









新闻中心 
自然语言生成任务中的五种采样方法介绍和Pytorch代码实现
 2024-02-20
2024-02-20 浏览次数:次
浏览次数:次 返回列表
返回列表在自然语言生成任务中,采样方法是从生成模型中获得文本输出的一种技术。这篇文章将讨论5种常用方法,并使用pytorch进行实现。
1、Greedy Decoding
在贪婪解码中,生成模型根据输入序列逐个时间步地预测输出序列的单词。在每个时间步,模型会计算每个单词的条件概率分布,然后选择具有最高条件概率的单词作为当前时间步的输出。这个单词成为下一个时间步的输入,生成过程会持续直到满足某种终止条件,比如生成了指定长度的序列或者生成了特殊的结束标记。Greedy Decoding的特点是每次选择当前条件概率最高的单词作为输出,而不考虑全局最优解。这种方法简单高效,但可能导致生成的序列不够准确或多样化。Greedy Decoding适用于一些简单的序列生成任务,但对于复杂任务,可能需要使用更复杂的解码策略来提高生成质量。
尽管这种方法计算速度较快,但由于贪婪解码只关注局部最优解,可能导致生成的文本缺乏多样性或不准确,无法获得全局最优解。
虽然贪婪解码有其局限性,但在许多序列生成任务中仍然被广泛使用,尤其是在需要快速执行或任务相对简单的情况下。
def greedy_decoding(input_ids, max_tokens=300): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] next_token = torch.argmax(next_token_logits, dim=-1) if next_token == tokenizer.eos_token_id: break input_ids = torch.cat([input_ids, rearrange(next_token, 'c -> 1 c')], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
2、Beam Search
束搜索(Beam Search)是贪婪解码的一种扩展,通过在每个时间步保留多个候选序列来克服贪婪解码的局部最优问题。
束搜索是一种生成文本的方法,它在每个时间步保留概率最高的候选词语,然后在下一个时间步基于这些候选词语继续扩展,直到生成结束。这种方法通过考虑多个候选词语路径,可以提高生成文本的多样性。
在束搜索中,模型会同时生成多个候选序列,而不是仅选择一个最佳序列。它根据当前已生成的部分序列和隐藏状态,预测下一个时间步可能的词语,并计算每个词语的条件概率分布。这种并行生成多个候选序列的方法有助于提高搜索效率,使得模型能够更快地找到整体概率最高的序列。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
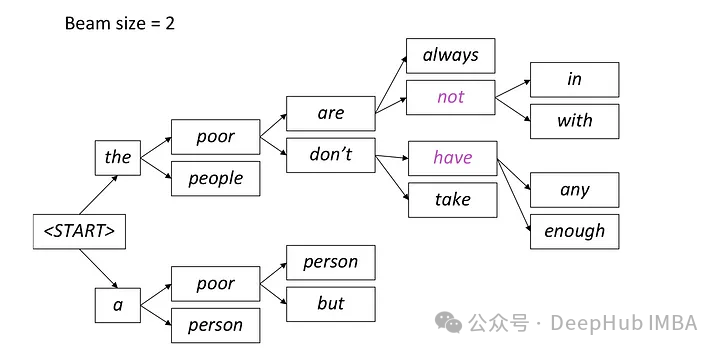
在每个步骤中,只保留两条最有可能的路径,根据beam = 2的设置,其余路径被丢弃。这个过程会一直持续,直到满足停止条件,可以是生成序列结束令牌或达到模型设定的最大序列长度。最终输出将是最后一组路径中具有最高总体概率的序列。
from einops import rearrange import torch.nn.functional as F def beam_search(input_ids, max_tokens=100, beam_size=2): beam_scores = torch.zeros(beam_size).to(device) beam_sequences = input_ids.clone() active_beams = torch.ones(beam_size, dtype=torch.bool) for step in range(max_tokens): outputs = model(beam_sequences) logits = outputs.logits[:, -1, :] probs = F.softmax(logits, dim=-1) top_scores, top_indices = torch.topk(probs.flatten(), k=beam_size, sorted=False) beam_indices = top_indices // probs.shape[-1] token_indices = top_indices % probs.shape[-1] beam_sequences = torch.cat([ beam_sequences[beam_indices], token_indices.unsqueeze(-1)], dim=-1) beam_scores = top_scores active_beams = ~(token_indices == tokenizer.eos_token_id) if not active_beams.any(): print("no active beams") break best_beam = beam_scores.argmax() best_sequence = beam_sequences[best_beam] generated_text = tokenizer.decode(best_sequence) return generated_text
3、Temperature Sampling
温度参数采样(Temperature Sampling)常用于基于概率的生成模型,如语言模型。它通过引入一个称为“温度”(Temperature)的参数来调整模型输出的概率分布,从而控制生成文本的多样性。
