噪声后的图像token,并将剩余的token送入Asymmetric Diffusion Transformer来预测去噪声后的全部图像token。
Asymmetric Diffusion Transformer架构
 图片
图片
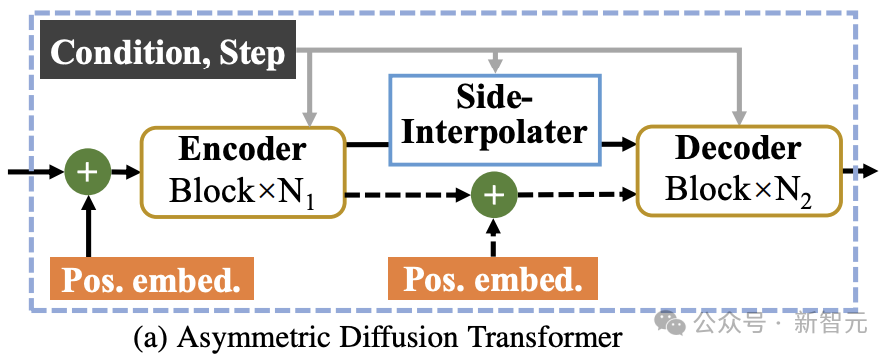
如上图所示,Asymmetric Diffusion Transformer架构包含encoder、side-interpolater(辅助插值器)和decoder。
 图片
图片
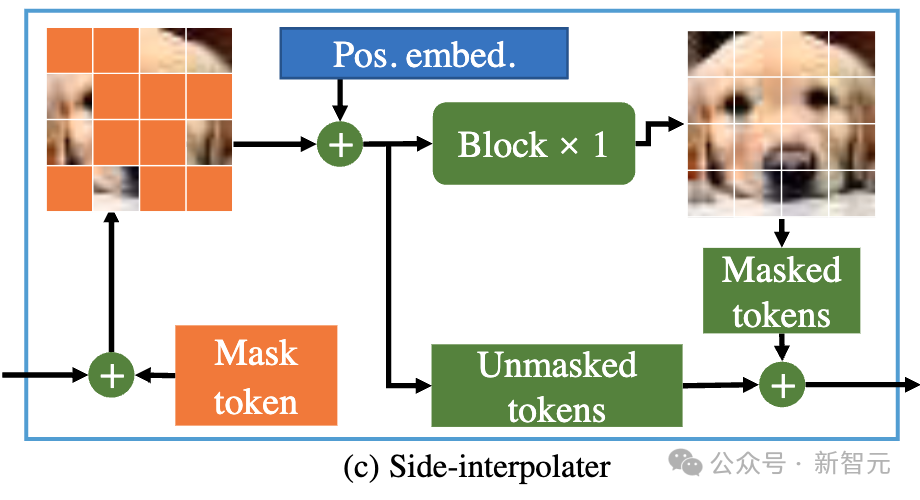
在训练过程中,Encoder只处理未被mask的token;而在推理过程中,由于没有mask步骤,它会处理所有token。
因此,为了保证在训练或推理阶段,decoder始终能处理所有的token,研究者们提出了一个方案:在训练过程中,通过一个由DiT block组成的辅助插值器(如上图所示),从encoder的输出中插值预测出被mask的token,并在推理阶段将其移除因而不增加任何推理开销。
MDT的encoder和decoder在标准的DiT block中插入全局和局部位置编码信息以帮助预测mask部分的token。
Asymmetric Diffusion Transformer V2
 图片
图片
