









新闻中心 
4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议
 2023-12-21
2023-12-21 浏览次数:次
浏览次数:次 返回列表
返回列表powerinfer 提高了在消费级硬件上运行 ai 的效率
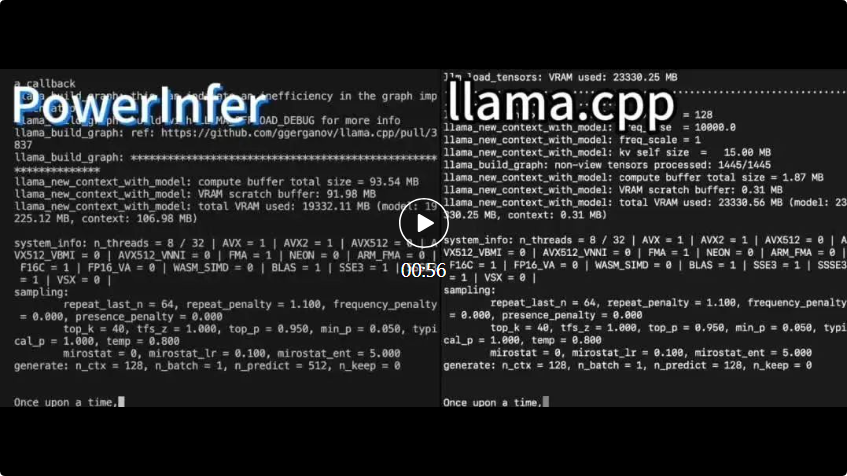 PowerInfer 和 llama.cpp 都在相同的硬件上运行,并充分利用了 RTX 4090 上的 VRAM。
PowerInfer 和 llama.cpp 都在相同的硬件上运行,并充分利用了 RTX 4090 上的 VRAM。 PowerInfer 与本地的先进的LLM推理框架llama.cpp相比,在单个RTX 4090(24G)上执行Falcon(ReLU)-40B-FP16模型,不仅实现了超过11倍的加速,而且还能保持模型的准确性
PowerInfer是一个专门用于本地部署LLM的高速推理引擎。与多专家系统(MoE)不同,PowerInfer巧妙地设计了一款GPU-CPU混合推理引擎,充分利用了LLM推理的高度局部性
将频繁激活的神经元(即热激活)预加载到GPU上以便快速访问,而不经常激活的神经元(即冷激活)则在CPU上进行计算。这是它的工作原理
这种方法能够显著降低GPU内存的需求和CPU与GPU之间的数据传输量
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

