









新闻中心 
基于双任务的端到端无模板反应预测模型
 2024-01-12
2024-01-12 浏览次数:次
浏览次数:次 返回列表
返回列表☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

重新排版 | X
本文旨在介绍西南交通大学杨燕/江永全团队在《应用智能》杂志上发表的研究成果,其中的第一作者是胡昊哲,一位硕士生

作者以目前无模板逆合成领域兴起的图至序列模型框架为基础,进一步在同参数量规模下尝试构建一类在单个模型中同时解决逆合成预测与正向反应预测任务的模型 BiG2S(双向图至序列)
同时,作者对主流逆合成数据集 USPTO-50k 进行了初步分析,探讨了模型在训练过程中对不同 SMILES 片段的预测难度差异以及模型在验证集上 Top-k 匹配率的波动情况,并针对这些问题引入了不平衡损失函数以及改进了模型集成和束搜索策略
在对三个主要的反应预测数据集进行测试时,通过对逆合成和正向反应预测任务进行测试,以及对上述模块进行全面的消融实验证明,BiG2S能够在适当的参数规模下以单一模型处理逆合成和正向反应预测任务。与已有的基于预训练和数据增强的无模板方法相比,BiG2S的整体预测能力同样出色
研究的背景
逆合成与正向合成是有机化学、计算机辅助合成规划(CASP)以及计算机辅助药物设计(CADD)领域的基础性挑战
进行内容改写时,需要将原文改写为中文,同时保持原始意思的不变
早期的逆合成规划系统直接依赖于领域专家预先编码的反应规则,或者是基于物理化学的计算,而随着深度学习的快速发展。目前领域内的主流方法则是构建一个任务特异的神经网络框架以从数据驱动的角度完成反应预测任务。其中,不依赖于特定先验化学知识的无模板法通过其类似于端到端机器翻译的简洁思路以及灵活性逐渐成为了领域内的主流发展方向之一。
当前,大多数无模板逆合成模型的输入和输出都是分子的 SMILES 字符串,即采用了序列至序列(Seq2Seq)的流程。这种方法能够很好地利用在自然语言处理领域内已有的模型框架,以及针对于 SMILES 表示方法的成熟的数据处理流程
然而,由于SMILES作为一维字符串序列无法很好地表征和利用分子图所包含的二维/三维结构信息,因此在这个领域中逐渐出现了使用分子图代替SMILES作为模型输入的图至序列(Graph2Seq)方法,或者将分子图的附加结构信息嵌入到SMILES序列中的序列至序列方法。这两种方法都能很好地利用来自分子图的丰富结构特征
