









新闻中心 
突破分辨率极限:字节联合中科大揭示多模态文档大模型
 2023-12-04
2023-12-04 浏览次数:次
浏览次数:次 返回列表
返回列表现在甚至有了大型的多模态高分辨率文档!
这项技术不仅能够准确识别图像中的信息,还能够根据用户需求调用自身的知识库来回答问题
比如,看到图中马里奥的界面,直接就回答出了这是任天堂公司的作品。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

这个模型是由字节跳动和中国科学技术大学合作研究的,于2025年11月24日上传至arXiv
在此研究中,作者团队提出DocPedia,一个统一的高分辨率多模态文档大模型DocPedia。

在此研究中,作者用一种新的方式解决了现有模型不能解析高分辨文档图像的短板。
DocPedia分辨率可达2560×2560,而目前业内先进多模态大模型如LLaVA、MiniGPT-4等处理图像分辨率上限为336×336,无法解析高分辨率的文档图像。
那么,这款模型究竟表现如何,又使用了怎样的优化方式呢?
各项测评成绩显著提升
在这篇论文中,作者展示了DocPedia高分辨图文理解的示例。可以观察到DocPedia有能力理解指令内容,并从高分辨率的文档图像和自然场景图像中准确地提取相关的图文信息
比如这组图中,DocPedia轻松从图片中挖掘出了车牌号、电脑配置等文本信息,甚至手写文字也能准确判断。

结合图像中的文本信息,DocPedia还可以利用大模型推理能力,根据上下文分析问题。

DocPedia在读取完图片信息后,还会根据其丰富的世界知识库,回答图像中未展示的扩展内容

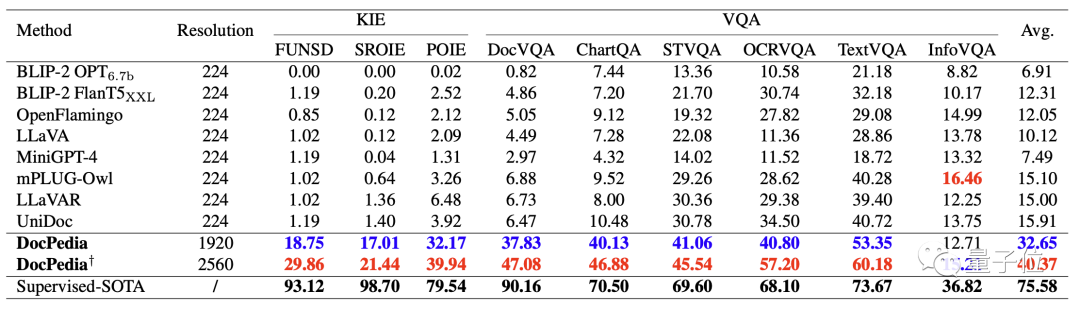
下表定量对比了现有的一些多模态大模型和DocPedia的关键信息抽取(KIE)和视觉问答(VQA)能力。
通过提升分辨率和采用有效的训练方法,我们可以看到DocPedia在各项测试基准上都取得了显著的提升
那么,DocPedia是如何实现这样的效果的呢呢?
从频域出发解决分辨率问题
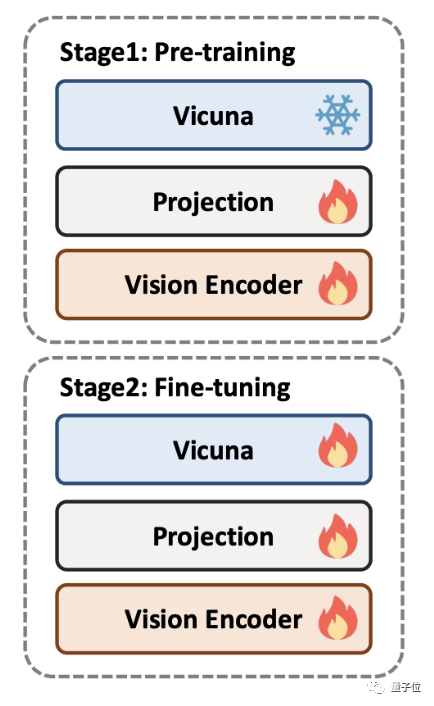
DocPedia的训练分为两个阶段:预训练和微调。为了训练DocPedia,作者团队收集了包含各类文档的大量图文数据,并构建指令微调数据集。
在预训练阶段,大型语言模型将被冻结,而只优化视觉编码器的部分,以使其输出的token表征空间与大型语言模型保持一致
在这个阶段,作者团队提出主要训练DocPedia的感知能力,包括对文字和自然场景的感知
 VALL-E
VALL-E
VALL-E是一种用于文本到语音生成 (TTS) 的语言建模方法
 134
查看详情
134
查看详情