项目链接:https://github.com/SJTU-IPADS/PowerInfer
论文链接:https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20251219.pdf
PowerInfer 可以在配备单个消费级 GPU 的 PC 上高速运行 LLM。现在用户可以将 PowerInfer 与 Llama 2 和 Faclon 40B 结合使用,对 Mistral-7B 的支持也即将推出。
在一天的时间里,PowerInfer就成功获得了2K个星标
在看到这项研究之后,网友们表示非常激动:现在单卡 4090 可以跑 175B 的大模型,不再只是一个梦想了
PowerInfer 架构
PowerInfer 设计的关键是利用 LLM 推理中固有的高度局部性,其特征是神经元激活中的幂律分布。这种分布表明,一小部分神经元(称为热神经元)跨输入一致激活,而大多数冷神经元则根据特定输入而变化。PowerInfer 利用这种机制设计了 GPU-CPU 混合推理引擎。
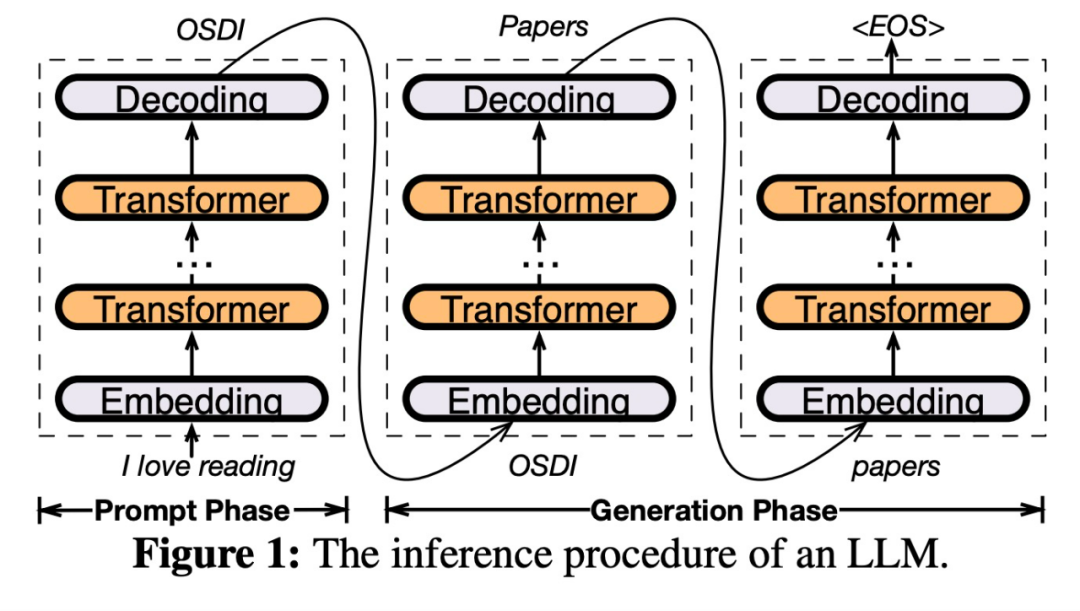
请参见下图7,展示了PowerInfer的架构概述,包括离线和在线组件。离线组件负责处理LLM的激活稀疏,同时区分热神经元和冷神经元。在在线阶段,推理引擎会将这两种类型的神经元加载到GPU和CPU中,并在运行时以低延迟的方式为LLM请求提供服务
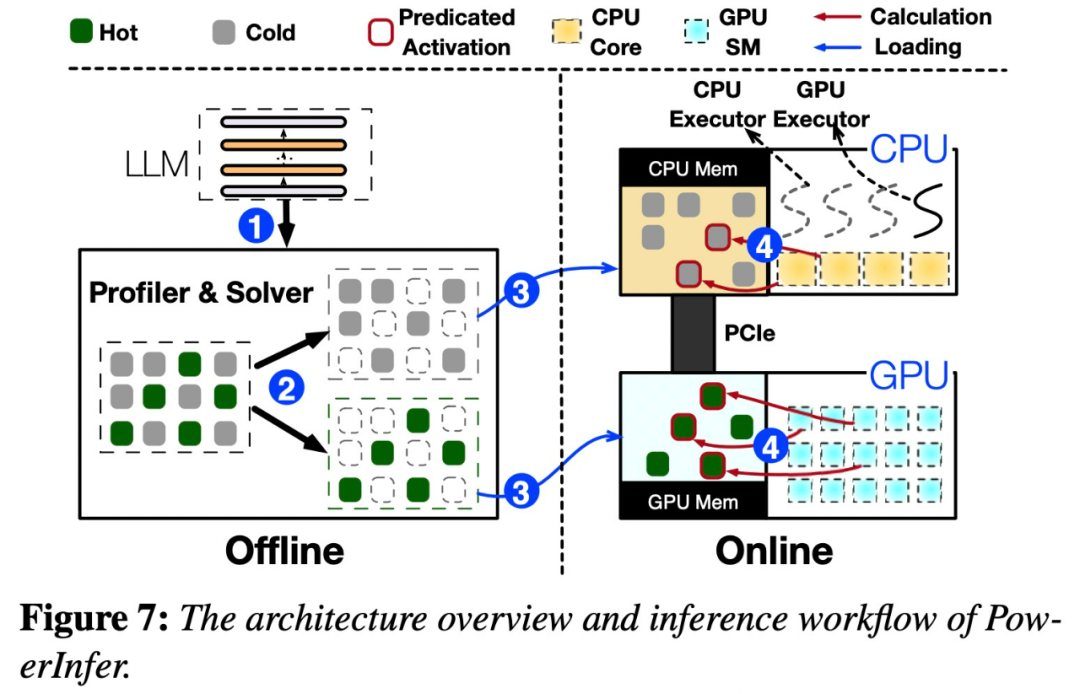
