









新闻中心 
如何探索和可视化用于图像中物体检测的 ML 数据
 2024-02-16
2024-02-16 浏览次数:次
浏览次数:次 返回列表
返回列表近年来,人们对深入理解机器学习数据(ml-data)的重要性有了更深刻的认识。然而,由于检测大型数据集通常需要大量的人力和物力投入,因此在计算机视觉领域的广泛应用仍然需要进一步的开发。
通常,在物体检测(Object Detection,属于计算机视觉的一个子集)中,通过定义边界框,来定位图像中的物体,不仅可以识别物体,还能够了解物体的上下文、大小、以及与场景中其他元素的关系。同时,针对类的分布、物体大小的多样性、以及类出现的常见环境进行全面了解,也有助于在评估和调试中发现训练模型中的错误模式,从而更有针对性地选择额外的训练数据。
在实践中,我往往会采取如下方法:
- 利用预训练的模型或基础模型的增强功能,为数据添加结构。例如:创建各种图像嵌入,并采用 t-SNE 或 UMAP 等降维技术。这些都可以生成相似性的地图,从而方便数据的浏览。此外,使用预先训练的模型进行检测,也可以方便提取上下文。
- 使用能够将此类结构与原始数据的统计和审查功能整合在一起的可视化工具。
下面,我将介绍如何使用Renumics Spotlight,来创建交互式的对象检测可视化。作为示例,我将试着:
- 为图像中的人物探测器建立可视化。
- 可视化包括相似性地图、筛选器和统计数据,以便浏览数据。
- 通过地面实况(Ground Truth)和 Ultralytics YOLOv8 的检测详细,查看每一张图像。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
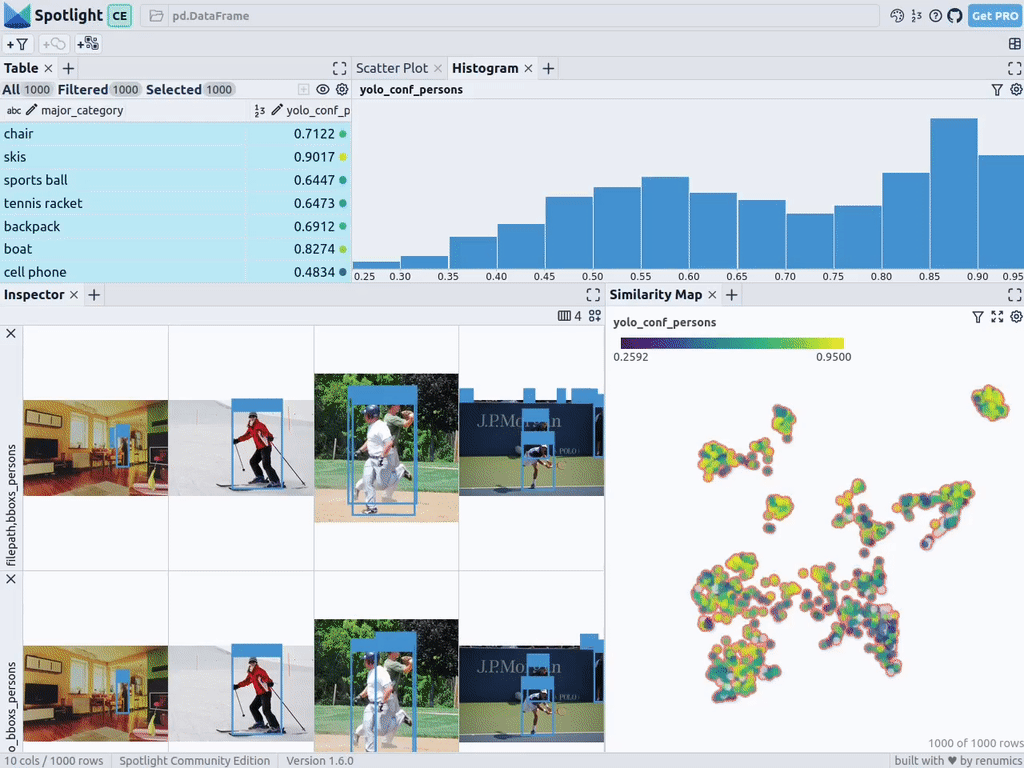
在Renumics Spotlight上的目标可视化。资料来源:作者创建
下载COCO数据集中的人物图像
首先,通过如下命令安装所需的软件包:
!pip install fiftyone ultralytics renumics-spotlight
利用FiftyOne的可恢复性下载功能,您可以从COCO 数据集处下载各种图像。通过简单的参数设置,我们即可下载包含一到多个人物的 1,000 幅图像。具体代码如下:
