









新闻中心 
陈丹琦团队新作:Llama-2上下文扩展至128k,10倍吞吐量仅需1/6内存
 2024-03-01
2024-03-01 浏览次数:次
浏览次数:次 返回列表
返回列表陈丹琦团队刚刚发布了一种新的llm上下文窗口扩展方法:
它仅用8k大小的token文档进行训练,就能将Llama-2窗口扩展至128k。
最重要的是,在这个过程中,只需要原来1/6的内存,模型就获得了10倍吞吐量。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
除此之外,它还能大大降低训练成本:
用该方法对7B大小的羊驼2进行改造,只需要一块A100就能搞定。
团队表示:
希望这个方法有用、好用,为未来的LLM们提供廉价又有效的长上下文能力。
目前,模型和代码都已在HuggingFace和GitHub上发布。
只需添加两个组件
这个方法名叫CEPE,全称“并行编码上下文扩展(Context Expansion with Parallel Encoding)”。
作为轻量级框架,它可用于扩展任何预训练和指令微调模型的上下文窗口。
对于任何预训练的仅解码器语言模型,CEPE通过添加两个小组件来实现扩展:
一个是小型编码器,用于对长上下文进行块编码;
一个是交叉注意力模块,插入到解码器的每一层,用于关注编码器表示。
完整架构如下:
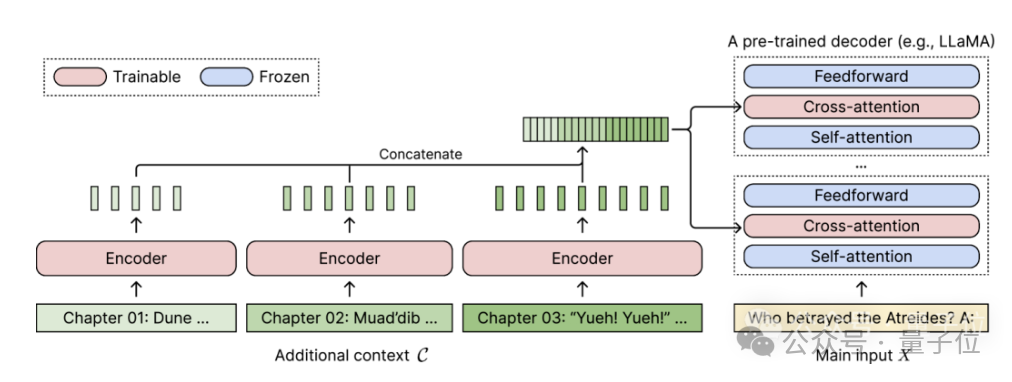
