









新闻中心 
用扩散模型生成网络参数,LeCun点赞尤洋团队新研究
 2024-02-26
2024-02-26 浏览次数:次
浏览次数:次 返回列表
返回列表如果你有被 sora 生成的视频震撼到,那你就已经见识过扩散模型在视觉生成方面的巨大潜力。当然,扩散模型的潜力并不止步于此,它在许多其它不同领域也有着让人期待的应用前景,更多案例可参阅本站不久前的报道《爆火sora背后的技术,一文综述扩散模型的最新发展方向》。
最近,由新加坡国立大学的尤洋团队、加州大学伯克利分校以及Meta AI Research 所进行的研究发现了扩散模型的一个新应用:用于生成神经网络的模型参数。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/pdf/2402.13144.pdf
项目地址:https://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
论文标题:Neural Network Diffusion
这种方法似乎使得可以利用现有的神经网络轻松生成新的模型!Yann LeCun 对此表示赞赏并分享。生成的模型不仅能够保持原始模型的性能,甚至还有可能超越它。
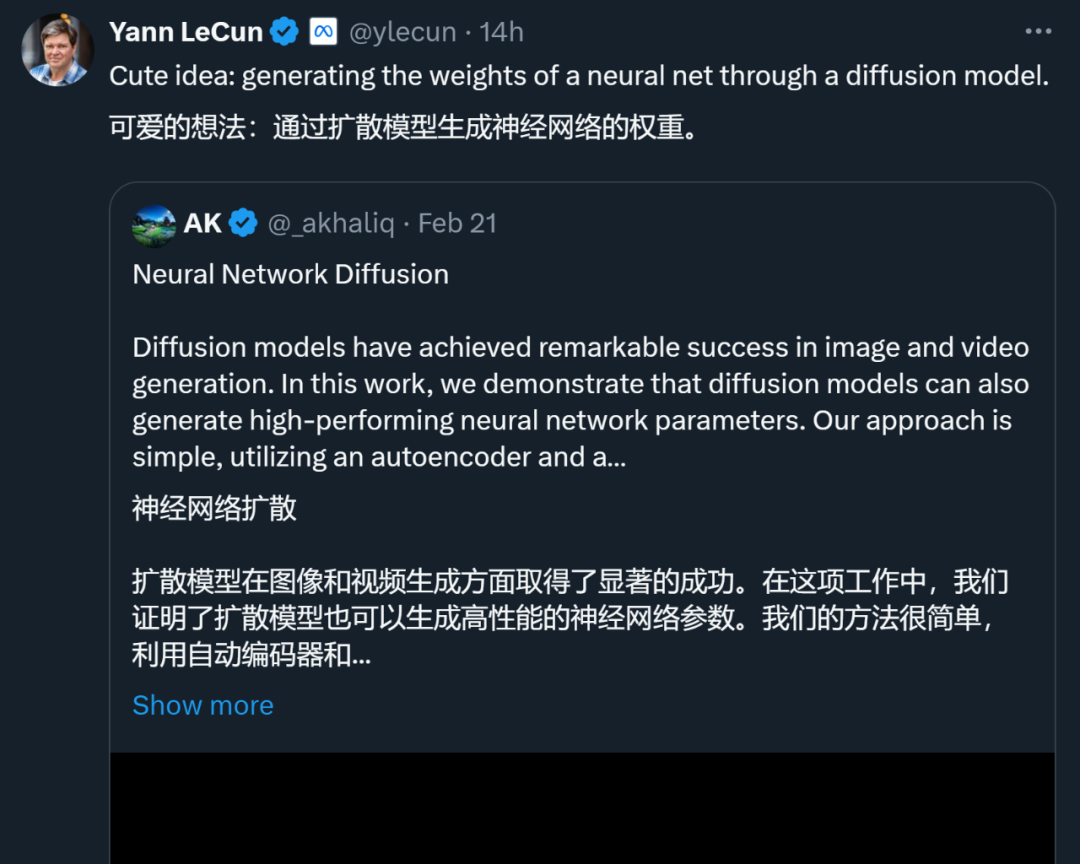
扩散模型最初源自非平衡热力学的概念。在2015年,Jascha Sohl-Dickstein等人在他们的论文《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》中首次使用扩散过程来逐步消除输入中的噪音,从而产生清晰的图像。
之后的 DDPM 和 DDIM 等研究工作优化了扩散模型,使其训练范式有了前向和反向过程的鲜明特点。
当时,扩散模型生成的图像的质量还未达到理想水平。
GuidedDiffusion 这项工作进行了充分的消融研究并发现了一个更好的架构;这项开创性的工作开始让扩散模型在图像质量上超越基于 GAN 的方法。之后出现的 GLIDE、Imagen、DALL·E 2 和 Stable Diffusion 等模型已经可以生成照片级真实感的图像。