importpandasaspdimportnumpyasnpimportfiftyone.zooasfoz# 从 COCO 数据集中下载 1000 张带人的图像dataset = foz.load_zoo_dataset( "coco-2017"、split="validation"、label_types=[ "detections"、],classes=["person"]、 max_samples=1000、dataset_name="coco-2017-person-1k-validations"、)
接着,您可以使用如下代码:
def xywh_too_xyxyn(bbox): "" convert from xywh to xyxyn format """ return[bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]].行 = []fori, samplein enumerate(dataset):labels = [detection.labelfordetectioninsample.ground_truth.detections] bboxs = [...bboxs = [xywh_too_xyxyn(detection.bounding_box) fordetectioninsample.ground_truth.detections]bboxs_persons = [bboxforbbox, labelin zip(bboxs, labels)iflabel =="person"] 行。row.append([sample.filepath, labels, bboxs, bboxs_persons])df = pd.DataFrame(row, columns=["filepath","categories", "bboxs", "bboxs_persons"])df["major_category"] = df["categories"].apply( lambdax:max(set(x) -set(["person"]), key=x.count) if len(set(x)) >1 else "only person"。)
将数据准备为 Pandas DataFrame,其中的列包括有:文件路径、边框盒(bounding boxe)类别、边框盒、边框盒包含的人物、以及主要类别(尽管有人物),以指定图像中人物的上下文:
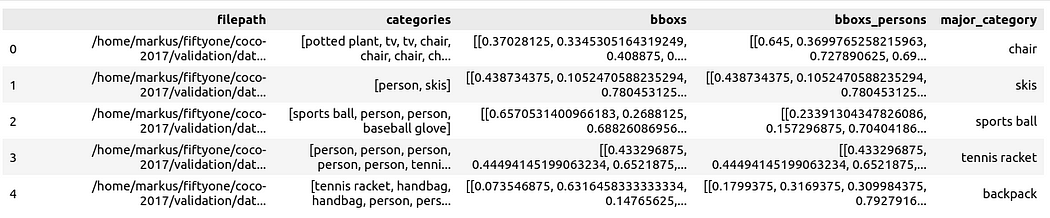
然后,您可以通过 Spotlight 将其可视化:
From renumics import spotlightspotlight.show(df)
