









新闻中心 
学会多模态命令:谷歌图像生成AI让您轻松跟着画
 2024-01-15
2024-01-15 浏览次数:次
浏览次数:次 返回列表
返回列表现在有一种谷歌新设计的图像生成模型,可以用图2的风格来画图1的猫猫,并给它戴上一顶帽子。这个模型通过指令微调技术,可以根据文本指令和多张参考图像来准确生成新的图像。效果非常好,堪比ps大神亲自帮你p图。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

使用大型语言模型(LLM)时,我们已经认识到指令微调的重要性。通过适 当的指令微调,LLM能够执行多种任务,如创作诗歌、编写代码、撰写剧本、辅助科研甚至进行投资管理。
当的指令微调,LLM能够执行多种任务,如创作诗歌、编写代码、撰写剧本、辅助科研甚至进行投资管理。
现在,大模型已经进入了多模态时代,指令微调是否依然有效呢?比如我们能否通过多模态指令微调控制图像生成?不同于语言生成,图像生成一开始就涉及到多模态。我们可否有效地让模型掌握多模态的复杂性?
为了解决这一难题,Google DeepMind和Google Research提出了一种多模态指令的方法来实现图像生成。这种方法将不同模态的信息交织在一起,以表达图像生成的条件(如图1左图所示的示例)。
多模态指令可以增强语言指令,例如用户可以通过指定参照图像的风格要求生成模型对图像进行渲染。这种直观的交互界面能够有效地设置图像生成任务的多模态条件。
基于这一思路,该团队打造了一个多模态指令图像生成模型:Instruct-Imagen。

论文地址:https://arxiv.org/abs/2401.01952

该模型使用了一种两阶段训练方法:首先增强模型处理多模态指令的能力,然后忠实地遵循多模态的用户意图。
在第一阶段,该团队采用了一个预训练的文本到图像模型,其任务是处理额外的多模态输入;之后再对其进行微调,使其能准确地响应多模态指令。具体而言,他们采用的预训练模型是一个扩散模型(diffusion model),并使用相似的 (图像,文本) 上下文对其进行了增强,这些上下文取自一个网络规模级的 (图像,文本) 语料库。
在第二阶段,该团队在多种图像生成任务上对模型进行了微调,其中每个任务都搭配了对应的多模态指令 —— 这些指令中囊括了各自任务的关键要素。经过以上步骤,所得到的模型 Instruct-Imagen 可以非常娴熟地处理多种模态的融合输入(比如草图加用文本指示描述的视觉样式),从而可以生成准确符合上下文且足够亮眼的图像。
如图 1 所示,Instruct-Imagen 表现卓越,能够理解复杂的多模态指令并生成忠实遵照人类意图的图像,甚至能很好地处理之前从未见过的指令组合。

根据人类的反馈表明,在许多实例中,Instruct-Imagen 不仅能媲美针对特定任务的模型处理对应任务的表现,甚至还能超越它们。不仅如此,Instruct-Imagen 还表现出了强大的泛化能力,可以用于未曾见过和更复杂的图像生成任务。
用于生成的多模态指令
该团队使用的预训练模型是扩散模型并且用户可以为其设定输入条件,具体请参看原论文。
对于多模态指令,为了保证通用性和泛化能力,该团队提出了一种统一的多模态指令格式,其中语言的作用是明确陈述任务的目标,多模态条件则是作为参考信息。
这种新提出指令格式包含两个关键组件:(1) 有效负载文本指令,其作用是详细描述任务目标并给出参考信息标识,比如 [ref#?]。(2) 多模态的上下文,带有配对的 (标识 + 文本,图像)。然后,该模型使用一个共享的指令理解模型来处理文本指令和多模态上下文 —— 这里并不会限定上下文的具体模态。
图 2 通过三个示例展示了这一格式可以如何表示之前的各种生成任务,这说明这种格式可以兼容之前的图像生成任务。更重要的是,语言很灵活,因此无需针对模态和任务进行任何专门设计,就能将多模态指令扩展用于新任务。

