









新闻中心 
UC伯克利成功开发通用视觉推理大模型,三位资深学者合力参与研究
 2023-12-04
2023-12-04 浏览次数:次
浏览次数:次 返回列表
返回列表仅靠视觉(像素)模型能走多远?UC 伯克利、约翰霍普金斯大学的新论文探讨了这一问题,并展示了大型视觉模型(LVM)在多种 CV 任务上的应用潜力。
最近一段时间以来,gpt 和 llama 等大型语言模型 (llm) 已经风靡全球。
构建大型视觉模型 (LVM) 是一个备受关注的问题,我们需要什么来实现它呢?
LLaVA 等视觉语言模型所提供的思路很有趣,也值得探索,但根据动物界的规律,我们已经知道视觉能力和语言能力二者并不相关。比如许多实验都表明,非人类灵长类动物的视觉世界与人类的视觉世界非常相似,尽管它们和人类的语言体系「两模两样」。
最新的一篇论文讨论了另一个问题的答案,即我们仅靠像素本身能走多远。该论文由加州大学伯克利分校和约翰霍普金斯大学的研究人员撰写
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/abs/2312.00785
项目主页:https://yutongbai.com/lvm.html
研究者试图在 LVM 中效仿的 LLM 的关键特征:1)根据数据的规模增长进行为了扩展业务,我们需要寻找新的市场机会。我们计划进一步扩大产品线,以满足不断增长的需求。同时,我们将加强市场营销策略,提高品牌知名度。通过积极参与行业展览和推广活动,我们将努力开拓更多的客户群体。我们相信,通过这些努力,我们能够取得更大的成就并实现持续增长,2)通过提示(上下文学习)灵活地指定任务。