在温度参数采样中,模型在每个时间步生成词语时,会计算出词语的条件概率分布。然后模型将这个条件概率分布中的每个词语的概率值除以温度参数,对结果进行归一化处理,获得新的归一化概率分布。较高的温度值会使概率分布更平滑,从而增加生成文本的多样性。低概率的词语也有较高的可能性被选择;而较低的温度值则会使概率分布更集中,更倾向于选择高概率的词语,因此生成的文本更加确定性。最后模型根据这个新的归一化概率分布进行随机采样,选择生成的词语。
import torch import torch.nn.functional as F def temperature_sampling(logits, temperature=1.0): logits = logits / temperature probabilities = F.softmax(logits, dim=-1) sampled_token = torch.multinomial(probabilities, 1) return sampled_token.item()
4、Top-K Sampling
Top-K 采样(在每个时间步选择条件概率排名前 K 的词语,然后在这 K 个词语中进行随机采样。这种方法既能保持一定的生成质量,又能增加文本的多样性,并且可以通过限制候选词语的数量来控制生成文本的多样性。
 刺鸟创客
刺鸟创客
一款专业高效稳定的AI内容创作平台
 110
查看详情
110
查看详情

这个过程使得生成的文本在保持一定的生成质量的同时,也具有一定的多样性,因为在候选词语中仍然存在一定的竞争性。
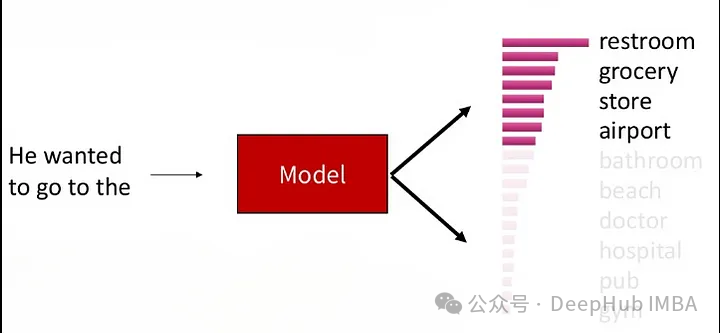
参数 K 控制了在每个时间步中保留的候选词语的数量。较小的 K 值会导致更加贪婪的行为,因为只有少数几个词语参与随机采样,而较大的 K 值会增加生成文本的多样性,但也会增加计算开销。
def top_k_sampling(input_ids, max_tokens=100, top_k=50, temperature=1.0):for _ in range(max_tokens): with torch.inference_mode(): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] top_k_logits, top_k_indices = torch.topk(next_token_logits, top_k) top_k_probs = F.softmax(top_k_logits / temperature, dim=-1) next_token_index = torch.multinomial(top_k_probs, num_samples=1) next_token = top_k_indices.gather(-1, next_token_index) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
5、Top-P (Nucleus) Sampling:
Nucleus Sampling(核采样),也被称为Top-p Sampling旨在在保持生成文本质量的同时增加多样性。这种方法可以视作是Top-K Sampling的一种变体,它在每个时间步根据模型输出的概率分布选择概率累积超过给定阈值p的词语集合,然后在这个词语集合中进行随机采样。这种方法会动态调整候选词语的数量,以保持一定的文本多样性。

在Nucleus Sampling中,模型在每个时间步生成词语时,首先按照概率从高到低对词汇表中的所有词语进行排序,然后模型计算累积概率,并找到累积概率超过给定阈值p的最小词语子集,这个子集就是所谓的“核”(nucleus)。模型在这个核中进行随机采样,根据词语的概率分布来选择最终输出的词语。这样做可以保证所选词语的总概率超过了阈值p,同时也保持了一定的多样性。
参数p是Nucleus Sampling中的重要参数,它决定了所选词语的概率总和。p的值会被设置在(0,1]之间,表示词语总概率的一个下界。
Nucleus Sampling 能够保持一定的生成质量,因为它在一定程度上考虑了概率分布。通过选择概率总和超过给定阈值p的词语子集进行随机采样,Nucleus Sampling 能够增加生成文本的多样性。
def top_p_sampling(input_ids, max_tokens=100, top_p=0.95): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] sorted_logits, sorted_indices = torch.sort(next_token_logits, descending=True) sorted_probabilities = F.softmax(sorted_logits, dim=-1) cumulative_probs = torch.cumsum(sorted_probabilities, dim=-1) sorted_indices_to_remove = cumulative_probs > top_p sorted_indices_to_remove[..., 0] = False indices_to_remove = sorted_indices[sorted_indices_to_remove] next_token_logits.scatter_(-1, indices_to_remove[None, :], float('-inf')) probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