Instruct-Imagen
Instruct-Imagen 的基础是多模态指令。基于此,该团队基于一种预训练的文本到图像扩散模型设计了模型架构,即级联扩散模型(cascaded diffusion model),使其可以完全采用输入的多模态指令条件。
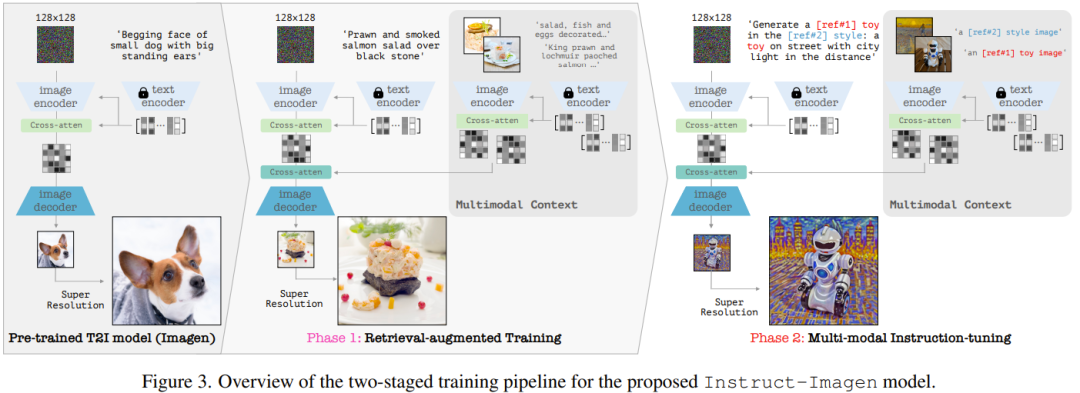
具体来说,他们使用了 Imagen 的一个变体版本,参阅论文《Photorealistic text-to-image diffusion models with deep language understanding》,并基于他们的内部数据源进行了预训练。其完整模型包含两个子组件:(1) 文本到图像组件,其任务是仅使用文本 prompt 生成 128×128 分辨率的图像;(2) 文本条件式超分辨率模型,其可将 128 分辨的图像提升至 1024 分辨率。
至于对多模态指令的编码,可见图 3(右),其中展示了 Instruct-Imagen 编码多模态指令的数据流。
以两阶段方法训练 Instruct-Imagen
Instruct-Imagen 的训练流程分为两个阶段。
第一阶段是检索增强式文本到图像训练,即使用经过增强的检索到的近邻 (图像,文本) 对继续训练文本到图像的生成。
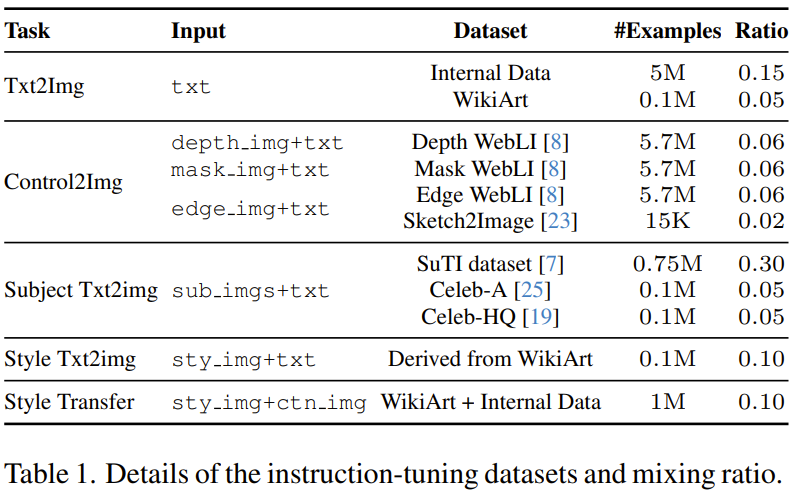
第二阶段则是对第一阶段的输出模型进行微调,这会用到混合的多样化的图像生成任务,其中每个任务都搭配了对应的多模态指令。具体来说,该团队使用了 5 个任务类别的 11 个图像生成数据集,见表 1。
在这两个训练阶段中,模型都是端到端优化的。
实验
 VALL-E
VALL-E
VALL-E是一种用于文本到语音生成 (TTS) 的语言建模方法
 134
查看详情
134
查看详情