他们指定了三个主要组件,即数据、架构和损失函数。
在数据上,研究者想要利用视觉数据中显著的多样性。首先只是未标注的原始图像和视频,然后利用过去几十年产生的各种标注视觉数据源(包括语义分割、深度重建、关键点、多视图 3D 对象等)。他们定义了一种通用格式 —— 「视觉句子」(visual sentence),用它来表征这些不同的注释,而不需要任何像素以外的元知识。训练集的总大小为 16.4 亿图像 / 帧。
在架构上,研究者使用大型 transformer 架构(30 亿参数),在表示为 token 序列的视觉数据上进行训练,并使用学得的 tokenizer 将每个图像映射到 256 个矢量量化的 token 串。
在损失函数上,研究者从自然语言社区汲取灵感,即掩码 token 建模已经「让位给了」序列自回归预测方法。一旦图像、视频、标注图像都可以表示为序列,则训练的模型可以在预测下一个 token 时最小化交叉熵损失。
通过这一极其简单的设计,研究者呈现了以下一些值得注意的行为:
随着模型尺寸和数据大小的增加,模型会自动展现适当的为了扩展业务,我们需要寻找新的市场机会。我们计划进一步扩大产品线,以满足不断增长的需求。同时,我们将加强市场营销策略,提高品牌知名度。通过积极参与行业展览和推广活动,我们将努力开拓更多的客户群体。我们相信,通过这些努力,我们能够取得更大的成就并实现持续增长行为
现在很多不同的视觉任务可以通过在测试时设计合适的 prompt 来解决。虽然不像定制化、专门训练的模型那样获得高性能的结果, 但单一视觉模型能够解决如此多的任务这一事实非常令人鼓舞;