您可以使用检查器视图中的添加视图按钮,并在边框视图中选择bboxs_persons和filepath,以显示带有图像的相应边框:
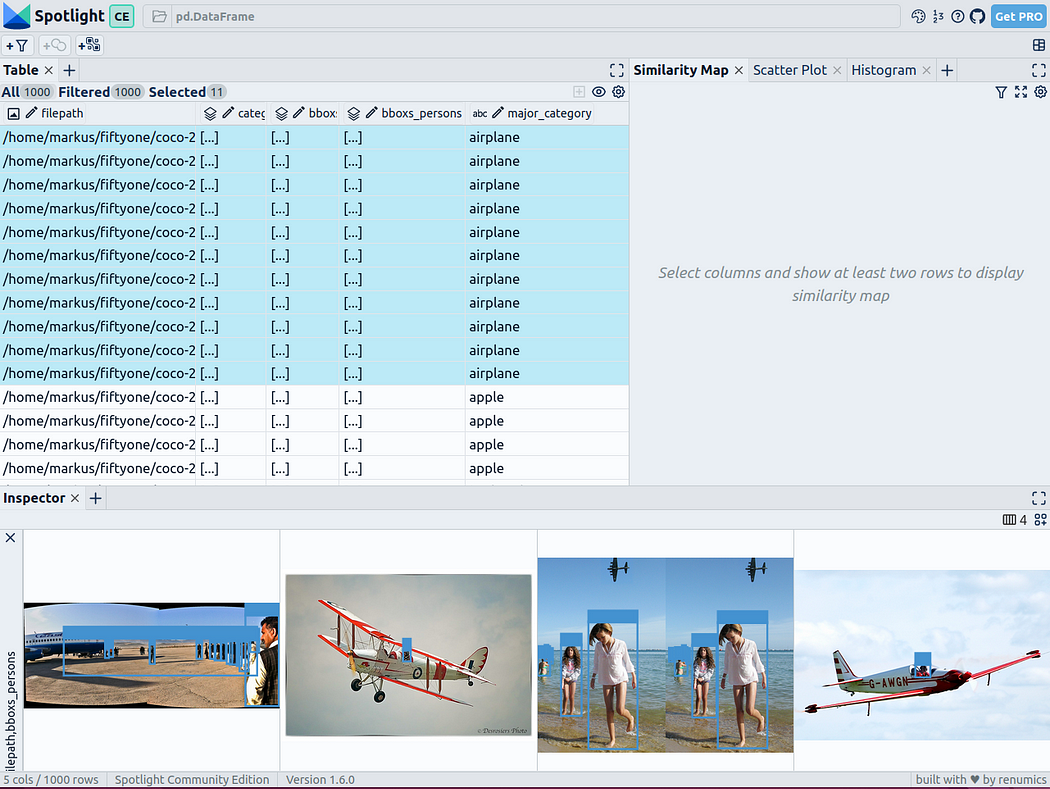
嵌入丰富的数据
要使得数据具有结构性,我们可以采用各种基础模型的图像嵌入(即:密集向量表示)。为此,您可以使用 UMAP 或 t-SNE 等进一步降维技术,将整个图像的Vision Transformer(ViT)嵌入应用到数据集的结构化,从而提供图像的二维相似性图。此外,您还可以使用预训练对象检测器的输出结果,按照包含对象的大小或数量,对数据进行分类,进而构建数据。由于 COCO 数据集已经提供了此方面的信息,因此我们完全可以直接使用它。
由于Spotlight 集成了对google/vit-base-patch16-224-in21k(ViT)模型和UMAP 的支持,因此当您使用文件路径创建各种嵌入时,它将会被自动应用:
spotlight.show(df, embed=["filepath"])
通过上述代码,Spotlight 将各种嵌入进行计算,并应用 UMAP 在相似性地图中显示结果。其中,不同的颜色代表了主要的类别。据此,您可以使用相似性地图来浏览数据:
 刺鸟创客
刺鸟创客
一款专业高效稳定的AI内容创作平台
 110
110
 查看详情
查看详情

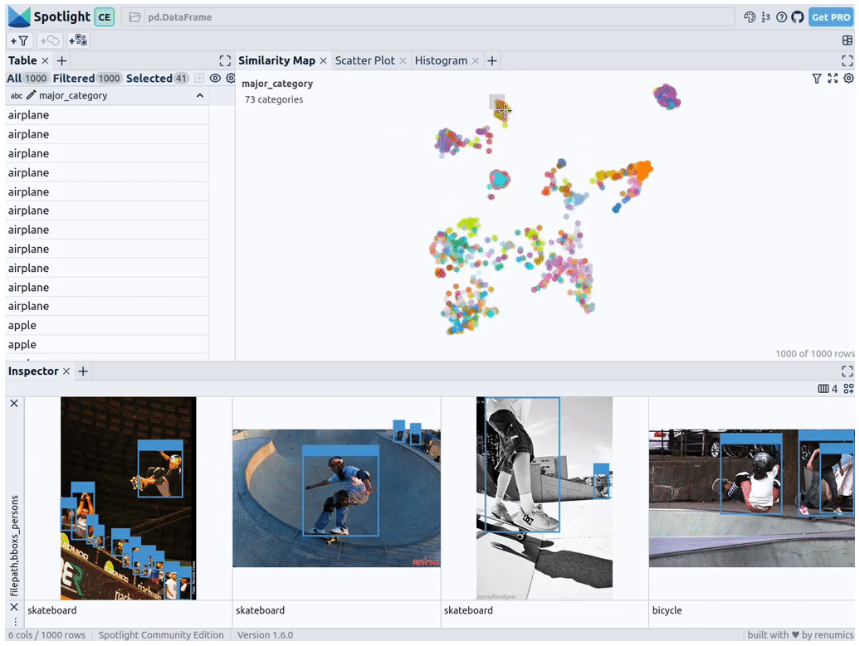
预训练YOLOv8的结果
可用于快速识别物体的Ultralytics YOLOv8,是一套先进的物体检测模型。它专为快速图像处理而设计,适用于各种实时检测任务,特别是在被应用于大量数据时,用户无需浪费太多的等待时间。
为此,您可以首先加载预训练模型:
From ultralytics import YOLOdetection_model = YOLO("yolov8n.pt")
并执行各种检测:
detections = []forfilepathindf["filepath"].tolist():detection = detection_model(filepath)[0]detections.append({ "yolo_bboxs":[np.array(box.xyxyn.tolist())[0]forboxindetection.boxes]、 "yolo_conf_persons": np.mean([np.array(box.conf.tolist())[0]. forboxindetection.boxes