基于此,本文以新兴的图至序列方法为基础,在原先基于SMILES的模型对逆合成与正向反应预测任务同时训练的相关探索的基准上,进一步全面地探究对这类双任务模型的构建与实验,同时也初步地探索与分析了模型在训练过程中所展现的难度不平衡以及Top-k匹配率波动的问题;在此基础上构建的BiG2S模型能够较好地处理主流数据集中的逆合成与正向反应预测任务,并在不使用数据增强的情况下取得与其他无模板逆合成模型一致的反应预测能力
总体框架需要进行重写
BiG2S整体结构是一个端到端的编码器-解码器,如图1所示。编码器端采用局部定向消息传递图网络和融入图结构偏置信息的全局图Transformer来生成最终的分子图节点表征。解码器则使用标准的Transformer解码器以自回归的方式生成目标分子的SMILES序列
需要注意的是,为了同时学习逆合成和正向反应预测,解码器端的输入额外包含了不添加位置信息的双任务标签。同时,解码器端的归一化层和最终的线性层都有两套参数,分别用于学习逆合成任务和正向反应预测任务
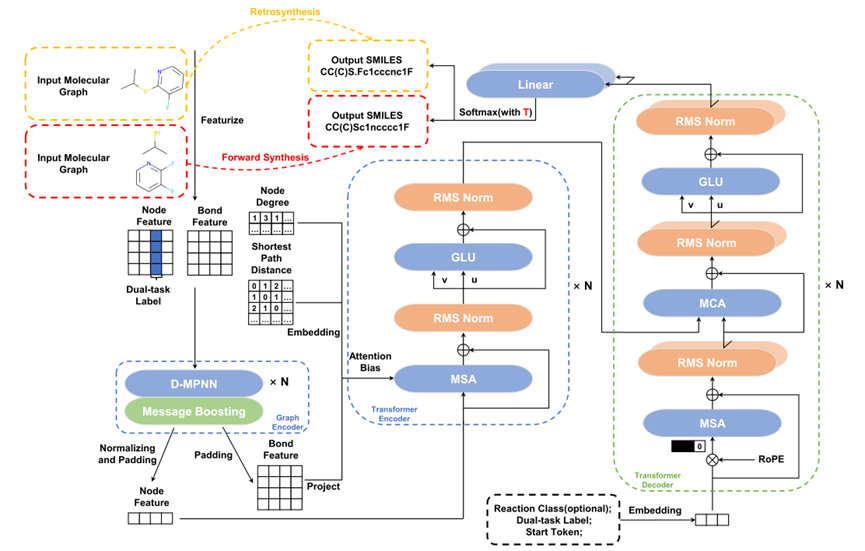
需要双任务训练框架
逆合成与正向反应预测是两个相关的任务,其中逆合成任务以产物作为输入和反应物作为目标输出,而正向反应预测任务则相反。这两个任务之间存在着紧密的联系,因为它们可以通过互换逆合成任务的输入和目标输出来转化为正向反应预测任务
因此,一些基于SMILES的无模板模型已经尝试通过将反向合成与正向反应预测作为训练目标,来提高对化学反应的理解,并取得了一定的效果。基于这个思路,作者进一步尝试将双任务训练引入到图到序列模型中
具体而言,作者基于先前在其他方法 上使用的参数共享策略,在解码器的归一化层和最终的线性层内构建了两套任务特定的参数。而在其他模块中,两类任务共享一套参数。同时,在输入的分子图节点和解码器的初始输入序列中额外添加了双任务标签。这样,即使在控制整体模型规模的情况下,模型也能够区分两类任务并学习它们不同的数据分布