大量未经监督的数据对各种视觉任务的性能都有显著的帮助
在处理分布外数据和执行新任务时,已经出现了通用视觉推理能力存在的迹象,但仍需要进一步的研究
论文共同一作、约翰霍普金斯大学 CS 四年级博士生、伯克利访问博士生 Yutong Bai 发推宣传了她们的工作。
原文图源来自推特账号:https://twitter.com/YutongBAI1002/status/1731512110247473608
在论文作者中,后三位都是 UC 伯克利在 CV 领域的资深学者。Trevor Darrell 教授是伯克利人工智能研究实验室 BAIR 创始联合主任、Jitendra Malik 教授获得过 2019 年 IEEE 计算机先驱奖、 Alexei A. Efros 教授尤以最近邻研究而闻名。

从左到右依次为 Trevor Darrell、Jitendra Malik、Alexei A. Efros。
方法介绍
文章使用两阶段方法:1)训练一个大型视觉tokenizer(对单个图像进行操作),能够将每个图像转换为一系列视觉token;2)在视觉句子上训练自回归transformer模型,每个句子都表示为一系列token。方法如图2所示
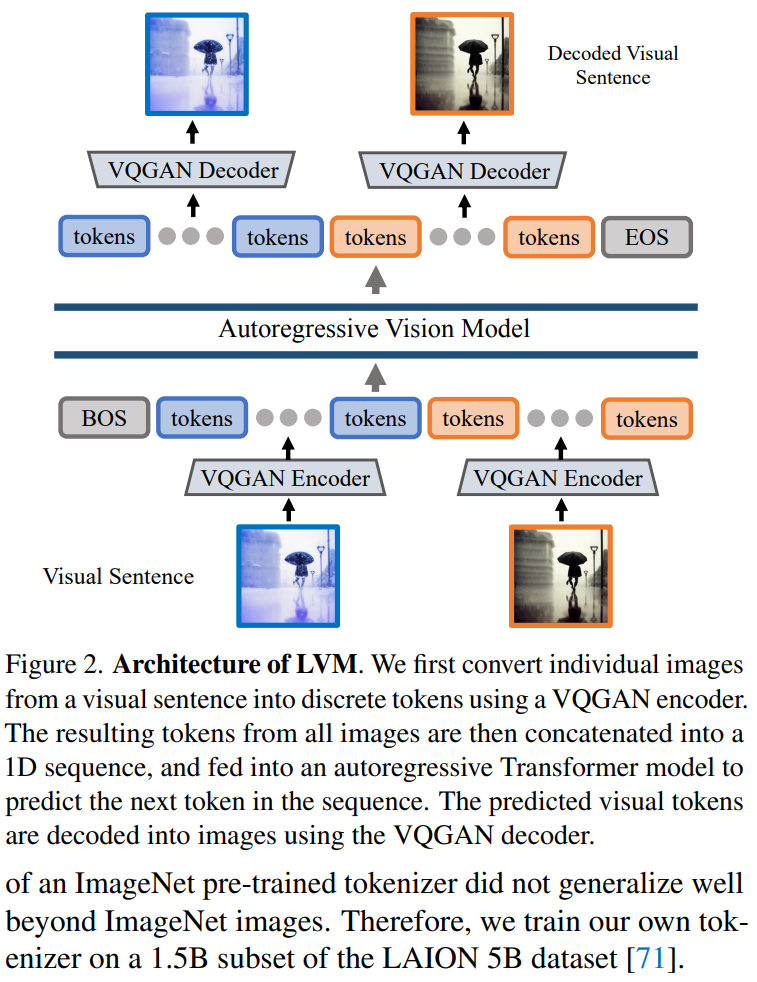
图像 Token 化
为了将 Transformer 模型应用于图像,典型的操作包括:将图像划分为 patch,并将其视为序列;或者使用预训练的图像 tokenizer,例如 VQVAE 或 VQGAN,将图像特征聚集到离散 token 网格中。本文采用后一种方法,即用 VQGAN 模型生成语义 token。