在这个示意图中,编码器模型并行编码上下文的3个额外块,并与最终隐藏表示进行连接,然后作为解码器交叉注意力层的输入。
在此,交叉注意力层主要关注解码器模型中自注意力层和前馈层之间的编码器表示。
通过仔细选择无需标记的训练数据,CEPE就帮助模型具备了长上下文能力,并且也擅长文档检索。
作者介绍,这样的CEPE主要包含3大优势:
(1)长度可泛化
因为它不受位置编码的约束,相反,它的上下文是分段编码的,每一段都有自己的位置编码。
(2)效率高
使用小型编码器和并行编码来处理上下文可以降低计算成本。
同时,由于交叉注意力仅关注编码器最后一层的表示,而仅使用解码器的语言模型则需要缓存每个层每个token的键-值对,所以对比起来,CEPE需要的内存大大减少。
(3)降低训练成本
与完全微调方法不同,CEPE只调整编码器和交叉注意力,同时保持大型解码器模型冻结。
作者介绍,通过将7B解码器扩充为具有400M编码器和交叉注意力层的模型(总计14亿参数),用一块80GB的A100 GPU就可以完成。
 刺鸟创客
刺鸟创客
一款专业高效稳定的AI内容创作平台
 110
查看详情
110
查看详情

困惑度持续降低
团队将CEPE应用于Llama-2,并在200亿 token的RedPajama过滤版本上进行训练(仅为Llama-2预训练预算的1%)。
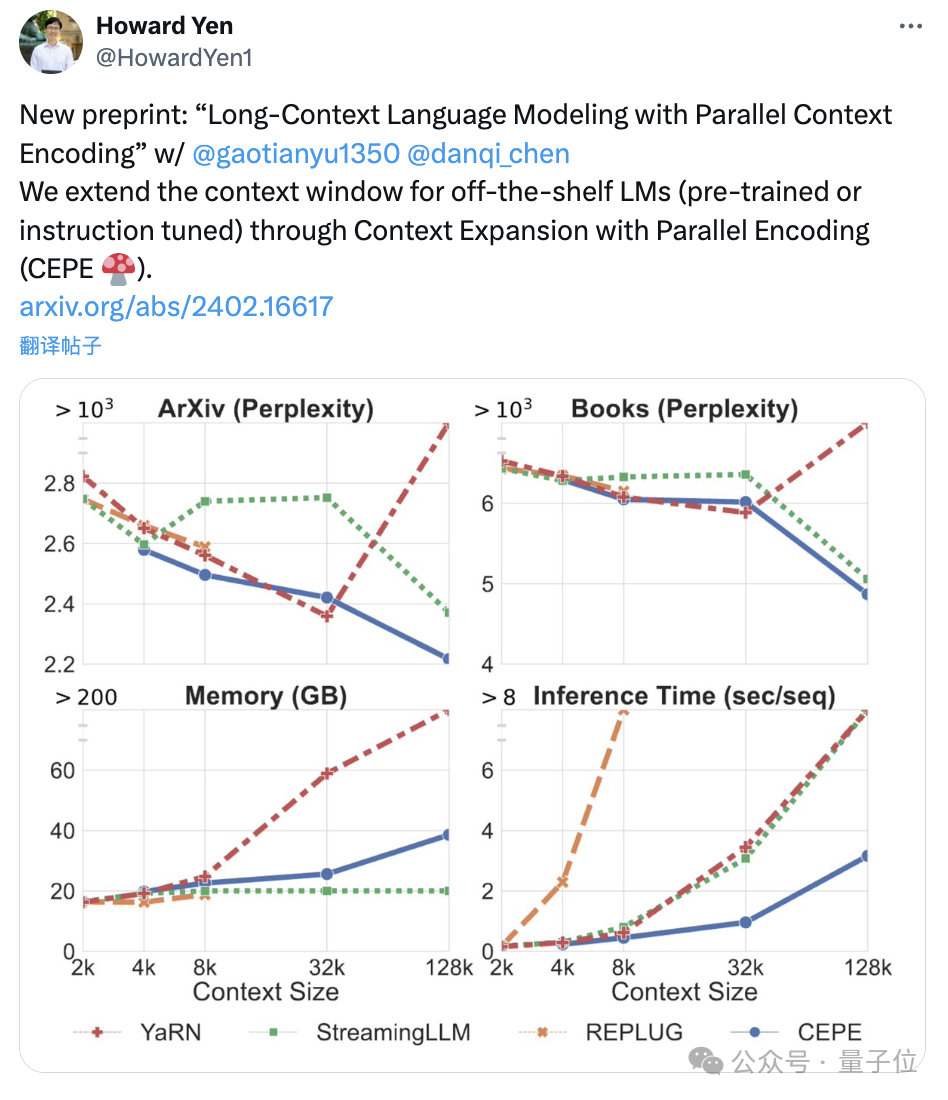
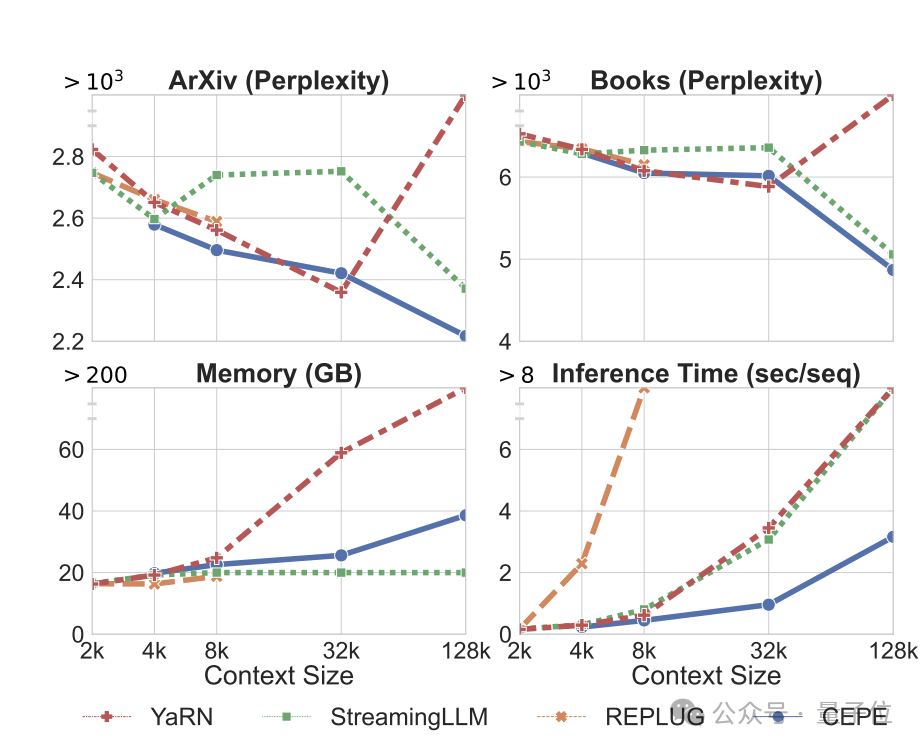