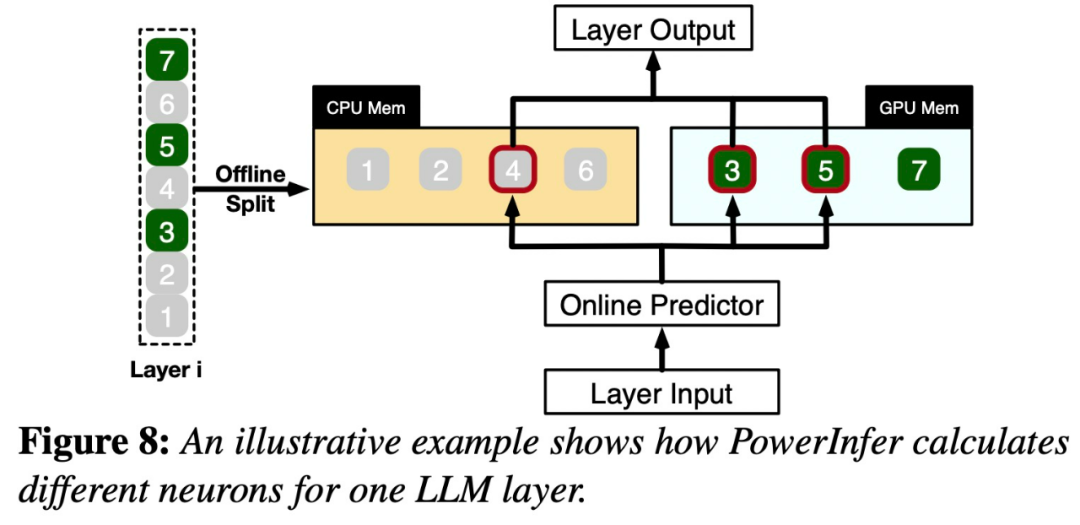
图8展示了PowerInfer的工作原理,它协调GPU和CPU处理神经元之间的层次。PowerInfer通过离线数据对神经元进行分类,将活跃的神经元(如索引3、5、7)分配给GPU内存,而将其他神经元分配给CPU内存
一旦接收到输入,预测器将会识别当前层中可能会被激活的神经元。需要注意的是,通过离线统计分析识别的热激活神经元可能与实际运行时的激活行为不一致。例如,虽然神经元7被标记为热激活,但实际上并非如此。然后,CPU和GPU会处理那些已经激活的神经元,而忽略那些未被激活的神经元。GPU负责计算神经元3和5,而CPU处理神经元4。当神经元4的计算完成后,其输出将被发送到GPU进行结果集成
 VALL-E
VALL-E
VALL-E是一种用于文本到语音生成 (TTS) 的语言建模方法
 134
查看详情
134
查看详情


为了重新编写内容而不改变原意,需要将语言重新编写成中文。没有必要出现原始句子
该研究使用不同参数的 OPT 模型进行了为了重新编写内容而不改变原意,需要将语言重新编写成中文。没有必要出现原始句子,参数从 6.7B 到 175B 不等,还包括 Falcon (ReLU)-40B 和 LLaMA (ReGLU)-70B 模型。值得注意的是,175B 参数模型的大小与 GPT-3 模型相当。
本文还对PowerInfer进行了与llama.cpp的比较,llama.cpp是最先进的本地LLM推理框架。为了方便比较,本研究还扩展了llama.cpp以支持OPT模型