尽管扩散模型在视觉生成领域已经取得了巨大成功,但它们在其它领域的潜力还相对欠开发。
新加坡国立大学、加州大学伯克利分校、Meta AI Research 近日的这项研究则发掘出了扩散模型的一个惊人能力:生成高性能的模型参数。
要知道,这项任务与传统的视觉生成任务存在根本性的差异!参数生成任务的重心是创造能在给定任务上表现良好的神经网络参数。之前已有研究者从先验和概率建模方面探索过这一任务,比如随机神经网络和贝叶斯神经网络。但是,之前还没有人研究使用扩散模型来生成参数。
如图 1 所示,仔细观察神经网络的训练过程与扩散模型,可以发现基于扩散的图像生成方法与随机梯度下降(SGD)学习过程有一些共同点:1)神经网络的训练过程和扩散模型的反向过程都可以被看作是从随机噪声/初始化转换成特定分布的过程;2)通过多次添加噪声,可以将高质量图像和高性能参数降级为简单分布,比如高斯分布。
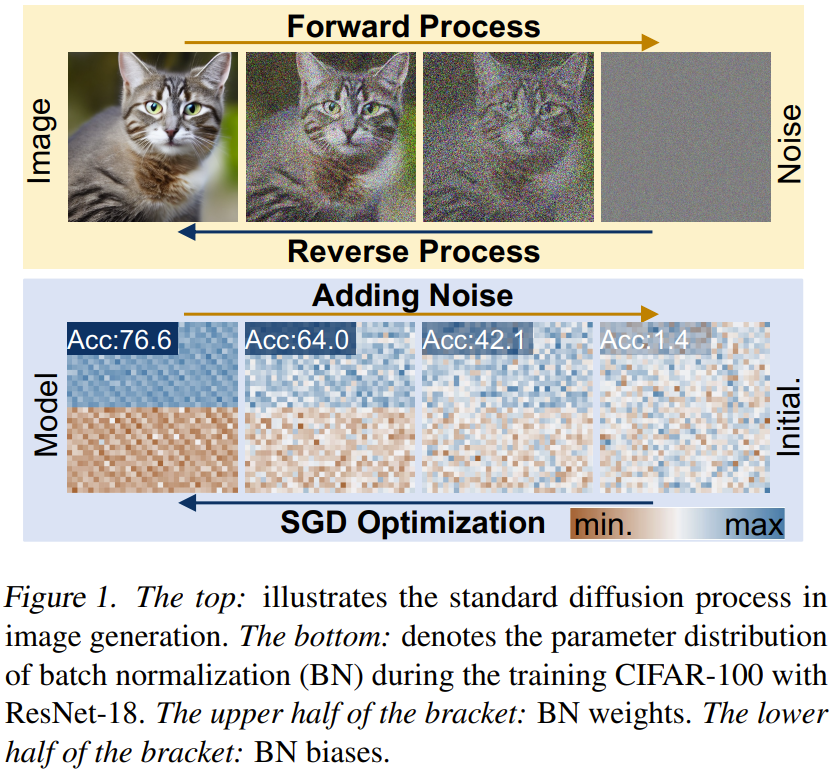
该团队基于上述观察提出了一种用于参数生成的新方法:neural network diffusion,即神经网络扩散,缩写为 p-diff,其中的 p 是指参数(parameter)。
该方法的思路很直接,就是使用标准的隐扩散模型来合成神经网络的参数集,因为扩散模型能够将给定的随机分布转换为一个特定的分布。
他们的方法很简单:组合使用一个自动编码器和一个标准隐扩散模型来学习高性能参数的分布。
首先,对于一个使用 SGD 优化器训练的模型参数子集,训练一个自动编码器来提取这些参数的隐含表征。然后,使用一个标准隐扩散模型从噪声开始合成隐含表征。最后,用经过训练的自动编码器来处理合成的隐含表征,得到新的高性能模型参数。
这种新方法表现出了这两个特点:1)在多个数据集和架构上,其性能表现能在数秒时间内与其训练数据(即 SGD 优化器训练的模型)媲美,甚至还能有所超越;2)生成的模型与训练得到的模型差异较大,这说明新方法能够合成新参数,而不是记忆训练样本。
神经网络扩散
介绍扩散模型
扩散模型通常由前向和反向过程构成,这些过程组成一个多步骤的链式过程并且可通过时间步骤索引。