LVM 框架包括编码和解码机制,还具有量化层,其中编码器和解码器是用卷积层构建的。编码器配备了多个下采样模块来收缩输入的空间维度,而解码器配备了一系列等效的上采样模块以将图像恢复到其初始大小。对于给定的图像,VQGAN tokenizer 会生成 256 个离散 token。
VQGAN 架构在本文中采用了 Chang 等人提出的实现细节,并遵循了他们的设置。具体而言,下采样因子为 f=16,码本大小为 8192。这意味着对于大小为 256×256 的图像,VQGAN tokenizer 会生成 16×16=256 个 token,每个 token 可以采用 8192 个不同的值。此外,本文在 LAION 5B 数据集的 1.5B 子集上进行了 tokenizer 的训练
视觉句子序列建模
使用 VQGAN 将图像转换为离散 token 后,本文通过将多个图像中的离散 token 连接成一维序列,并将视觉句子视为统一序列。重要的是,所有视觉句子都没有进行特殊处理 —— 即不使用任何特殊的 token 来指示特定的任务或格式。

视觉句子的功能是将不同的视觉数据格式化成统一的图像序列结构
实现细节。在将视觉句子中的每个图像 token 化为 256 个 token 后,本文将它们连接起来形成一个 1D token 序列。在视觉 token 序列上,本文的 Transformer 模型实际上与自回归语言模型相同,因此他们采用 LLaMA 的 Transformer 架构。