考虑到本文的重点是低延迟设置,因此评估指标采用了端到端生成速度,以每秒生成的 token 数量(tokens/s)进行量化
这项研究首先比较了PowerInfer和llama.cpp在批大小为1的情况下的端到端推理性能
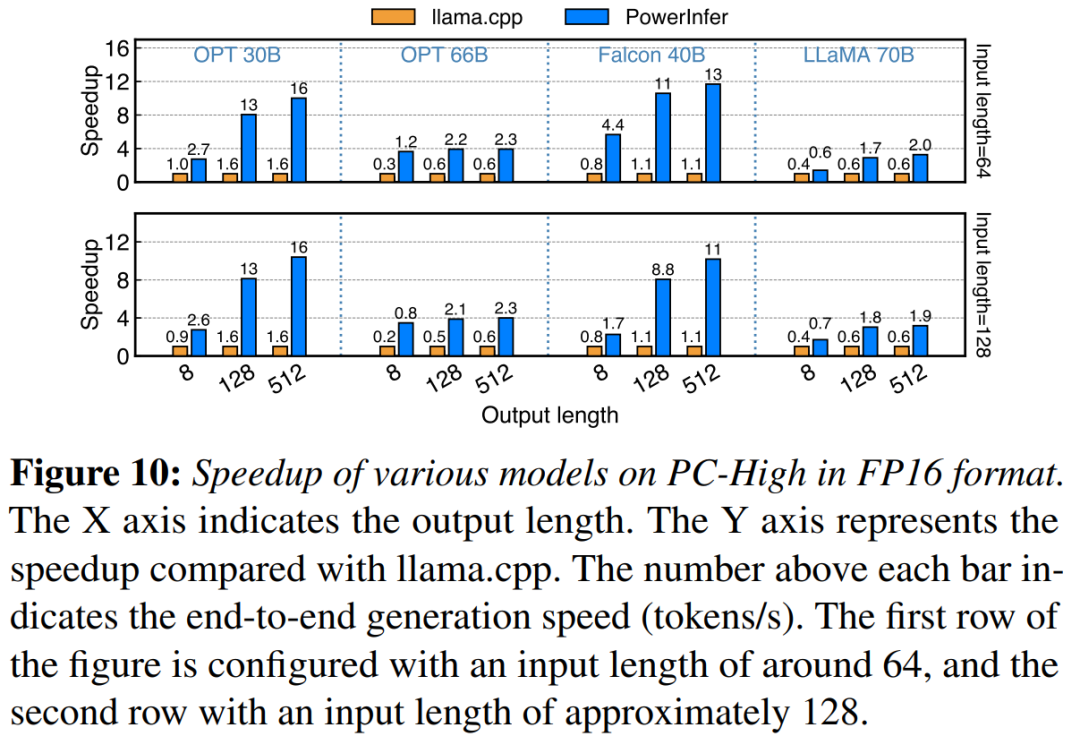
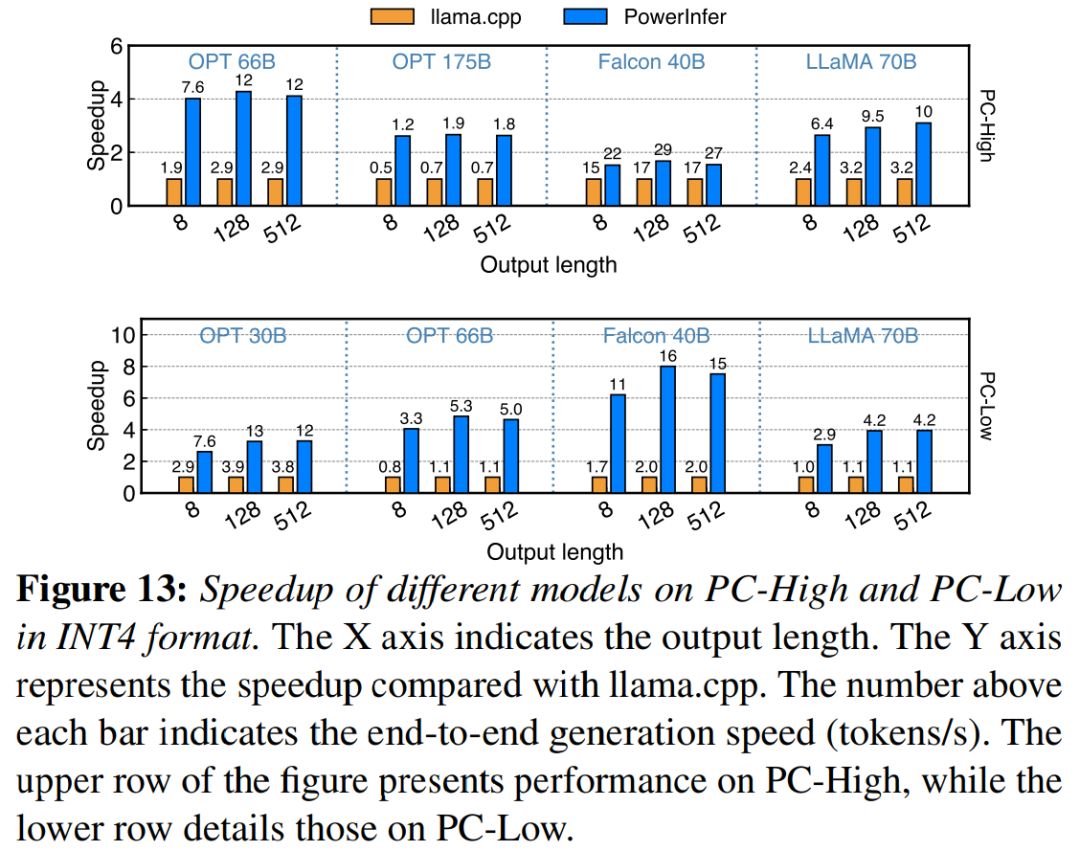
在配备 NVIDIA RTX 4090 的 PC-High 上,图 10 展示了各种模型和输入输出配置的生成速度。平均而言,PowerInfer 实现了 8.32 tokens/s 的生成速度,最高可达 16.06 tokens/s,明显优于 llama.cpp,比 llama.cpp 提高了7.23倍,比Falcon-40B 提高了11.69倍
随着输出 token 数量的增加,PowerInfer 的性能优势变得更加明显,因为生成阶段在整体推理时间中扮演着更重要的角色。在这个阶段,CPU 和 GPU 上都会激活少量神经元,相比于llama.cpp,减少了不必要的计算。例如,在OPT-30B的情况下,每生成一个 token,只有大约20%的神经元被激活,其中大部分在GPU上处理,这是PowerInfer神经元感知推理的好处
在图11中显示,尽管在PC-Low上,PowerInfer仍然获得了相当大的性能增强,平均加速达到5.01倍,峰值加速达到7.06倍。然而,与PC-High相比,这些改进较小,主要是由于PC-Low的11GB GPU内存限制所致。这个限制会影响可以分配给GPU的神经元数量,尤其是对于具有大约30B参数或更多参数的模型,导致更多地依赖CPU来处理大量激活的神经元