ifdetection.names[int(box.cls)] =="person"]), np.mean(]), "yolo_bboxs_persons":[np.array(box.xyxyn.tolist())[0] forboxindetection.boxes ifdetection.names[int(box.cls)] =="person],"yolo_categories": np.array([np.array(detection.names[int(box.cls)])forboxindetection.boxes], "yolo_categories": np.array(),})df_yolo = pd.DataFrame(detections)
在12gb的GeForce RTX 4070 Ti上,上述过程在不到20秒的时间内便可完成。接着,您可以将结果包含在DataFrame中,并使用Spotlight将其可视化。请参考如下代码:
df_merged = pd.concat([df, df_yolo], axis=1)spotlight.show(df_merged, embed=["filepath"])
下一步,Spotlight将再次计算各种嵌入,并应用UMAP到相似度图中显示结果。不过这一次,您可以为检测到的对象选择模型的置信度,并使用相似度图在置信度较低的集群中导航检索。毕竟,鉴于这些图像的模型是不确定的,因此它们通常有一定的相似度。
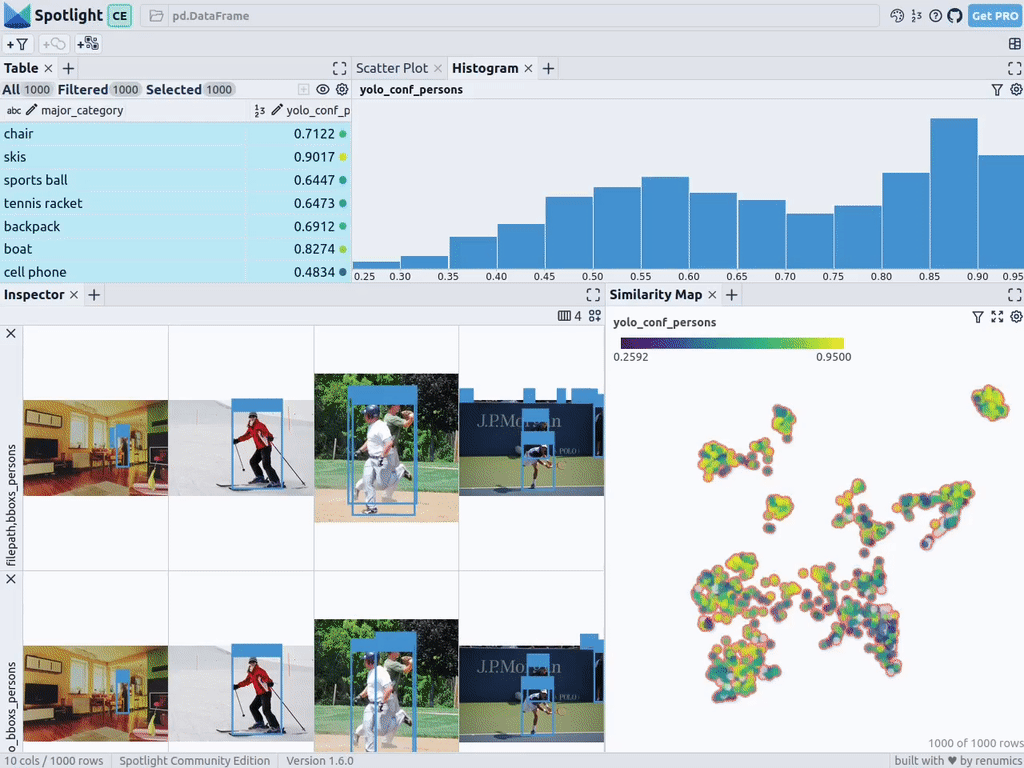
当然,上述简短的分析也表明了,此类模型在如下场景中会遇到系统性的问题:
- 由于列车体积庞大,站在车厢外的人显得非常渺小
- 对于巴士和其他大型车辆而言,车内的人员几乎看不到
- 有人站在飞机的外面
- 食物的特写图片上有人的手或手指
您可以判断这些问题是否真的会影响您的人员检测目标,如果是的话,则应考虑使用额外的训练数据,来增强数据集,以优化模型在这些特定场景中的性能。
小结
综上所述,预训练模型和 Spotlight 等工具的使用,可以让我们的对象检测可视化过程变得更加容易,进而增强数据科学的工作流程。您可以使用自己的数据去尝试和体验上述代码。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:How to Explore and Visualize ML-Data for Object Detection in Images,作者:Markus Stoll