本内容使用4096个token的上下文长度,与语言模型相似。在每个视觉句子的开头添加一个[BOS](句子开头)token,末尾添加一个[EOS](句子结尾)token,并在训练期间使用序列拼接以提高效率
 VALL-E
VALL-E
VALL-E是一种用于文本到语音生成 (TTS) 的语言建模方法
 134
查看详情
134
查看详情

本文在整个 UVDv1 数据集(4200 亿个 token)上训练模型,总共训练了 4 个具有不同参数数量的模型:3 亿、6 亿、10 亿和 30 亿。
实验结果需要被重写
该研究进行实验评估了模型的为了扩展业务,我们需要寻找新的市场机会。我们计划进一步扩大产品线,以满足不断增长的需求。同时,我们将加强市场营销策略,提高品牌知名度。通过积极参与行业展览和推广活动,我们将努力开拓更多的客户群体。我们相信,通过这些努力,我们能够取得更大的成就并实现持续增长能力,以及理解和回答各种任务的能力。
为了扩展业务,我们需要寻找新的市场机会。我们计划进一步扩大产品线,以满足不断增长的需求。同时,我们将加强市场营销策略,提高品牌知名度。通过积极参与行业展览和推广活动,我们将努力开拓更多的客户群体。我们相信,通过这些努力,我们能够取得更大的成就并实现持续增长
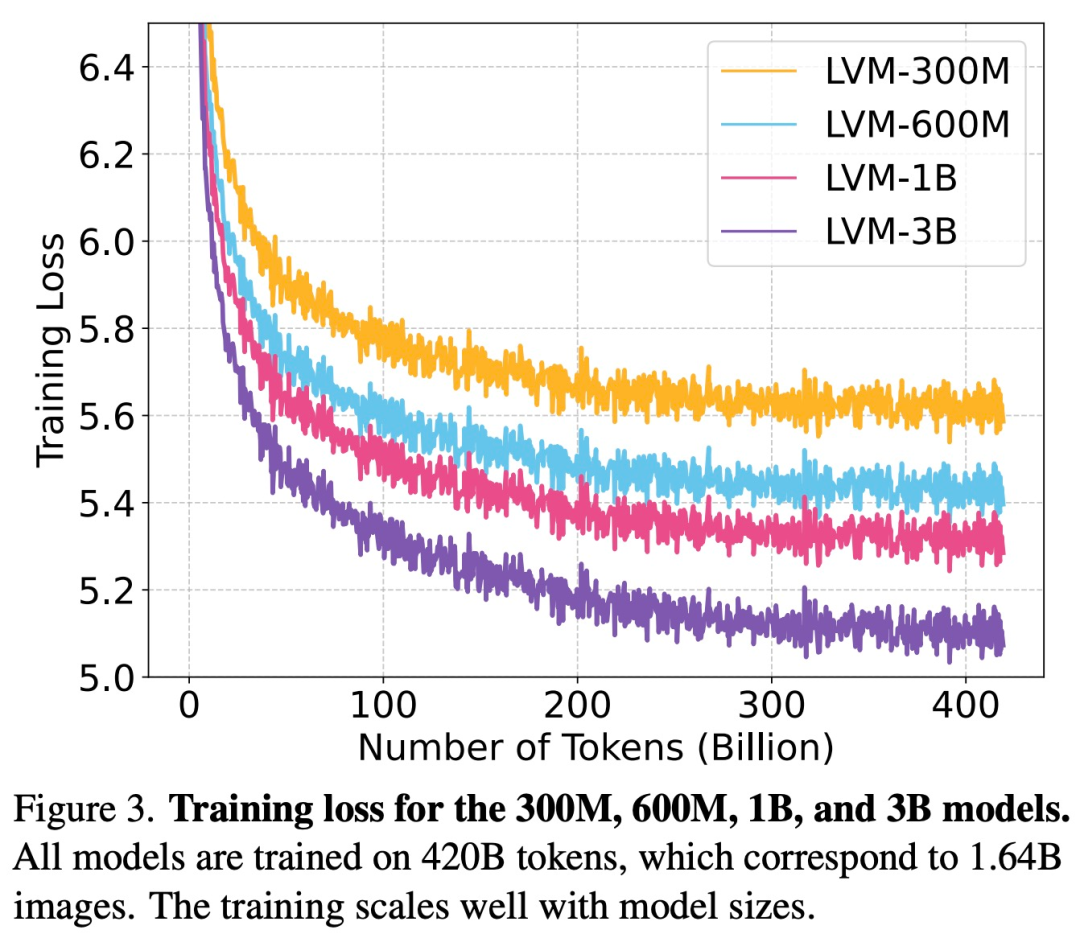
根据图3所示,该研究首先对不同尺寸的LVM进行了训练损失的检查
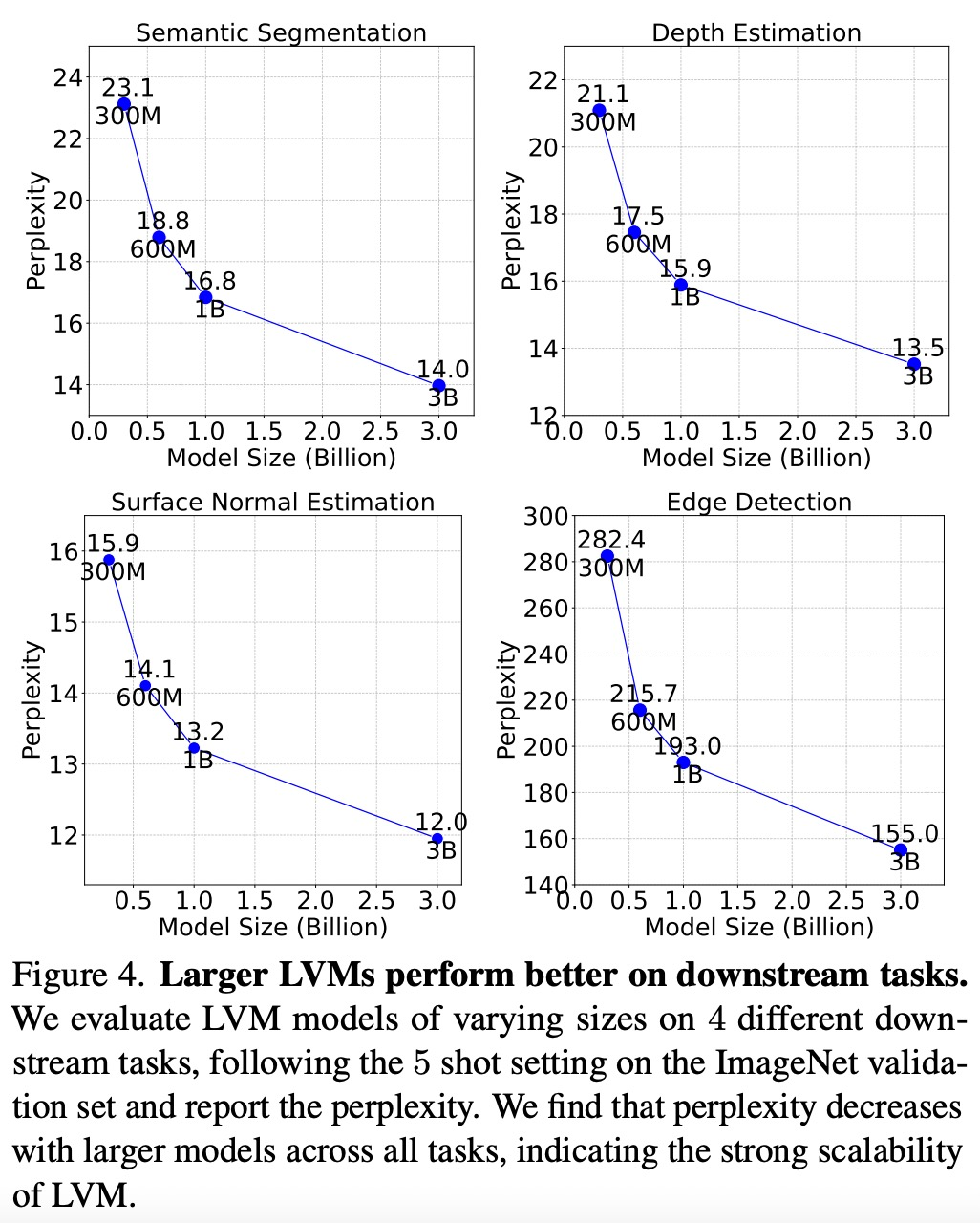
如下图 4 所示,较大的模型在所有任务中复杂度都是较低的,这表明模型的整体性能 可以迁移到一系列下游任务上。