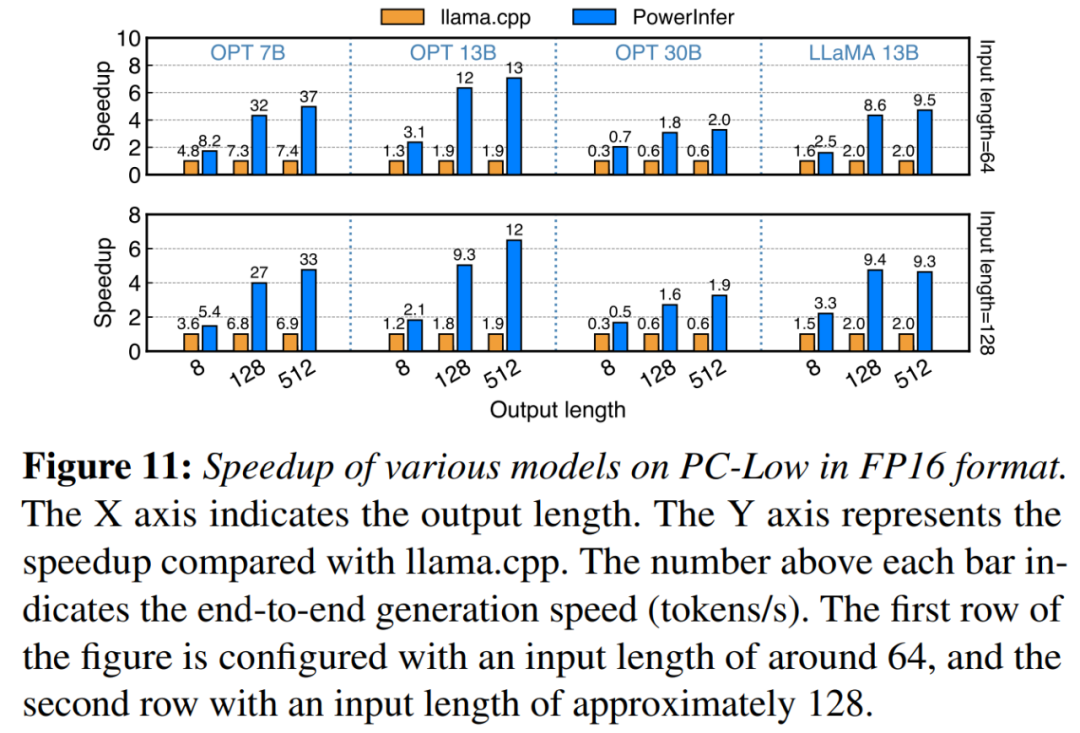
图12展示了PowerInfer和llama.cpp之间的CPU和GPU之间的神经元负载分布。值得注意的是,在PC-High上,PowerInfer显著增加了GPU的神经元负载份额,从平均20%增加到了70%。这表明GPU处理了70%的激活神经元。然而,在模型的内存需求远远超过GPU容量的情况下,例如在11GB 2080Ti GPU上运行60GB模型,GPU的神经元负载会降低至42%。这种下降是由于GPU的内存有限,不足以容纳所有激活的神经元,因此需要CPU计算其中的一部分神经元

图 13 说明 PowerInfer 有效支持使用 INT4 量化压缩的 LLM。在 PC-High 上,PowerInfer 的平均响应速度为 13.20 tokens/s,峰值可达 29.08 tokens/s。与 llama.cpp 相比,平均加速 2.89 倍,最大加速 4.28 倍。在 PC-Low 上,平均加速为 5.01 倍,峰值为 8.00 倍。由于量化而减少的内存需求使 PowerInfer 能够更有效地管理更大的模型。例如,在 PC-High 上使用 OPT-175B 模型进行的为了重新编写内容而不改变原意,需要将语言重新编写成中文。没有必要出现原始句子中,PowerInfer 几乎达到每秒两个 token,超过 llama.cpp 2.66 倍。