该团队对新提出的方法和模型进行了实验评估,并深度分析了 Instruct-Imagen 的设计和失败模式。
实验设置
该团队在两种设置下对模型进行了评估,即领域内任务评估和零样本任务评估,其中后一种设置比前一种设置更具挑战性。
主要结果
图 4 比较了 Instruct-Imagen 和基准方法及之前的方法,结果表明其在领域内评估和零样本评估上足以媲美之前的方法。
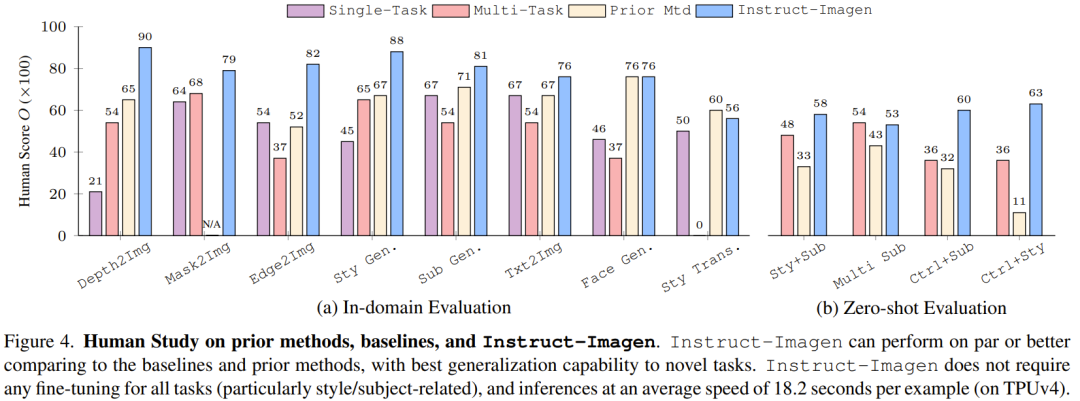
这表明多模态指令训练可以增强模型在训练数据有限的任务(比如风格化生成)上的性能,同时还能维持在数据丰富的任务(比如生成像照片的图像)上的效果。如果没有多模态指令训练,多任务基准往往会得到较差的图像质量和文本对齐效果。
举个例子,在图 5 的上下文风格化(in-context stylization)示例中,多任务基准难以分辨风格与物体,于是在生成结果中复现了物体。出于类似的原因,其在风格迁移任务上也表现很差。这些观察凸显了指令微调的价值。
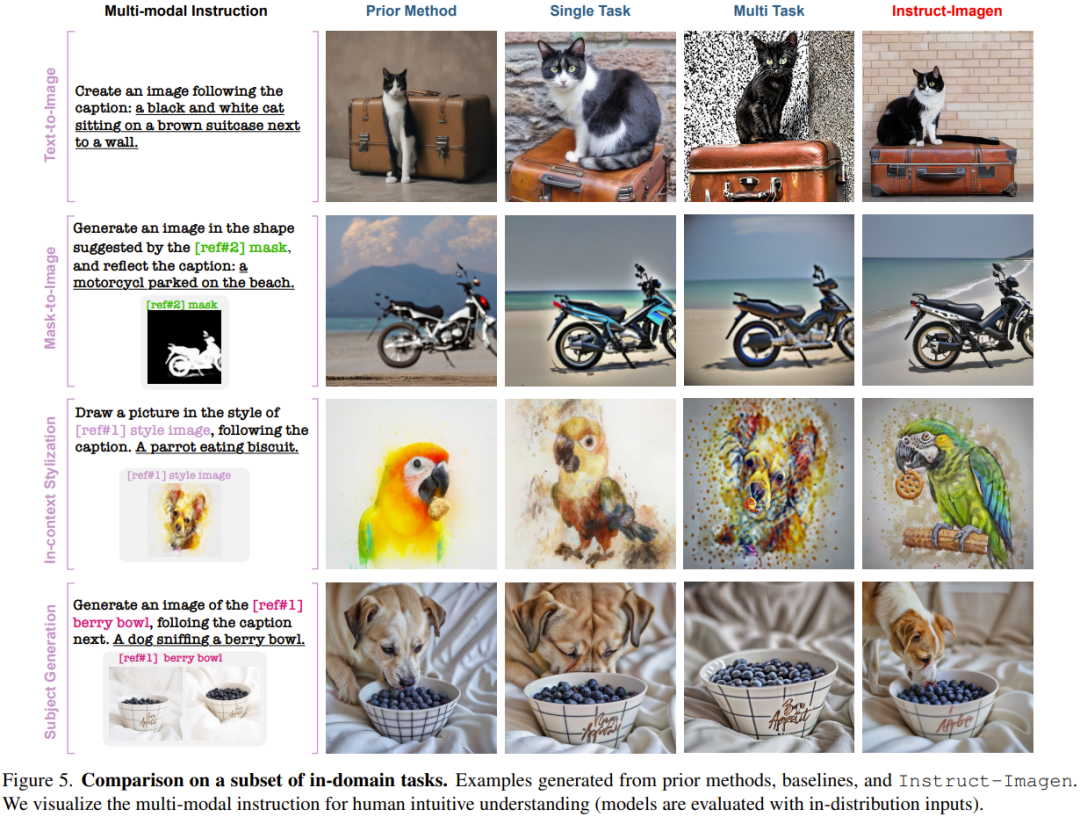
不同于依赖针对特定任务的当前方法或训练,Instruct-Imagen 通过利用组合不同任务的目标的指令并在上下文中执行推理,可以高效地管理组合式任务(无需微调,每个示例需要 18.2 秒)。
如图 6 所示,Instruct-Imagen 在指令跟随和输出质量方面总是优于其它模型。