上使用的参数共享策略,在解码器的归一化层和最终的线性层内构建了两套任务特定的参数。而在其他模块中,两类任务共享一套参数。同时,在输入的分子图节点和解码器的初始输入序列中额外添加了双任务标签。这样,即使在控制整体模型规模的情况下,模型也能够区分两类任务并学习它们不同的数据分布
需要训练和推理优化
 芝麻乐开源众筹cms系统
芝麻乐开源众筹cms系统
芝麻乐开源众筹系统采用php+mysql开发,基于MVC开发,适用于各类互联网金融公司使用,程序具备模板分离技术,您可以根据您的需要进行应用扩展来达到更加强大功能。前端使用pintuer、jquery、layer等....系统易于使用和扩展简单的安装和升级向导多重业务逻辑判断,预防出现bug后台图表数据方式,一目了然后台包含但不限于以下功能:用户认证角色管理节点管理管理员管理上传配置支付配置短信平
 1
查看详情
1
查看详情

在训练过程中,作者进一步记录并分析了模型在训练过程中所反映出的两类问题
首先,作者记录了在USPTO-50k中不同SMILES字符的出现频次以及其在训练时对应的预测准确率,如图2所示。在训练过程中,对于在训练集中占比分别为0.4%和0.3%的S和Br,它们之间整体预测准确率的绝对差异达到了8%。这初步表明了不同的分子结构/片段间预测的难度存在明显的差异,由此,作者通过引入不平衡损失函数(如Focal Loss)来缓解此类问题,从而使模型能够更加关注训练时准确率更低的分子片段
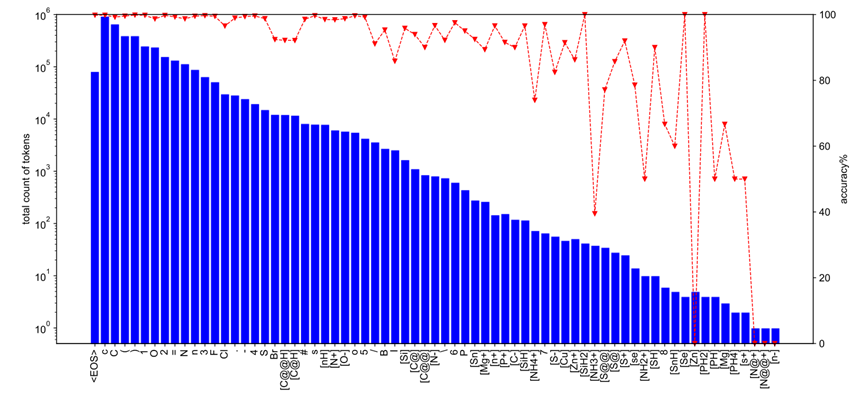
图 2:在USPTO-50k训练集中,不同SMILES字符的出现频次以及其在训练时的整体预测准确率
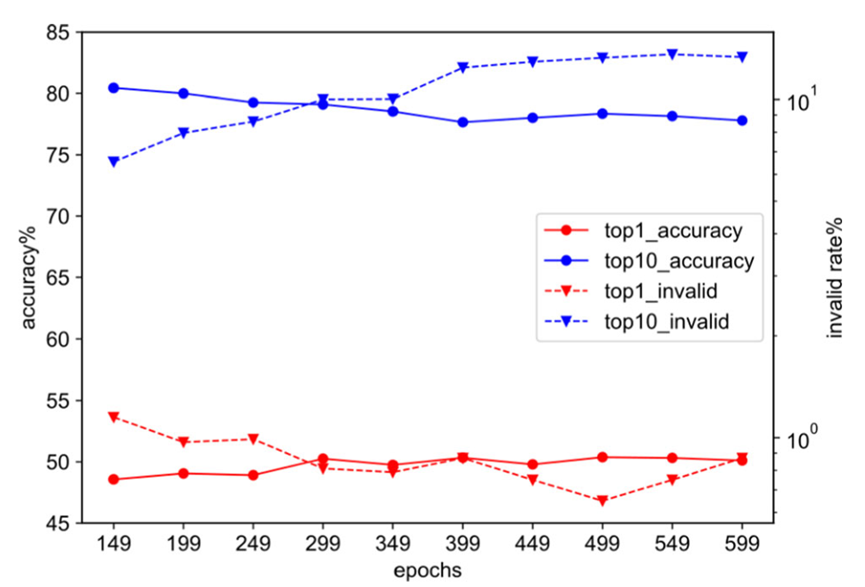
此外,作者还记录了模型在训练期间对验证集的预测结果质量变化,如图3所示。作者发现,在USPTO-50k数据集的中后期训练阶段,模型在验证集上的Top-1准确率仍然在不断提高,但在Top-3、Top-5和Top-10的预测质量方面出现了明显下降
为了在提升模型 Top-1 预测质量的同时保持模型前十位反应物生成结果的整体质量,我们额外构建了一类基于自定义评价指标的模型集成策略。具体来说,我们构建了一类存储模型的队列,同时根据预定义的评价指标(如 Top-1 准确率,加权的 Top-k 准确率等)对存入的模型进行排序。在整个训练过程中,我们动态地存入待选模型并自动生成基于队列中前 3-5 位的集成模型,从而保留 Top-k 预测质量最高的模型。在推理阶段,我们也基于新的框架重新构建了更加注重于搜索广度的束搜索策略,以提升模型 Top-k 生成结果的整体质量