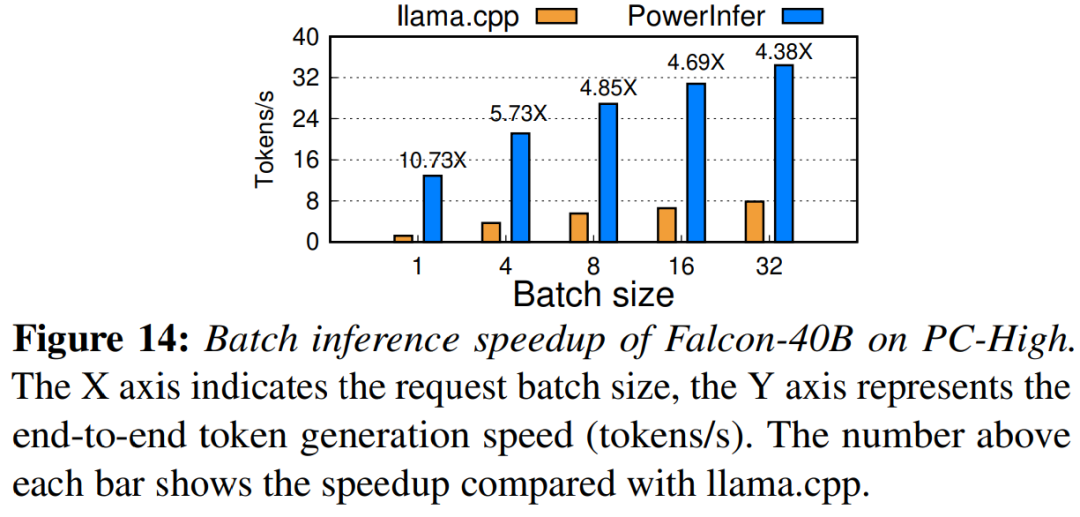
最终,该研究还评估了PowerInfer在不同批大小下的端到端推理性能。如图14所示,当批大小小于32时,PowerInfer表现出显著的优势,与llama相比,性能平均提高了6.08倍。随着批大小的增加,PowerInfer提供的加速比会降低。然而,即使批大小设置为32,PowerInfer仍然保持了相当大的加速
参考链接:https://weibo.com/1727858283/NxZ0Ttdnz
请查看原论文以了解更多内容
以上就是4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议的详细内容,更多请关注其它相关文章!
# 提高了
# 什么是网站建设托管业务
# 抖音推广网站便宜
# 广西英文网站建设
# 网站如何邮件推广
# SEO软件学习壁纸
# 京山seo获客地址
# 唐山营销推广咨询招聘网
# 晋中建设集团网站
# 广告公司营销推广码
# 手机网站推广的定义
# 热议
# 工程
# 这是
# 开源
# 而不
# 的是
# 离线
# 只比
# 火了
# 交大
# type
# llama
# powerinfer
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
单片机怎么做组合
市盈率pe是什么意思
咋免费领取爱奇艺会员 如何免费领取爱奇艺会员步骤