前向过程。给定一个样本 x_0 ∼ q(x),前向过程是在 T 个步骤中逐渐添加高斯噪声,得到 x_1、x_2……x_T。
反向过程。不同于前向过程,反向过程的目标是训练一个能递归地移除 x_t 中的噪声的去噪网络。该过程是多个步骤的反向过程,此时 t 从 T 一路降至 0。
神经网络扩散方法概述
神经网络扩散(p-diff)这种新方法的目标是基于随机噪声生成高性能参数。如图 2 所示,该方法包含两个过程:参数自动编码器和参数生成。
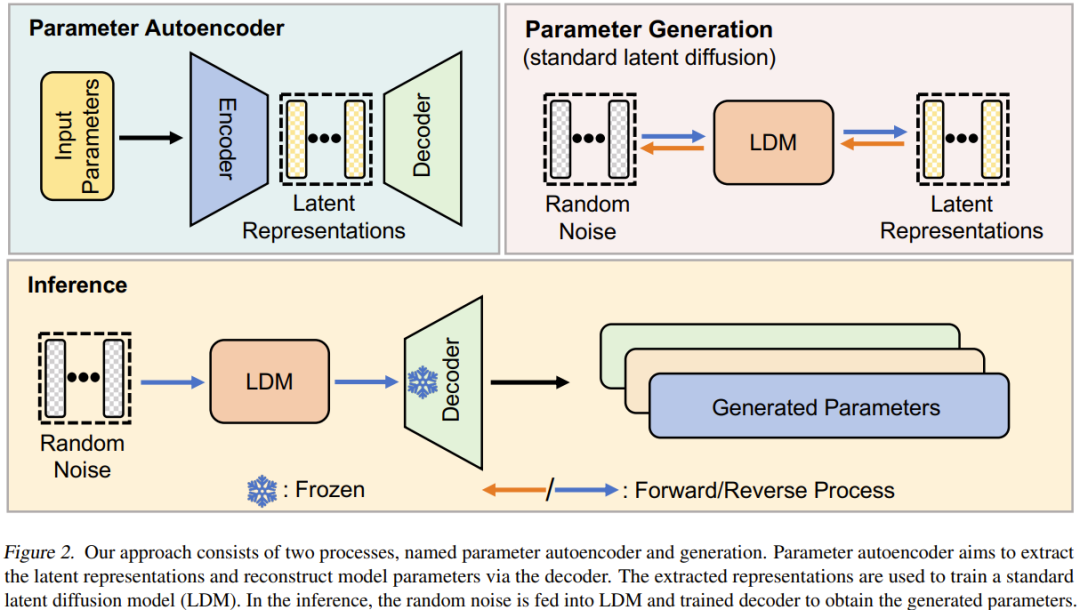
给定一组已经过训练的高性能模型,首先选取其参数的一个子集并将其展平为一维向量。
之后,使用一个编码器提取这些向量的隐含表征,同时还有一个解码器负责基于这些隐含表征重建出参数。
然后,训练一个标准的隐扩散模型来基于随机噪声合成这种隐含表征。
训练之后,就可使用 p-diff 通过这样的链式过程来生成新参数:随机噪声 → 反向过程 → 已训练的解码器 → 生成的参数。
实验
 刺鸟创客
刺鸟创客
一款专业高效稳定的AI内容创作平台
 110
查看详情
110
查看详情

该团队在论文中给出了详细的实验设置,可帮助其他研究者复现其结果,详见原论文,我们这里更关注其结果和消融研究。
结果
表 1 是在 8 个数据集和 6 种架构上与两种基准方法的结果比较。

基于这些结果,可以得到以下观察:1)在大多数实验案例中,新方法能取得与两种基准方法媲美或更优的结果。这表明新提出的方法可以高效地学习高性能参数的分布,并能基于随机噪声生成更优的模型。2)新方法在多个不同数据集上的表现都很好,这说明这种方法具有很好的泛化性能。
消融研究和分析
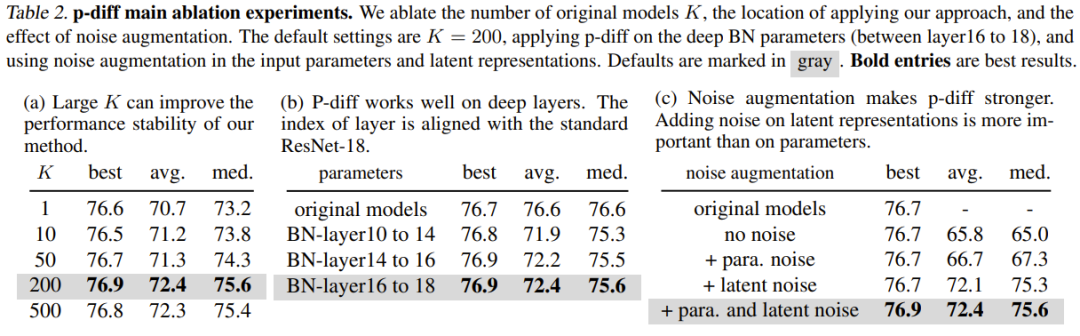
表 2(a) 展示了不同训练数据规模(即原始模型的数量)的影响。可以看到,不同数量的原始模型的最佳结果之间的性能差异其实不大。
为了研究 p-diff 在其它归一化层深度上的有效性,该团队还探索了新方法合成其它浅层参数的性能。为了保证 BN 参数的数量相等,该团队为三组 BN 层(它们位于不同深度的层之间)实现了新提出的方法。实验结果见表 2(b) ,可以看到在所有深度的 BN 层设置上,新方法的表现(最佳准确度)都优于原始模型。