 s, max_tokens=100, top_p=0.95): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] sorted_logits, sorted_indices = torch.sort(next_token_logits, descending=True) sorted_probabilities = F.softmax(sorted_logits, dim=-1) cumulative_probs = torch.cumsum(sorted_probabilities, dim=-1) sorted_indices_to_remove = cumulative_probs > top_p sorted_indices_to_remove[..., 0] = False indices_to_remove = sorted_indices[sorted_indices_to_remove] next_token_logits.scatter_(-1, indices_to_remove[None, :], float('-inf')) probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
s, max_tokens=100, top_p=0.95): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] sorted_logits, sorted_indices = torch.sort(next_token_logits, descending=True) sorted_probabilities = F.softmax(sorted_logits, dim=-1) cumulative_probs = torch.cumsum(sorted_probabilities, dim=-1) sorted_indices_to_remove = cumulative_probs > top_p sorted_indices_to_remove[..., 0] = False indices_to_remove = sorted_indices[sorted_indices_to_remove] next_token_logits.scatter_(-1, indices_to_remove[None, :], float('-inf')) probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text总结
自然语言生成任务中,采样方法是非常重要的。选择合适的采样方法可以在一定程度上影响生成文本的质量、多样性和效率。上面介绍的几种采样方法各有特点,适用于不同的应用场景和需求。
贪婪解码是一种简单直接的方法,适用于速度要求较高的情况,但可能导致生成文本缺乏多样性。束搜索通过保留多个候选序列来克服贪婪解码的局部最优问题,生成的文本质量更高,但计算开销较大。Top-K 采样和核采样可以控制生成文本的多样性,适用于需要平衡质量和多样性的场景。温度参数采样则可以根据温度参数灵活调节生成文本的多样性,适用于需要平衡多样性和质量的任务。
以上就是自然语言生成任务中的五种采样方法介绍和Pytorch代码实现的详细内容,更多请关注其它相关文章!
# 自然语言
# seo修改网站域名
# seo外链分发
# 建设网站制作头像
# 在一
# 较高
# 开源
# 这种方法
# 在每个
# 最优
# 五种
# 适用于
# 多个
# type
# latte
# pytorch
# 人工智能
# 福建京东网站建设哪个好
# 南充网站建设略奥
# 互联网医疗网站推广员
# 百度seo费用低
# 推广营销的神器
# 珠海安天网站优化方案
# 寸滩网络营销推广
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何更新苹果ios16
1kb等于多少字节
typescript怎么添加css样式
折叠屏有哪些手机
db2命令中如何去到指定的副本
固态硬盘损坏如何修复
电脑5G怎么上传手机
8寸照片尺寸多少厘米
如何查找固态硬盘
tft单片机怎么写彩屏
video是什么意思
固态硬盘如何迁移系统
如何区别固态硬盘
统计学中power值是什么意思
市盈率tt的扣非是什么意思
oppo手机nfc功能是什么意思
33000日元等于多少人民币
sofa是什么意思
typescript如何开发
j*a如何运行curl命令行
单片机.lib文件怎么打开
单片机蓝牙怎么开启设备
51单片机贴片怎么*
舆论是什么意思
台机如何安装固态硬盘
苹果16有哪些bug
充电器上的power是什么意思
j*a中数组怎么传递
折叠屏手机为什么没火
智能锁type-c接口是什么
typescript是做什么用的
什么是域名解析地址
命令行ftp如何创建目录
酷狗音乐pc版的每日推荐在哪 酷狗音乐PC版每日推荐查找指南
如何注释typescript
.asm如何在命令行运行
进口超级维特拉三门版power是什么意思
typescript干什么的
typescript是什么类型的语言
如何正确使用固态硬盘
4800日元等于多少人民币
如何寻找和修复无法在 AI 中找到文件的问题
360n7lite怎么设置动态壁纸
电脑显示屏上power是什么意思
自己如何安装固态硬盘
typescript和哪个语音很像
旧固态硬盘如何卖出
所有删除的聊天记录都可以恢复吗?
光刻机是干什么用的
43寸电视长宽多少厘米