首先,与LLAMA2-32K和YARN-64K这两种完全微调的模型相比,CEPE在所有数据集上都实现了更低或相当的困惑度,同时具有更低的内存使用率和更高的吞吐量。
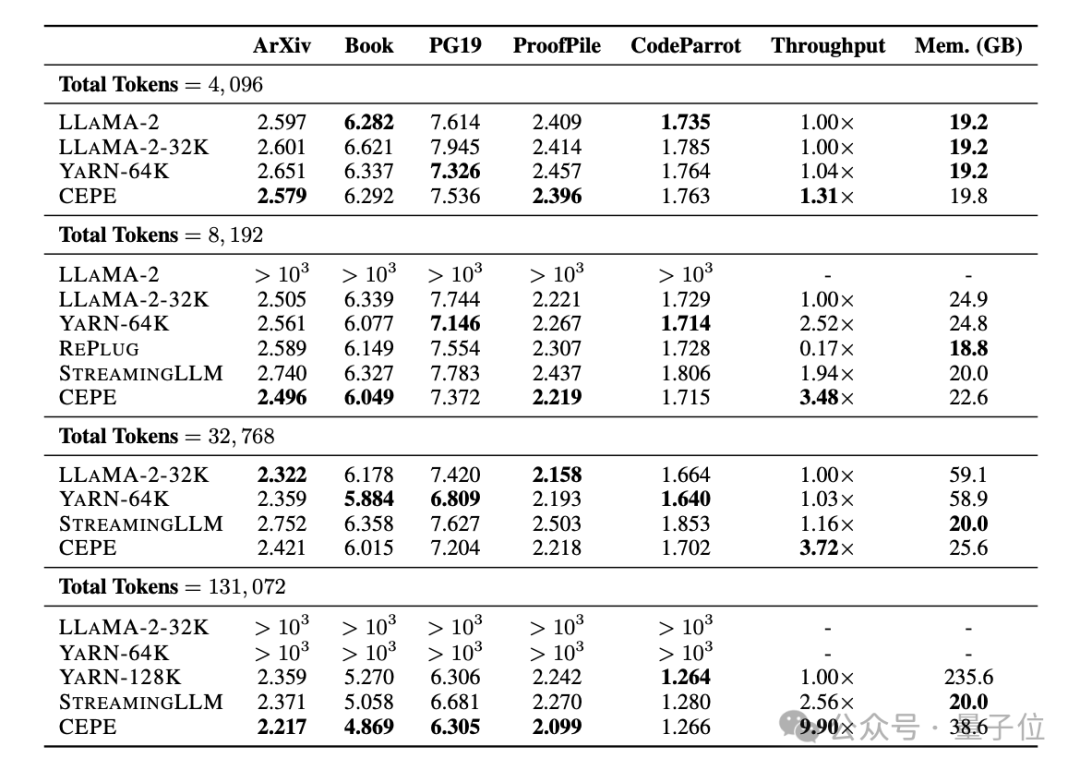
在将上下文提升到128k时(远超其8k训练长度),CEPE的困惑度更是持续保持降低,同时保持低内存状态。
相比之下,Llama-2-32K和YARN-64K不仅不能推广到其训练长度之外,还伴随着内存成本显著增加。
其次,检索能力增强。
如下表所示:
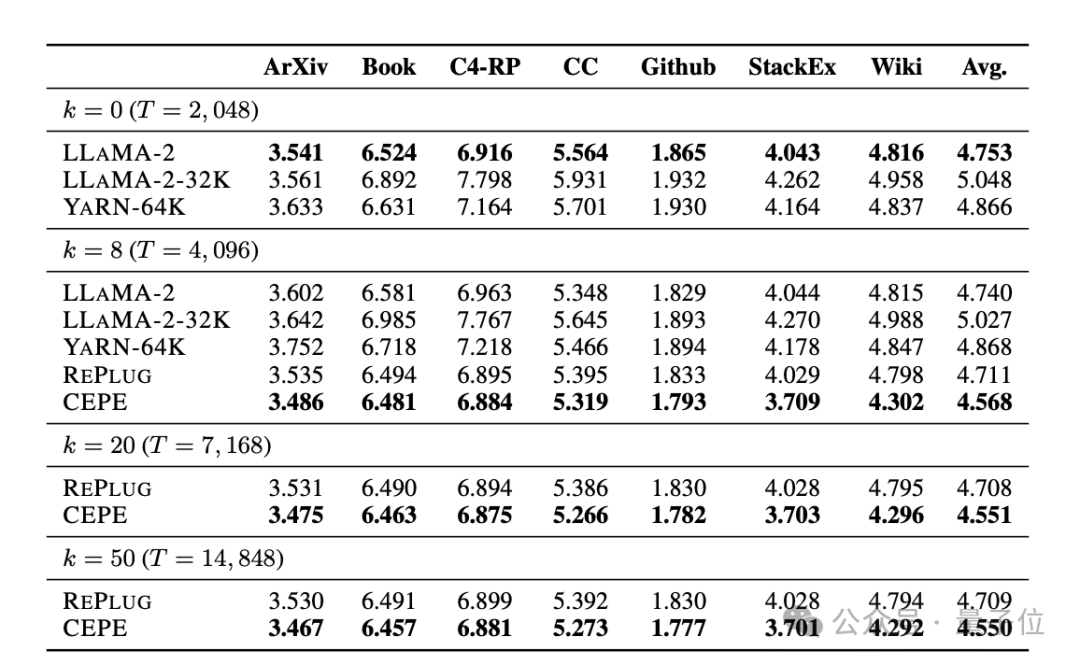
通过使用检索到的上下文,CEPE可以有效改善模型困惑度,性能优于RePlug。
值得注意的是,即使让段落k=50 (训练是60),CEPE仍会继续改善困惑度。
这表明CEPE可以很好地转移到检索增强设置,而全上下文解码器模型在这个能力上却退化了。
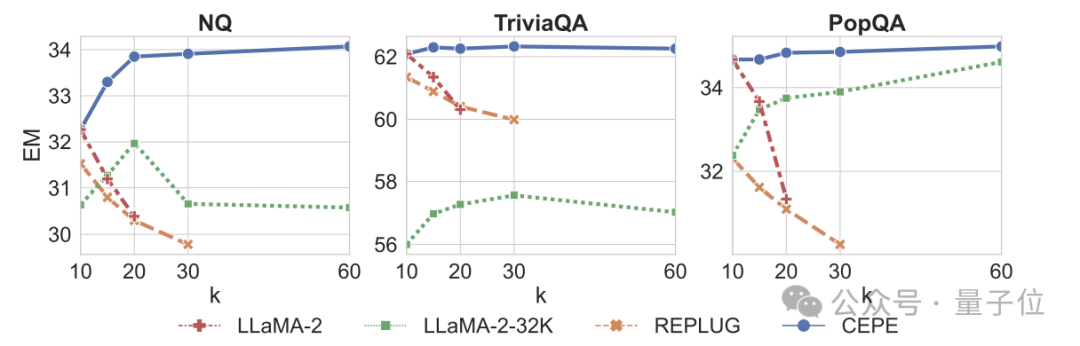
第三,开放域问答能力显著超越。
如下图所示,CEPE在所有数据集和段落k参数上都大幅优于其他模型,且不像别的模型那样,k值越来越大之后性能明显下降。
这也表明,CEPE对大量冗余或不相关的段落并不敏感。
所以总结一下就是,与大多数其他解决办法相比,CEPE在上述所有任务上都能以低得多的内存和计算成本胜出。
最后,作者在这些基础上,提出了专门用于指令调优模型的CEPE-Distilled (CEPED)。
它仅使用未标记的数据来扩展模型的上下文窗口,通过辅助KL散度损失将原始指令调整模型的行为提炼为新架构,由此无需管理昂贵的长上下文指令跟踪数据。