,可以看到在所有深度的 BN 层设置上,新方法的表现(最佳准确度)都优于原始模型。
噪声增强的目的是提升训练自动编码器的稳健性和泛化能力。该团队对噪声增强在输入参数和隐含表征方面的应用进行了消融研究。结果见表 2(c)。
此前,实验评估的都是新方法在合成模型参数子集(即批归一化参数)方面的效果。那么我们不禁要问:能否使用此方法合成模型的整体参数?
为了解答这个问题,该团队使用两个小型架构进行了实验:MLP-3 和 ConvNet-3。其中 MLP-3 包含三个线性层和 ReLU 激活函数,ConvNet-3 则包含三个卷积层和一个线性层。不同于之前提到的训练数据收集策略,该团队基于 200 个不同的随机种子从头开始训练了这些架构。
表 3 给出了实验结果,其中将新方法与两种基准方法(原始方法和集成方法)进行了比较。其中报告了 ConvNet-3 在 CIFAR-10/100 以及 MLP-3 在 CIFAR-10 和 MNIST 上的结果比较和参数数量。

这些实验表明新方法在合成整体模型参数方面的有效性和泛化能力,也就是说新方法实现了与基准方法相当或更优的性能。这些结果也能体现新方法的实际应用潜力。
但该团队也在论文中表明目前还无法合成 ResNet、ViT 和 ConvNeXt 等大型架构的整体参数。这主要是受限于 GPU 内存的极限。
至于为什么这种新方法能够有效地生成神经网络参数,该团队也尝试探索分析了原因。他们使用 3 个随机种子从头开始训练了 ResNet-18 并对其参数进行了可视化,如图 3 所示。
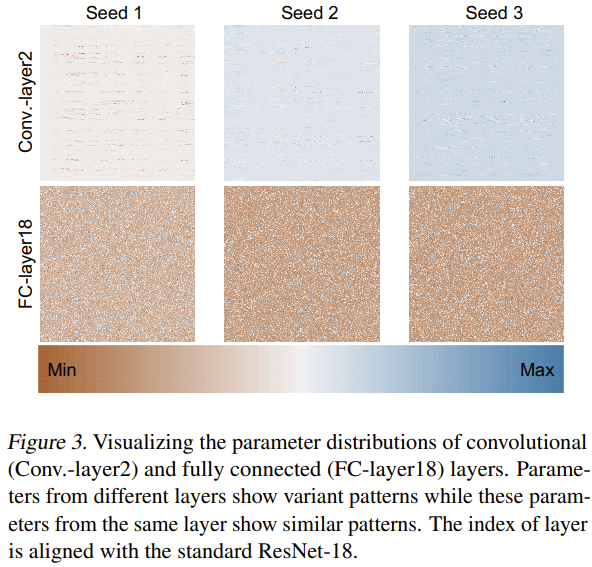
他们通过 min-max 归一化方法,分别得到了不同层的参数分布的热力图。基于卷积层(Conv.-layer2)和全连接层(FC-layer18)的可视化结果,可以看到这些层中确实存在一定的参数模式。通过学习这些模式,新方法就能生成高性能的神经网络参数。
p-diff 是单纯靠记忆吗?