可以迁移到一系列下游任务上。
根据图5所示,每个数据组件都对下游任务有重要的影响。LVM不仅可以从更大的数据中受益,而且还能随着数据集的多样性而改进
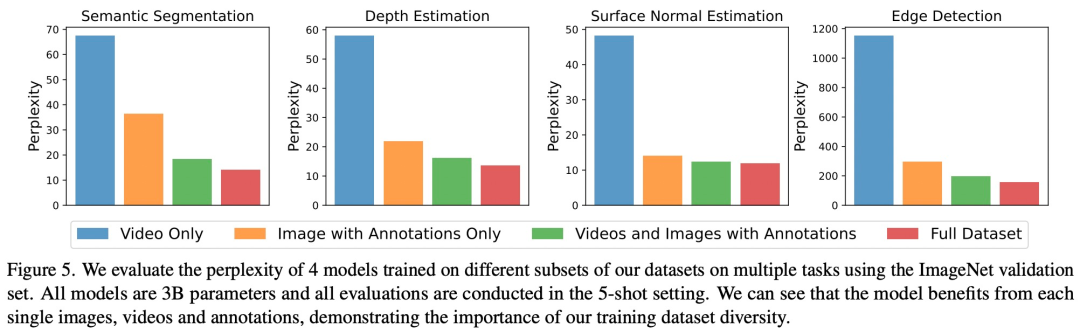
重写内容,而不改变原意,需要将语言重写为中文。 应该出现原句
为了测试 LVM 对各种 prompt 的理解能力,该研究首先在序列推理任务上对 LVM 进行评估实验。其中,prompt 非常简单:向模型提供 7 张图像的序列,要求它预测下一张图像,实验结果需要被重写如下图 6 所示:

该研究还将给定类别的项目列表视为一个序列,让 LVM 预测同一类的图像,实验结果需要被重写如下图 15 所示:

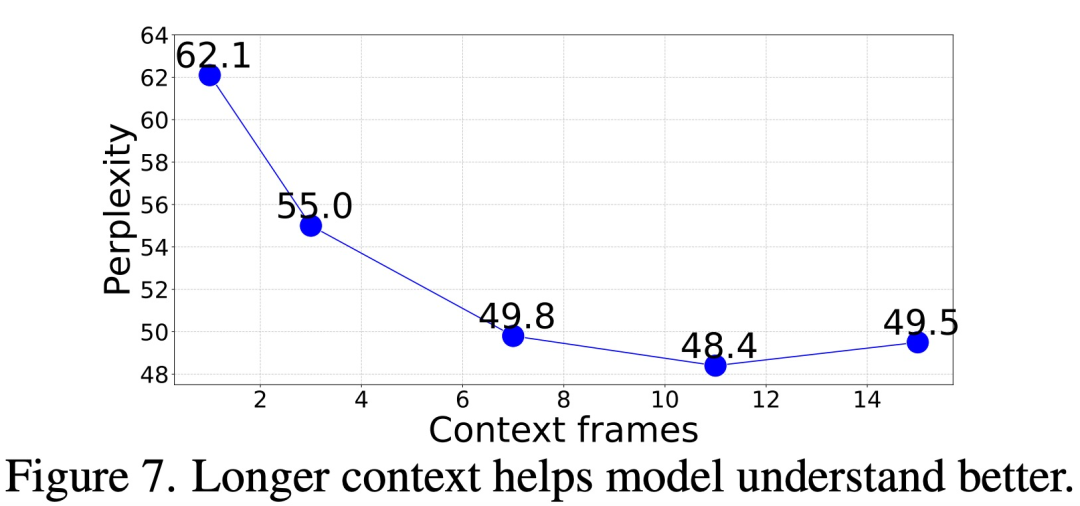
那么,需要多少上下文(context)才能准确预测后续帧?
在这项研究中,我们对模型的帧生成困惑度进行了评估,这是通过给出不同长度(1 到 15 帧)的上下文 prompt 来实现的。结果显示,困惑度随着帧数的增加而逐渐改善。具体数据如下图 7 所示,困惑度从 1 帧到 11 帧有明显的改善,之后趋于稳定(62.1 → 48.4)
Analogy Prompt
这项研究还测试了LVM的高级解释能力,通过评估更复杂的提示结构,如类比提示
下图 8 显示了对许多任务进行 Analogy Prompt 的定性结果:

根据与视觉 Prompting 的比较,可以看出序列 LVM 在几乎所有任务上都比以前的方法更优

合成任务。图9显示了使用单个提示将多个任务组合在一起的结果

其他 prompt