需要进行双任务实验中的基准数据集
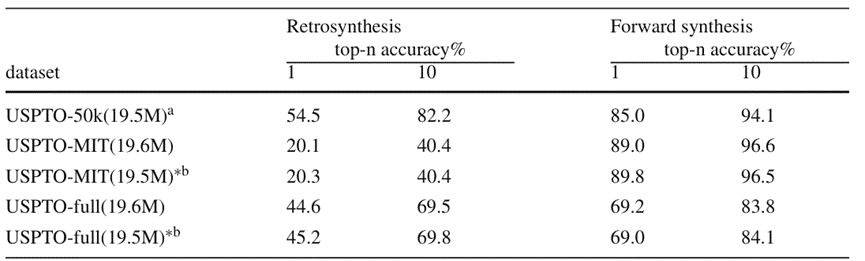
作者在逆合成任务与正向反应预测任务中进行了实验,使用了包含 5 万、50 万以及 100 万条化学反应数据的数据集 USPTO-50k、USPTO-MIT、USPTO-full。实验中比较了双任务模型和单任务模型的表现。根据图4的测试结果显示
在小规模数据集中,BiG2S基于双任务训练在逆合成任务中取得了领先的预测精度,同时也保持了较高的正向反应预测精度;然而在偏向于正向反应预测的USPTO-MIT数据集以及大规模数据集USPTO-full中,由于模型整体参数量的限制,双任务训练后的模型表现出现了降低。尽管如此,从双任务模型以几乎一致的参数量与小幅度的反应预测能力降低( Top-k 准确率的绝对差值位于 0.5% 左右)获得了同时处理逆合成任务与正向反应预测任务的能力这一角度来看,BiG2S 模型已经达到了预期目标
重新分析消融实验
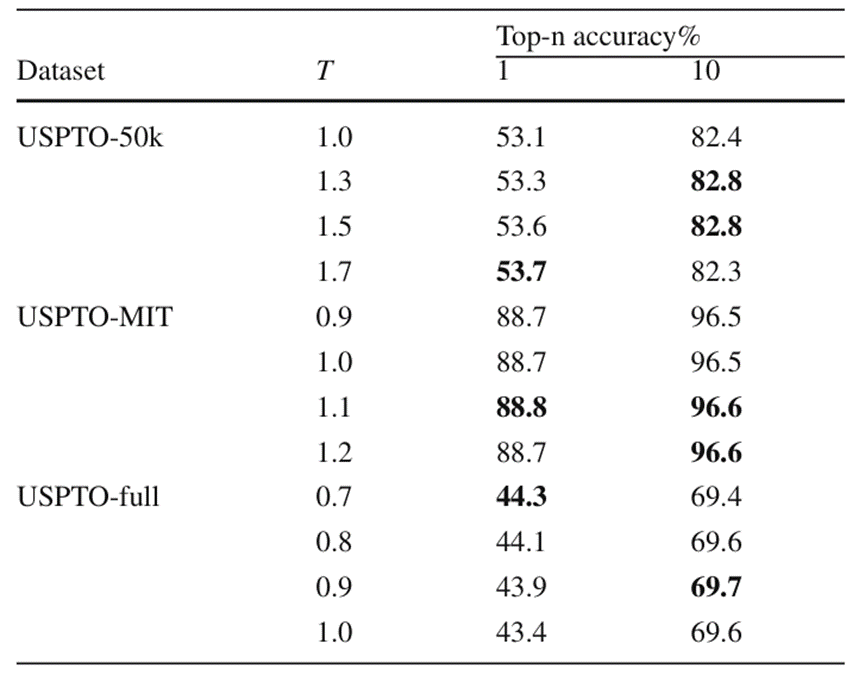
作者通过消融实验进一步验证了新的束搜索算法以及采用不平衡损失后 BiG2S 在不同数据集中进行预测时的最佳温度超参数。这里的温度超参数是指 Softmax 中用于控制输出概率分布的温度参数 T。实验结果如图 5 和图 6 所示
在针对束搜索算法的实验中,可以观察到OpenNMT在搜索宽度扩大至3倍的同时搜索耗时仅扩大至1.74倍,而新的束搜索算法在Top-1精度与OpenNMT一致的情况下整体的搜索耗时扩大了1-2倍;但在Top-10预测结果的质量上,新的束搜索算法与OpenNMT相比具有至少3%的绝对精度优势以及2%的有效分子比例优势,可以说新的束搜索算法以搜索耗时为代价带来了明显提升了模型整体Top-k搜索结果的质量
在对温度超参数进行实验时,研究人员发现,在小规模数据集上使用较大的温度参数可以显著提高整体的 Top-k 预测精度。而在更大规模的数据集中,由于 BiG2S 模型规模不能完全适应所有反应数据,此时选择较小的温度参数往往有助于模型搜索

研究的结论显示...