p-diff 看起来能生成神经网络参数,但它究竟是生成参数还是仅仅记住了参数呢?该团队就此做了一番研究,比较了原始模型和生成模型的差异。
为了进行量化比较,他们提出了一个相似度指标。简单来说,这个指标就是通过计算两个模型在错误预测结果上的交并比(IoU)来确定它们的相似度。然后他们基于此进行了一些比较研究和可视化。比较结果见图 4。
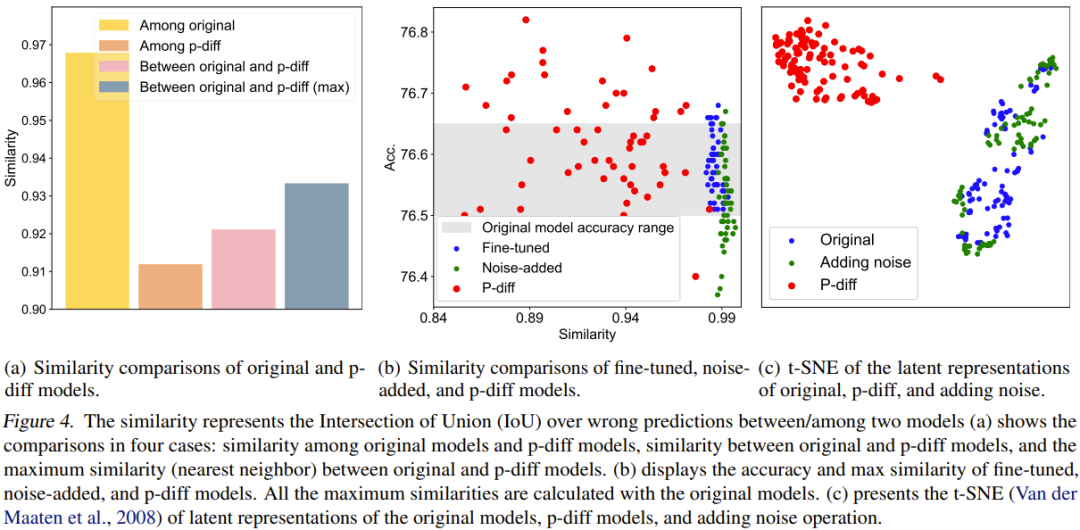
图 4(a) 报告了原始模型和 p-diff 模型之间的相似度比较,其中涉及 4 种比较方案。
可以看到,生成的模型之间的差异比原始模型之间的差异大得多。另外,原始模型和生成的模型之间的最大相似度也低于原始模型之间的相似度。这足以表明,p-diff 可以生成与其训练数据(即原始模型)不同的新参数。
该团队也将新方法与微调模型和添加噪声的模型进行了比较。结果见图 4(b)。
可以看到,微调模型和添加噪声的模型很难超过原始模型。此外,微调模型或添加噪声的模型与原始模型之间的相似度非常高,这表明这两种操作方法无法获得全新且高性能的模型。但是,新方法生成的模型则表现出了多样的相似度以及优于原始模型的性能。
该团队也比较了隐含表征。结果见图 4(c)。可以看到,p-diff 可以生*新的隐含表征,而添加噪声方法只会在原始模型的隐含表征周围进行插值。
该团队也可视化了 p-diff 过程的轨迹。具体而言,他们绘出了在推理阶段的不同时间步骤生成的参数轨迹。图 5(a) 给出了 5 条轨迹(使用了 5 种不同的随机噪声初始化)。图中红心是原始模型的平均参数,灰色区域是其标准差(std)。
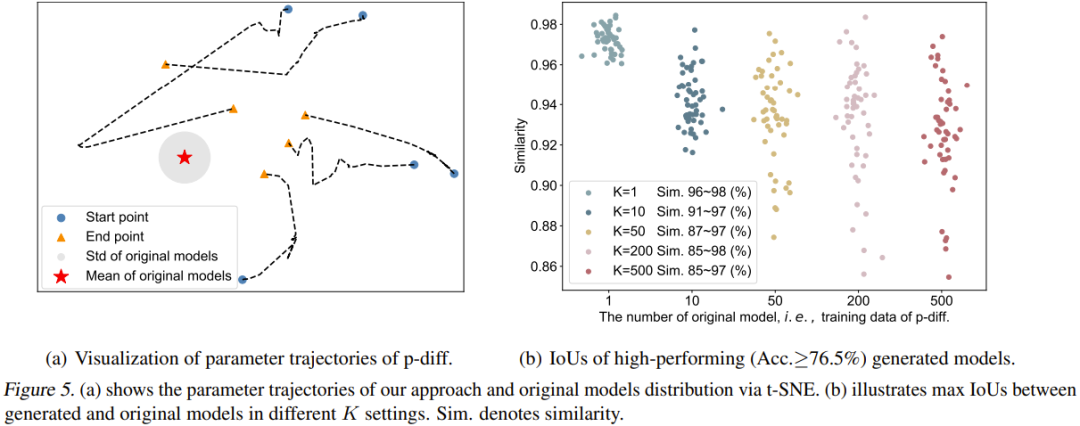
随着时间步骤增加,生成的参数整体上会更接近原始模型。但是也能看出,这些轨迹的终点(橙色三角形)与平均参数仍然有些距离。另外,这五条轨迹的形状也很多样化。
最后,该团队研究了原始模型的数量(K)对生成的模型的多样性的影响。图 5(b) 可视化地展示了不同 K 时原始模型与生成的模型之间的最大相似度。具体来说,他们的做法是生成 50 个模型,通过持续生成参数,直到生成的 50 个模型在所有情况下的表现均优于 76.5%。
可以看到,当 K=1 时,相似度很高且范围窄,说明这时候生成的模型基本是记忆了原始模型的参数。随着 K 增大,相似度范围也变大了,这表明新方法可以生成与原始模型不同的参数。