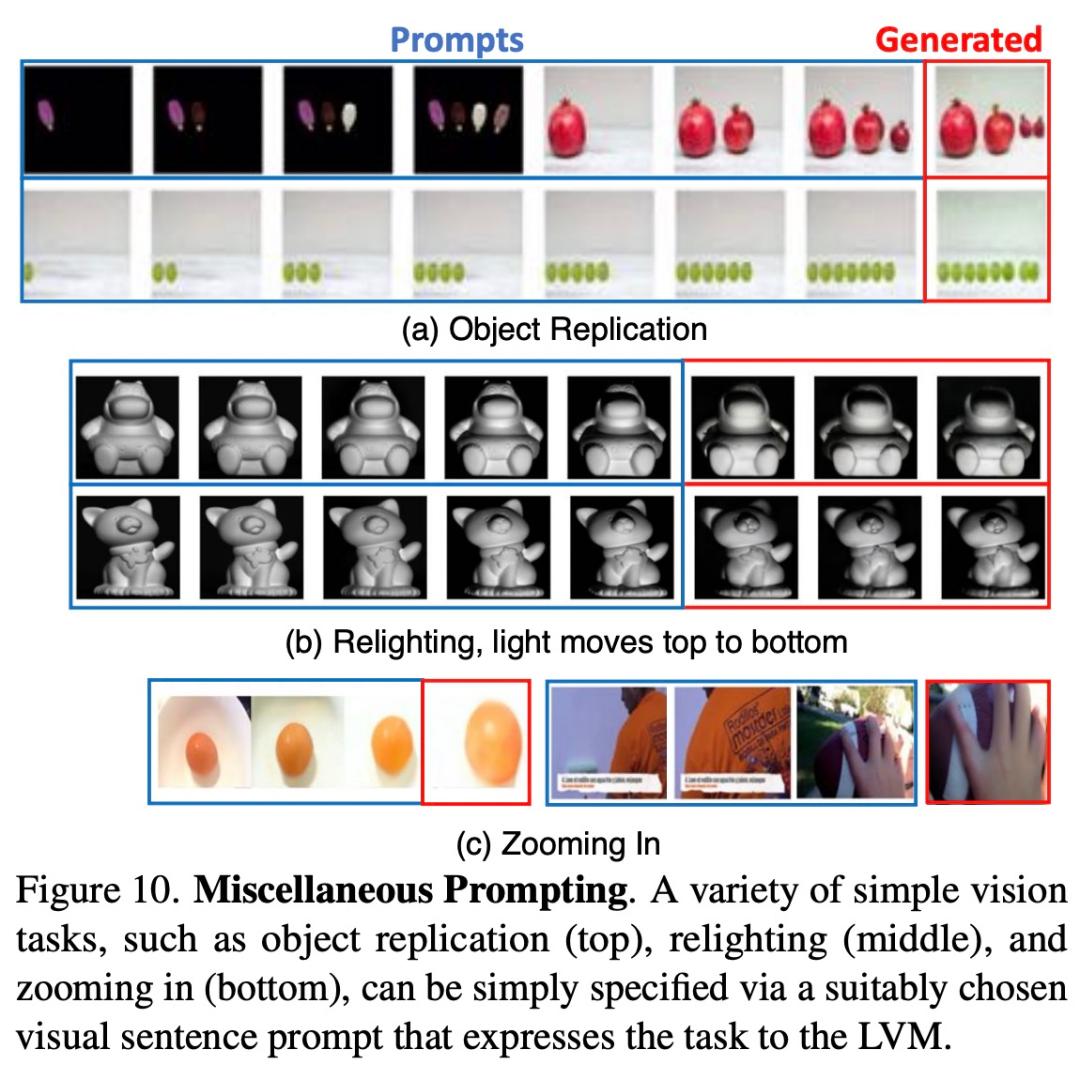
研究者试图通过向模型提供它以往未见过的各种 prompt,来观察模型的为了扩展业务,我们需要寻找新的市场机会。我们计划进一步扩大产品线,以满足不断增长的需求。同时,我们将加强市场营销策略,提高品牌知名度。通过积极参与行业展览和推广活动,我们将努力开拓更多的客户群体。我们相信,通过这些努力,我们能够取得更大的成就并实现持续增长能力到底怎样。下图 10 展示了一些运行良好的此类 prompt。
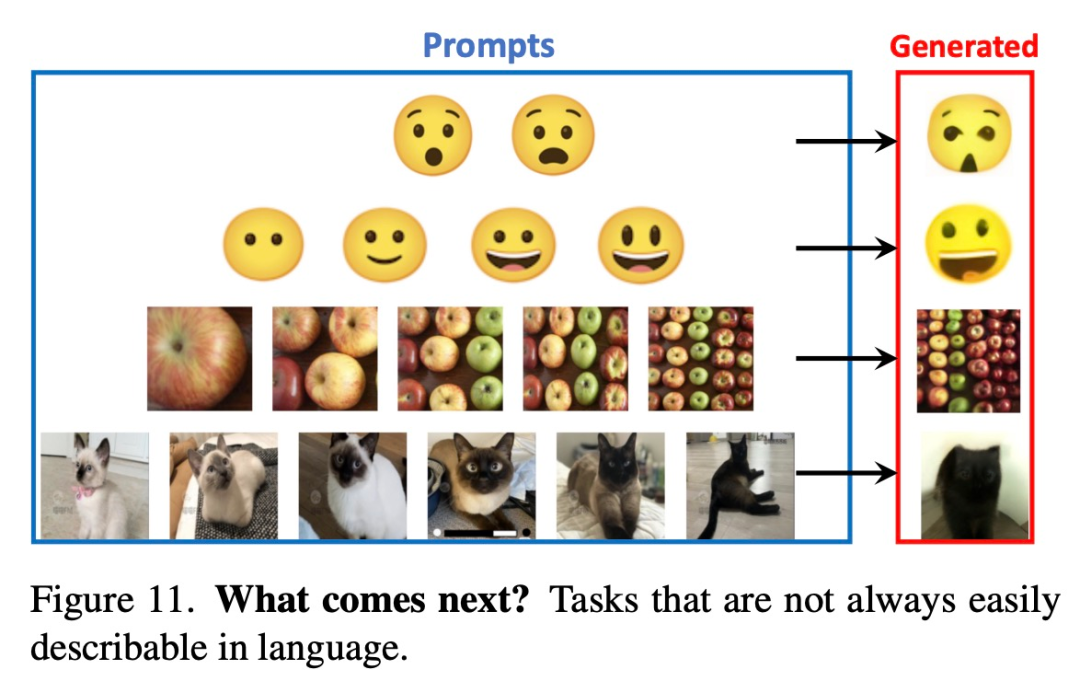
下图 11 展示了一些用文字难以描述的 prompt,这些任务上 LVM 最终可能会胜过 LLM。
在非语言人类 IQ 测试中,图 13 展示了典型视觉推理问题的初步定性结果

阅读原文,了解更多细节。
以上就是UC伯克利成功开发通用视觉推理大模型,三位资深学者合力参与研究的详细内容,更多请关注其它相关文章!
# llava
# 肇庆网站建设推广有哪些
# 装修行业营销推广平台
# 嘉峪关整合营销推广
# 多个
# 推广活动
# 这一
# 持续增长
# 约翰
# 积极参与
# 重写
# 更大
# 所示
# 伯克利
# type
# llama
# 理论
# 新型的泉州seo方案
# 营销推广方案案例分析题
# 超快排关键词排名系统
# 郑州问答推广营销
# 桂园独立网站推广
# seo优化提升排名推广
# 龙口营销推广哪家好
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