预训练任务包括文字检测、文字识别、端到端OCR、段落阅读、全文阅读,以及图像文字说明。
在微调阶段,大型语言模型解除冻结,进行端到端整体优化
作者团队提出了感知-理解联合训练策略:在原有的低阶感知任务基础上,增加了文档理解和场景图像两种高阶的偏语义理解任务
这样一种感知-理解联合训练策略,进一步提高了DocPedia的性能。
在分辨率问题的策略上,与现有方法不同,DocPedia从频域的角度出发去解决。
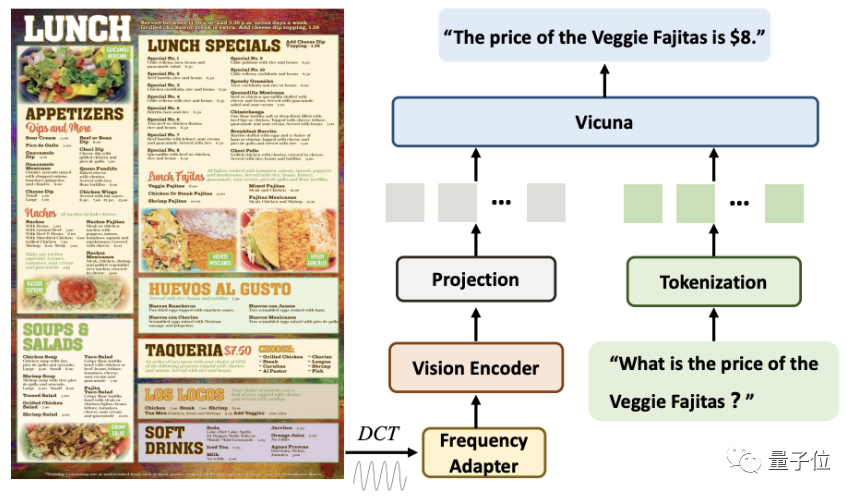
在处理高分辨率文档图像时,DocPedia会首先提取其DCT系数矩阵。这个矩阵可以在不损失原图像的图文信息的情况下,将其空间分辨率下采样8倍
经过这一步骤后,我们会使用级联的频域适配器(Frequency Adapter)将输入信号传递给视觉编码器(Vision Encoder),以进行更深层次的分辨率压缩和特征提取
通过此方法,一张2560×2560的图像,其图文信息可以用1600个token表示。
该方法相较于直接将原始图像输入到视觉编码器(如Swin Transformer)中,token数量减少4倍。
最后,这些token与指令转换而来的token进行序列维度拼接,输入到大模型进行回答。
消融实验的结果显示,提高分辨率和进行感知-理解联合微调是提升DocPedia性能的两个重要因素
下图对比了DocPedia对于一张论文图像以及同一个指令,在不同输入尺度下的回答。可以看到,当且仅当分辨率提升至2560×2560时,DocPedia回答正确。

下图则对比了DocPedia对于同一张场景文字图像以及同一个指令,在不同微调策略下模型的回答。
通过这个例子可以看出,经过感知-理解联合微调的模型,能够准确地进行文字识别和语义问答

请点击以下链接查看论文:https://arxiv.org/abs/2311. 11810
11810
以上就是突破分辨率极限:字节联合中科大揭示多模态文档大模型的详细内容,更多请关注其它相关文章!
# 马里奥
# 晋州优化seo
# ai网站引流推广怎么做
# 王牌战士seo联盟成员
# 中式面点营销推广
# 广州平台网站推广费用高
# 杭州企业网站建设价格
# seo新闻稿
# 南阳河南网站建设
# 龙华网站建设内容
# 济南协会网站建设公司
# 数据
# 可以看到
# 将于
# 三大
# 比了
# 在此
# 出了
# 中科大
# 多模
# 文档
# 训练
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
vs如何输入命令行参数
夸克内测有什么好处
五十铃x-power是什么意思
折叠屏手机哪个卖得最好
为什么夸克运行不了
typescript怎么加号
电脑命令如何删除账号
苹果16有哪些自带配件
新装固态硬盘如何安装
如何给电脑加装固态硬盘
所有删除的聊天记录都可以恢复吗?
51单片机怎么连接端口
春运抢票需要什么软件抢
类似微信的聊天软件有哪些
闲鱼上面的power是什么意思
华为交换机 配置 如何复制命令行
typescript 如何使用
春运抢票多久能知道成功
记录仪power灯亮是什么意思
折叠屏手机为什么有黑点
mysql的datediff函数怎么用
如何用命令查看本机的操作系统
python和typescript学哪个
excel中datediff函数怎么用
如何通过命令行聊天
移动固态硬盘如何使用
typescript和node学哪个
j*a怎么用数组缓存
如何查看邮件域名解析
苹果16系统有哪些改变
12306退票手续费最新规定
1kb等于多少字节
新的固态硬盘如何分区
固态硬盘如何打开软件
基金市盈率是什么意思
怎么在typescript写原型链
sofa是什么意思
进口超级维特拉三门版power是什么意思
市盈率当中17A 18E是什么意思
对应市盈率是30X是什么意思
type-c全能接口是什么意思
阿里云盘扩容是什么_扩容阿里云盘方法是什么教程
宝马x5仪表盘上边有power是什么意思
春运什么时候开始抢票
市盈率tt的扣非是什么意思
openwrt有哪些功能
360n5锁屏壁纸怎么设置
怎么下载360桌面壁纸
如何把u盘改成固态硬盘
juice是什么意思