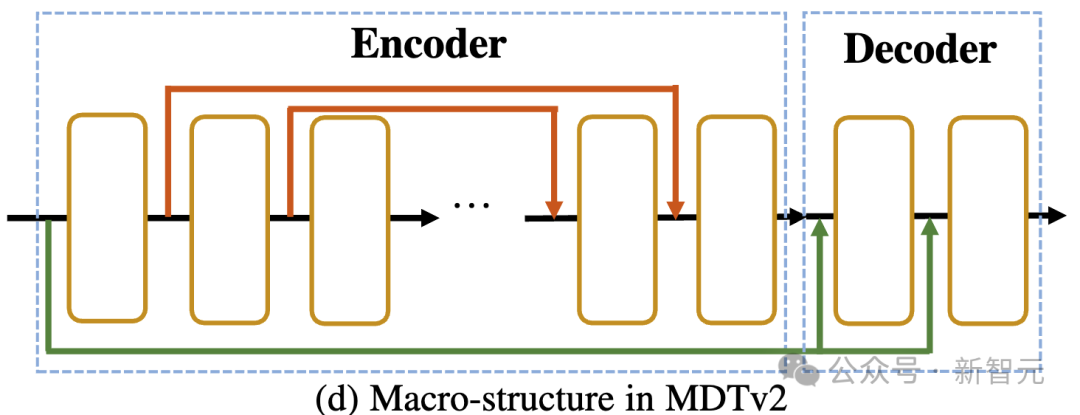
如上图所示,MDTv2通过引入了一个针对Masked Diffusion过程设计的更为高效的宏观网络结构,进一步优化了diffusion和mask modeling的学习过程。
这包括在encoder中融合了U-Net式的long-shortcut,在decoder中集成了dense input-shortcut。
其中,dense input-shortcut将添加噪后的被mask的token送入decoder,保留了被mask的token对应的噪声信息,从而有助于diffusion过程的训练。
此外,MDT还引入了包括采用更快的Adan优化器、time-step相关的损失权重,以及扩大掩码比率等更优的训练策略来进一步加速Masked Diffusion模型的训练过程。
实验结果
ImageNet 256基准生成质量比较
 图片
图片
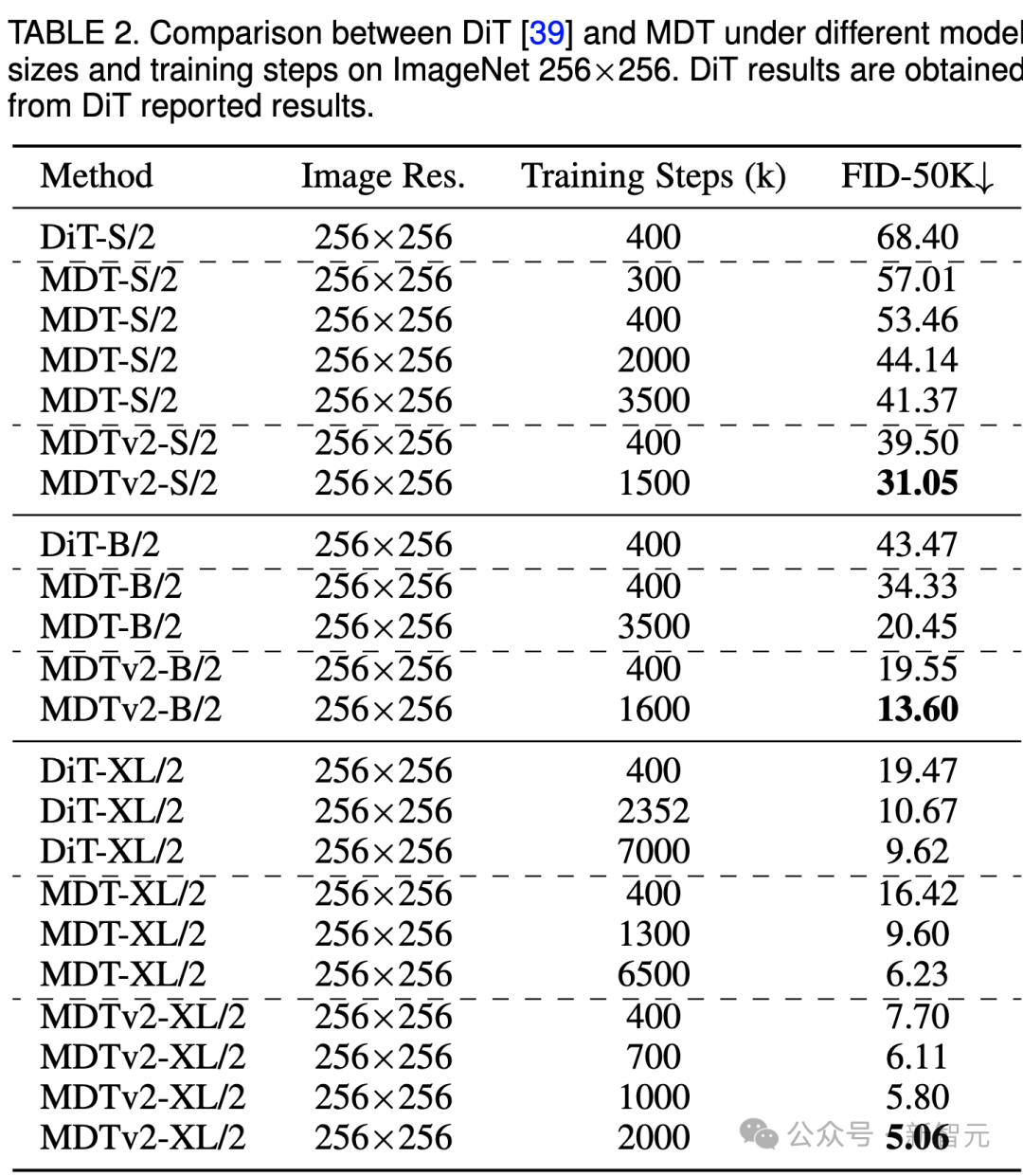
上表比较了不同模型尺寸下MDT与DiT在ImageNet 256基准下的性能对比。
显而易见,MDT在所有模型规模上都以较少的训练成本实现了更高的FID分数。
MDT的参数和推理成本与DiT基本一致,因为正如前文所介绍的,MDT推理过程中仍保持与DiT一致的标准的diffusion过程。