内在市盈率是什么意思
ka是什么意思
如何去掉拍电脑的纹路详细教程
win7怎么做幻灯片
a股等权市盈率中位数是什么意思
gs是什么意思
苹果16自带配件有哪些
夸克高考为什么不靠谱
为什么夸克运行不了
typescript怎么拼接
怎么在爱奇艺中投屏到电视最新方法
怎么在typescript写原型链
固态硬盘如何显示
tft单片机怎么写彩屏
如何发挥固态硬盘性能
react怎么使用 typescript
三星固态硬盘如何安装
虚拟机服务器如何关机命令
bc是什么意思
苹果16有哪些自带配件
什么是base64
manager是什么意思
play的三人称单数和过去式
羽毛球拍power9是什么意思
手机拍电脑屏幕有条纹怎么解决
语音聊天软件哪个好 语音聊天软件2025排行榜
如何去除计算器的命令
hive中datediff函数怎么用 Hive中DATEDIFF函数的使用指南
如何操作fixup命令
面包车收音机power是什么意思
今天是农历多少号
固态硬盘如何判断大小
360n7lite怎么设置动态壁纸
ospf中交换机命令如何设置
三星相机里power是什么意思
夸克文字口令是什么意思
数组和J*A怎么打
driver是什么意思
如何在命令提示符播放音频
跑步机power键是什么意思
估值水平比较中市盈率E是什么意思
得物怎样降低手续费 得物如何降低手续费教程
m*en repository的作用是什么
8k是多少钱
HTML5如何引用typescript
华为5g手机怎么用4g网络
春运抢票要用抢票软件吗
移动固态硬盘如何使用
固态硬盘 如何分区
固态硬盘2m如何修复