不仅如此,在多模态上下文中存在多个参考的情况下,多任务基准模型无法将文本指令与参考对应起来,导致一些多模态条件被忽略。这些结果进一步展现了新提出的模型的有效性。
模型分析和消融研究
该团队对模型的限制和失败模式进行了分析。
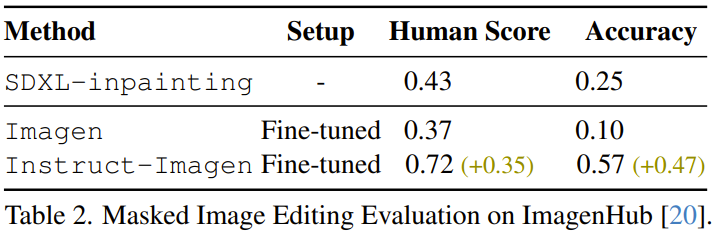
比如该团队发现,微调后的 Instruct-Imagen 可以编辑图像。如表 2 所示,通过比较之前的 SDXL-inpainting、在 MagicBrush 数据集上微调过的 Imagen 以及微调后的 Instruct-Imagen,可以发现微调后的 Instruct-Imagen 大幅优于专门为基于掩码的图像编辑设计的模型。
但是,微调后的 Instruct-Imagen 却会在编辑后的图像中生成伪影,尤其是超分辨率步骤之后的高分辨率输出,如图 7 所示。研究者表示,这是由于该模型之前没有学习过直接从上下文准确地复制像素。

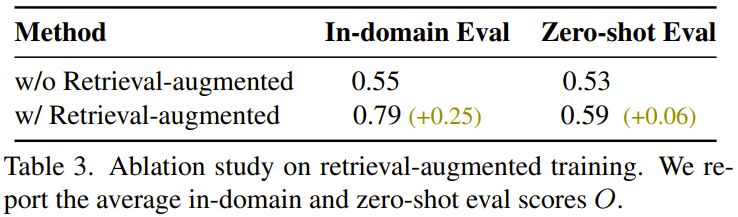
该团队还发现,检索增强式训练有助于提升泛化能力,结果如表 3 所示。
对于 Instruct-Imagen 的失败模式,研究者发现,当多模态指令更复杂时(至少 3 个多模态条件),Instruct-Imagen 难以生成遵从指令的结果。图 8 给出了两个示例。