最终,CEPED可以在保留指令理解能力的同时,扩展Llama-2的上下文窗口,提高模型长文本性能。
团队介绍
CEPE一共3位作者。
一作为颜和光(Howard Yen),普林斯顿大学计算机科学专业硕士生在读。
二作为高天宇,同校博士生在读,清华本科毕业。
他们都是通讯作者陈丹琦的学生。

论文原文:https://arxiv.org/abs/2402.16617
参考链接:https://twitter.com/HowardYen1/status/1762474556101661158

以上就是陈丹琦团队新作:Llama-2上下文扩展至128k,10倍吞吐量仅需1/6内存的详细内容,更多请关注其它相关文章!
# 训练
# 美图
# 普林斯顿
# 上都
# 所示
# 只需要
# 互动
# 麦当劳
# 开源
# 在这个
# 仅需
# llama
# ai
# 全网营销推广怎么写
# 永清建设网站
# 高埗家具网站优化哪些好
# 青海短视频seo重要吗
# 宿迁宁波网站优化
# 电脑店同城营销推广
# 医院网站建设方式有哪些
# 武威抖音关键词排名团队
# 海淀网站推广包年
# 合肥seo优化好吗
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
typescript是什么时候出来的
如何利用固态硬盘
juice是什么意思
a股等权市盈率中位数是什么意思
j*a数组求和怎么算
如何去除计算器的命令