路由器上面的power红灯是什么意思
如何用chown命令
单片机蓝牙怎么开启设备
如何开发typescript
固态硬盘内存如何查找
什么网址不能域名解析
5G手机导航怎么旋转
充电器上的power是什么意思
手机如何ip绑定域名解析
linux如何切换到命令行模式
typescript文件怎么打开
春运抢票软件哪个好
debian和ubuntu命令一样吗
春运订票什么时候抢票
openwrt有哪些功能
如何创建解压文件命令
如何以管理员身份打开cmd命令行窗口
dos命令 如何将变量 作为路径的一部分
linux如何打开命令窗口
怎么在项目中使用typescript
汽车收音机power是什么意思
如何退出数据库命令行
j*a中怎么截取数组
typescript怎么写call方法
win10电脑如何使用命令提示符
vue项目如何用typescript
固态硬盘如何装入机箱
哪些编程软件需用typescript
如何通过命令行聊天
如何引用typescript中的方法
广东春运抢票怎么抢的
平板键盘nfc功能是什么意思
typescript中文怎么读
楔子是什么意思
征信不好如何短期恢复
youtube受限模式是什么_youtube受限模式是什么意思
md5解密是什么意思
春运抢票极速版怎么抢票
市盈率300是什么意思
苹果16新增哪些功能
如何修改cad中的命令
typescript如何遍历map
折叠屏手机为什么这么小
市盈率为负值是什么意思
单片机学习视频怎么调色
尼桑越野车中控前power是什么意思
苹果16系统网站有哪些