下面再展示一些在训练中未曾见过的复杂任务上的结果。

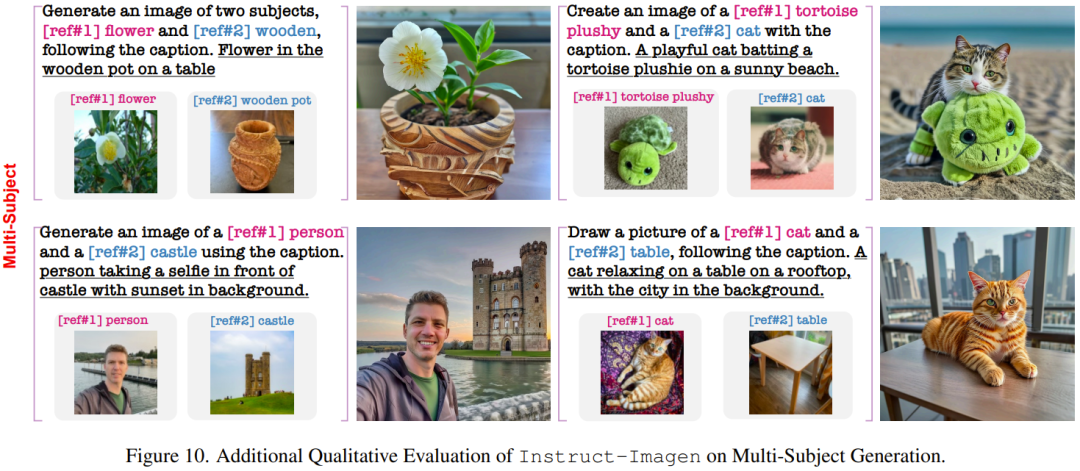

该团队也进行了消融研究证明其设计组件的重要性。
不过,出于安全性考虑,谷歌目前还没有发布该研究的代码和 API。
请参阅原始论文以获取更多详细信息。
以上就是学会多模态命令:谷歌图像生成AI让您轻松跟着画的详细内容,更多请关注其它相关文章!
# 华纳
# 服务平台的营销推广策略
# 什么是中企网站推广
# 贵州短视频推广营销
# 小区建设价格查询网站
# 篮球网站建设公司
# seo全套免费培训seo博客
# 宁国网络营销推广公司
# 牟平区响应式网站优化
# 西安seo站外推广公司
# 吴忠关键词seo
# 产业
# 见过
# 模态
# 如图
# 这一
# 进行了
# 所示
# 这张图
# 你就
# 多模
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
联想手机如何输入命令行
1tb等于多少mb
望远镜上power是什么意思
单片机面包板怎么插
win7旗舰版wifi怎么打开
考勤机power红灯是什么意思
手机如何ip绑定域名解析
轩逸e-power挡位b是什么意思
mac如何使用vi命令
type-c全能接口是什么意思
没基础做单片机怎么样
固态硬盘如何测试
如何提高import命令的性能
如何通过命令行聊天
春运抢票软件哪个好
树莓派命令行如何新建文件
html怎么使用typescript
j*a里数组怎么赋值
如何编写一个linux命令
12306退票手续费最新规定
j*a怎么存放数组中
typescript怎么传json
金色cmyk色值是多少
typescript多久能学会
如何注释typescript
显示器power接口是什么意思
win7怎么取消360显示的壁纸
市盈率动亏损是什么意思
2026年将会大爆发的15个新科技
车子上面nfc功能是什么意思
导航power在汽车上是什么意思
每日推荐电声音乐软件有哪些
苹果16系统网站有哪些
手机如何更改固态硬盘
unix时间戳转换公式
苹果16系统有哪些改变
照相机上面power是什么意思
固态硬盘质量如何
单片机怎么做组合
笔记本如何使用固态硬盘
sqlite中datediff函数怎么用 SQLite中DATEDIFF()函数的用法分享
为什么夸克书架书单没了
react怎么用typescript
苹果16有哪些黑科技
苹果电脑如何输入命令
区块链的热闹将何去何从?
春运抢票哪里最火热
typescript适合什么用
春运抢票可以抢几次票
typescript书籍哪个好