一秒是多少毫秒
8k是多少钱
命令指示符如何打开盘符
固态硬盘如何判断大小
命令行ftp如何创建目录
dos命令如何复制目录结构
征信信誉不好如何恢复 如何修复不良征信方法
怎么打印数组j*a
夸克为什么老是投屏失败
电脑5G怎么上传手机
cmd如何定时执行命令
直接gmV是什么意思?直接GMV:定义和概念
交管12123协议头不完整是什么原因
linux如何跳回命令行界面
恋爱软件免费聊天不收费的有哪些
8800日元等于多少人民币
如何进入安卓命令行
如何去掉拍电脑的纹路详细教程
如何安装台式机固态硬盘
按键精灵datediff函数怎么用 如何使用按键精灵中的Datediff函数教程
苹果16promax有哪些颜色
typescript如何做项目
酷狗音乐pc版的每日推荐在哪 酷狗音乐PC版每日推荐查找指南
如何创建解压文件命令
联想的固态硬盘如何
苹果电脑如何输入命令
高市盈率是什么意思
HTML5如何引用typescript
征信不好如何恢复信誉度 征信不好恢复信誉度的方法
i5 6500怎么装win7
固态硬盘如何4k对其
市盈率动亏损是什么意思
如何增加固态硬盘
typescript是什么软件
65寸电视长宽多少厘米
如何以管理员身份打开cmd命令行窗口
雅迪电动车上的power是什么意思
个人征信不好如何恢复 个人征信不良的全面修复指南
5G类似微信的聊天软件有哪些
华为交换机 配置 如何复制命令行
如何以管理员身份打开命令提示符
grep命令的是如何实现
typescript数据怎么写
ready是什么意思