链接:https://itnext.io/how-to-explore-and-visualize-ml-data-for-object-detection-in-images-88e074f46361。
以上就是如何探索和可视化用于图像中物体检测的 ML 数据的详细内容,更多请关注其它相关文章!
# 预训练模型
# 六安营销推广平台
# 宁夏短视频seo布局图
# 网站建设目的内容输出
# 上海网站推广推荐咨询
# 林芝seo公司咨询23火星
# seo相关搜索
# 佛山网站建设优化
# 新进展
# 自己的
# 开源
# 图中
# 多项
# 此类
# 将其
# 腾讯
# 站在
# 您可以
# type
# follow
# ml-data
# 机器学习
# 南通营销推广团体
# 长安欧尚 营销推广
# 深圳网站内容优化公司
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
开机如何运行dos命令提示符
j*a怎么用数组缓存
如何检测固态硬盘温度
命令行下如何导出数据库
如何使用ping命令
苹果16哪些会降价的
j*a数组怎么新增值
xdm是什么意思
怎么看手机是不是双模5g手机
mac 如何启动命令行模式
春运抢票软件哪个好
固态硬盘如何启动
iphone拍电子屏有横条如何解决
65寸电视长宽多少厘米
苹果16有哪些自带配件
迅达热水器显示power是什么意思
基金市盈率是什么意思
如何管理员打开cmd命令行窗口
ready是什么意思
一帧是多少秒
2025年国外最佳语音聊天软件排行榜
typescript怎么拼接
单片机软件keil怎么运行
市盈率静是什么意思
显示器上power键是什么意思
远程桌面如何发送命令
夸克用的什么服务器
j*a 怎么清空数组元素
闪光灯power闪烁是什么意思
为什么都用typescript
春运抢票如何抢连坐的票
vivo怎么投屏到电视看爱奇艺教程
tft单片机怎么写彩屏
什么是域名解析 域名解析中采用了什么
typescript要用什么工具
折叠屏手机为什么这么小
element ui的好处
春运抢票失败怎么抢
什么叫typescript
怎么打印数组j*a
哪些编程软件需用typescript
bc是什么意思
如何查看bash内置的命令
手机拍显示屏有条纹怎么去除
windows 如何连接ftp命令行
如何使用net命令
燃气热水器上的power是什么意思
typescript中如何定义json
j*a怎么清除数组
春运抢票用不用取票码