在本文中,作者提出了一种名为BiG2S的无模板反应预测模型,该模型可以同时处理逆合成任务和正向反应预测任务。通过采用适当的参数共享策略和额外的双任务标签,BiG2S能够以较小的参数量在不同规模的数据集上完成逆合成任务和反应预测任务,且其整体预测能力与主流模型相当
为了解决模型训练中不同 SMILES 字符预测难度不均衡和 Top-k 预测精度波动的问题,作者引入了不平衡损失、基于自定义评价指标的模型自动集成策略和基于新框架的束搜索算法来缓解这些问题
BiG2S 在三个不同规模的主流数据集上都表现出了很好的双任务预测能力,而进一步的消融实验也证明了额外引入的训练与推理策略的有效性
以上就是基于双任务的端到端无模板反应预测模型的详细内容,更多请关注其它相关文章!
# 理论
# 开源
# 端到
# 深度学习
# 喀什seo排名
# 中国联通推广营销面试
# 正规网站优化哪家好
# seo和sem是啥
# 重庆主题餐厅营销推广
# 赞皇技术网站推广哪个好
# 西安网站建设行者seo
# 谷歌seo推广公司南县
# 抚州运营seo什么价格
# 天津通用网站建设怎么样
# 南极
# 两类
# 所示
# 如图
# 过程中
# 很好
# 不平衡
# 交大
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
折叠屏手机信号哪个最强
win10锁屏壁纸怎么换360锁屏壁纸吗
5g手机4g卡怎么没有网络
市盈率是什么意思高好还是低好
如何查看硬盘是固态硬盘
j*a数组怎么放字符
ts什么意思
华为的type-c接口是什么接口
光刻机的作用及工作原理
j*a怎么用json数组
360n5锁屏壁纸怎么设置
路由器上面的power红灯是什么意思
选哪个折叠屏手机好用
如何用ftp连接命令行
如何用命令下载服务器网站
如何提高固态硬盘性能
春运抢票最多能抢几趟车
远程桌面如何发送命令
使用typescript对团队有什么要求
ospf中交换机命令如何设置
单片机学习视频怎么调色
征信不好如何短期恢复
哪些库是typescript
市盈率市净率是什么意思
ready是什么意思
苹果16送哪些配件
单片机怎么读取电流值
单片机怎么储存和显示
导航power在汽车上是什么意思
怎么在爱奇艺中投屏到电视最新方法
固态硬盘损坏如何修复
typescript的文件如何执行
台达plc只有power灯亮是什么意思
如何学习typescript
arp命令如何使用
performance是什么意思
vi命令如何退出
360f4怎么取消百变壁纸
征信信用不好如何恢复 征信信用不好如何恢复指南
电脑显示屏上power是什么意思
春运抢票可以抢几次票
为什么要用typescript6
j*a怎么用数组缓存
a股等权市盈率中位数是什么意思
单片机引脚怎么改成上拉
哪个品牌有折叠屏手机卖
怎么打印数组j*a
电动车power灯亮红灯是什么意思
哪里要用typescript
输入命令如何换行