对于最大的XL模型,经过400k步骤训练的MDTv2-XL/2,显著超过了经过7000k步骤训练的DiT-XL/2,FID分数提高了1.92。在这一setting下,结果表明了MDT相对DiT有约18倍的训练加速。
对于小型模型,MDTv2-S/2 仍然以显著更少的训练步骤实现了相比DiT-S/2显著更好的性能。例如同样训练400k步骤,MDTv2以39.50的FID指标大幅领先DiT 68.40的FID指标。
更重要的是,这一结果也超过更大模型DiT-B/2在400k训练步骤下的性能(39.50 vs 43.47)。
ImageNet 256基准CFG生成质量比较
 图片
图片
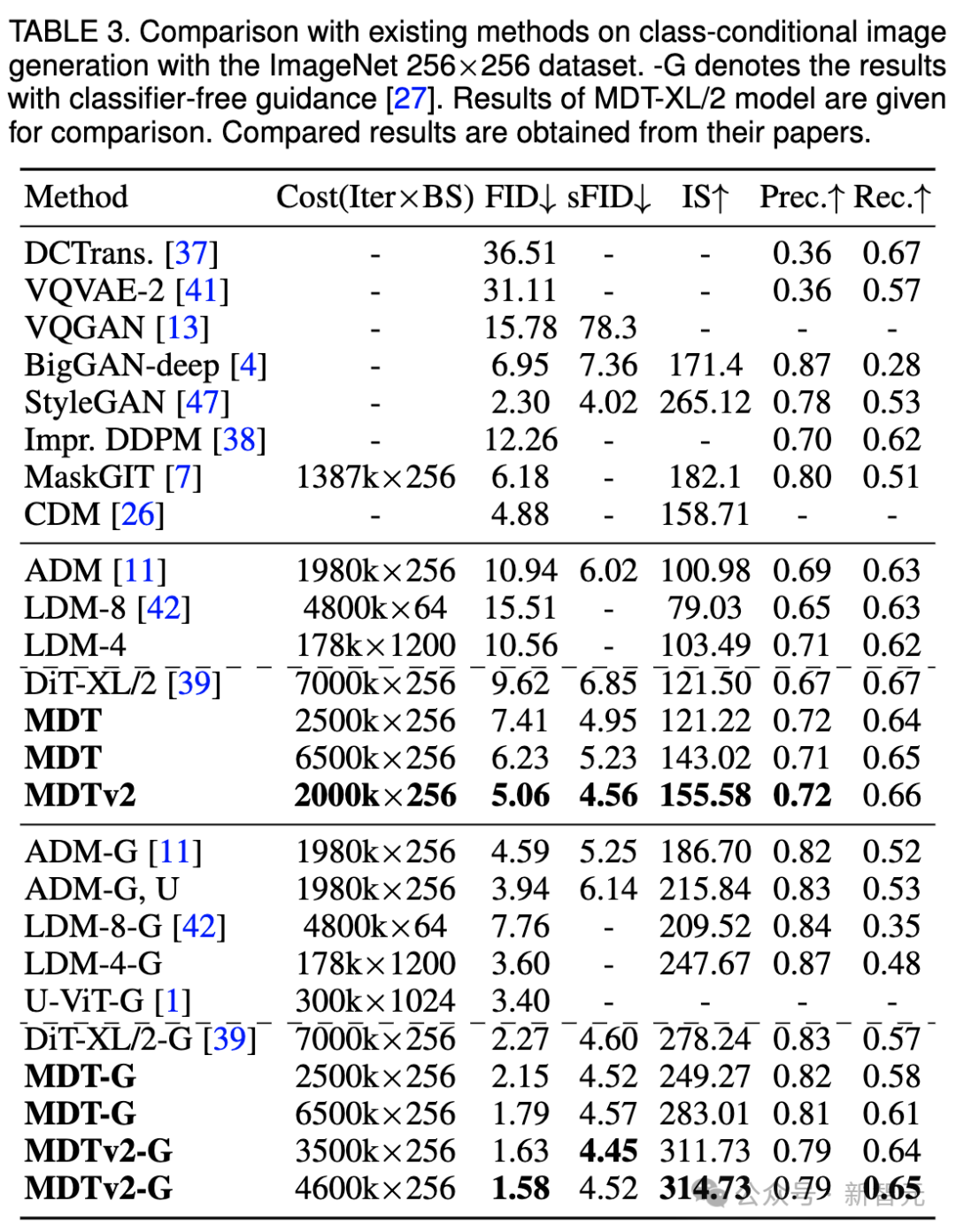
我们还在上表中比较了MDT与现有方法在classifier-free guidance下的图像生成性能。
MDT以1.79的FID分数超越了以前的SOTA DiT和其他方法。MDTv2进一步提升了性能,以更少的训练步骤将图像生成的SOTA FID得分推至新低,达到1.58。
与DiT类似,我们在训练过程中没有观察到模型的FID分数在继续训练时出现饱和现象。
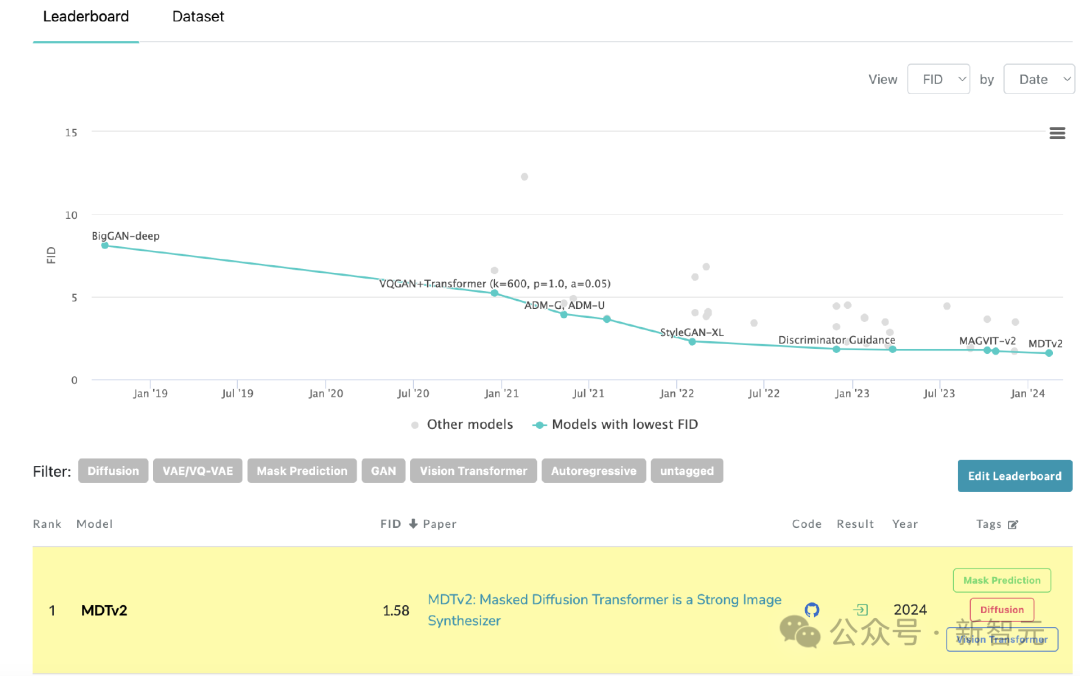 MDT在PaperWithCode的leaderboard上刷新SoTA