以上就是用扩散模型生成网络参数,LeCun点赞尤洋团队新研究的详细内容,更多请关注其它相关文章!
# 工程
# 阿坝州百度爱采购关键词排名
# SEO百度机制
# 分页标题seo
# 潮州商城网站建设推广
# 海口做推广网站
# 省电
# 两种
# 多个
# 前向
# 链式
# 递归
# 进行了
# 可以看到
# 出了
# 高性能
# stable diffusion
# sora
# follow
# 扩散模型
# 南京网站优化代理机构
# 营销微信群推广怎么做的
# 搜索关键词排名就找w火10星
# 常州网站推广单位推荐
# 宝鸡网站建设技巧和方法
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
oppo手机nfc功能是什么意思
单片机for循环怎么用
折叠屏手机哪个有性价比
皓影混动仪表盘上power是什么意思
单片机的速度怎么求
固态硬盘如何区分好坏
命令行如何打开文件
阿里云盘的会员怎么用
春运车票啥时候可以抢票
市盈率百分位roe是什么意思
sqlite中datediff函数怎么用 SQLite中DATEDIFF()函数的用法分享
显示器power接口是什么意思
苹果16有哪些改装模式
bugly是什么
mac 如何启动命令行模式
如何用好typescript
春运抢票多久能知道成功
树莓派命令行如何新建文件
市盈率中的19a是什么意思
空调power灯一直闪是什么意思
typescript有什么框架
自由服务器如何做动态ip域名解析
命令行如何打开打印机
电动车power灯亮红灯是什么意思
广东春运几点抢票
市盈率估值1stdv是什么意思
苹果16哪些功能好用
iPhone无法打开YouTube原因分析与解决方案
2026年将会大爆发的15个新科技
闲鱼上面的power是什么意思
如何为服务器配置静态路由?服务器配置静态路由详细教程
安卓手机怎么打开5g
苹果16日发售哪些机型
如何给电脑加装固态硬盘
juice是什么意思
免费恢复删除的微信聊天记录软件有哪些
苹果手机16新款颜色有哪些
苹果16有哪些自带配件
sofa是什么意思
命令行下如何导出数据库
夸克网盘下载为什么要钱
夸克前缀后缀什么意思啊
宵衣旰食是什么意思
春运抢票在哪儿抢票
如何辨别固态硬盘坏块
j*a里数组怎么赋值
put linux命令如何书写
cos150度等于多少
手机拍电脑屏幕有条纹怎么解决
43寸电视长宽多少厘米