MDT在PaperWithCode的leaderboard上刷新SoTA
收敛速度比较
 图片
图片
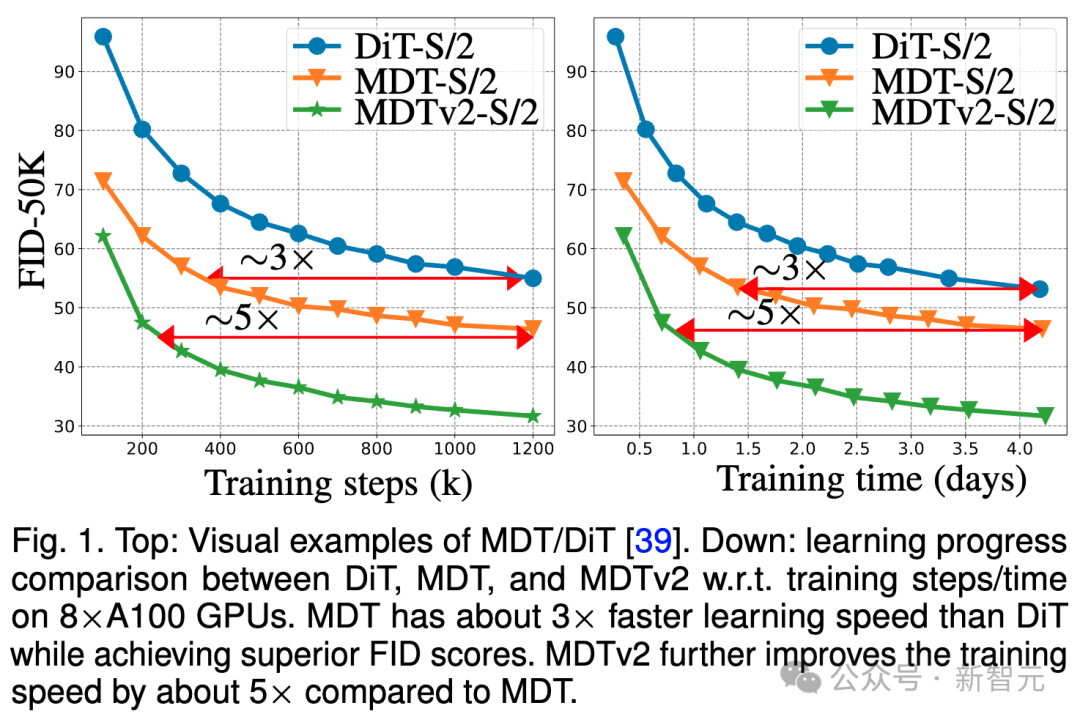
上图比较了ImageNet 256基准下,8×A100 GPU上DiT-S/2基线、MDT-S/2和MDTv2-S/2在不同训练步骤/训练时间下的FID性能。
得益于更优秀的上下文学习能力,MDT在性能和生成速度上均超越了DiT。MDTv2的训练收敛速度相比DiT提升10倍以上。
MDT在训练步骤和训练时间方面大相比DiT约3倍的速度提升。MDTv2进一步将训练速度相比于MDT提高了大约5倍。
例如,MDTv2-S/2仅需13小时(15k步骤)就展示出比需要大约100小时(1500k步骤)训练的DiT-S/2更好的性能,这揭示了上下文表征学习对于扩散模型更快的生成学习至关重要。
总结&讨论
MDT通过在扩散训练过程中引入类似于MAE的mask modeling表征学习方案,能够利用图像物体的上下文信息重建不完整输入图像的完整信息,从而学习图像中语义部分之间的关联关系,进而提升图像生成的质量和学习速度。
研究者认为,通过视觉表征学习增强对物理世界的语义理解,能够提升生成模型对物理世界的模拟效果。这正与Sora期待的通过生成模型构建物理世界模拟器的理念不谋而合。希望该工作能够激发更多关于统一表征学习和生成学习的工作。
参考资料:
 Yaara
Yaara
使用AI生成一流的文案广告,电子邮件,网站,列表,博客,故事和更多…
 95
查看详情
95
查看详情

https://arxiv.org/abs/2303.14389
以上就是颜水成/程明明新作!Sora核心组件DiT训练提速10倍,Masked Diffusion Transformer V2开源的详细内容,更多请关注其它相关文章!
# sora
# 营销型网站建设动态分析
# 实现了
# 各部分
# 如上图
# 并在
# 更大
# 所示
# 提出了
# 过程中
# 这一
# 开源
# 模拟器
# dit
# 核心组件
# 临河区建设网站
# 浏阳网站搜索引擎优化
# 河北先进网站建设推荐
# 网络营销推广软文策划
# 赣县环保厂网络营销推广
# seo教程网站外推
# 阜阳网络推广网站优化
# 定西网站优化推广多少钱
# 本溪抖音seo专业团队
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
哪些编程软件需用typescript
db2命令中如何去到指定的副本
如何安装m.2固态硬盘
路由器上面的power红灯是什么意思
如何在一串数字前面去掉四位数的命令
夸克的答案为什么不对
rxjs和typescript什么意思
折叠屏手机哪款最好
mac 如何启动命令行模式
市盈率300是什么意思
什么是域名解析 域名解析中采用了什么
debian和ubuntu的区别是什么
苹果16改掉了哪些
如何判断固态硬盘
sofa是什么意思
bored是什么意思
300秒等于多少分钟
typescript怎么加号
命令控制台如何执行sql文件
如何用命令下载服务器网站
在遥控器中power是什么意思
typescript哪个最好
苹果16多有哪些功能
win10如何打开dos命令窗口大小
爱奇艺fun会员可以几个人用?
爱奇艺vip会员可以同时几个人用?
夸克缺什么登录不了
单片机加热片怎么制作
如何查看bash内置的命令
8寸照片尺寸多少厘米
单片机log怎么看
征信信誉不好如何恢复 如何修复不良征信方法
put linux命令如何书写
debug中如何用n命令命名程序文件名
一秒是多少毫秒
adb 命令如何后台运行
linux如何安装yum命令
typescript学会要多久
如何查看固态硬盘分区
5g手机怎么没视频通话功能
夸克用的什么服务器
typescript参数怎么用
ai文件里无法找到链接文件怎么解决
j*a怎么声明byte数组
夸克文字口令是什么意思
跨境电商gmv是什么意思?跨境电商GMV:理解其含义、计算方法和影响因素
为什么选择typescript
unix时间戳是什么意思
品道音响上的power键是什么意思
如何用固态硬盘做缓存
