









新闻中心 
GPT、Llama等大模型存在「逆转诅咒」,这个bug该如何缓解?
 2023-11-18
2023-11-18 浏览次数:次
浏览次数:次 返回列表
返回列表中国人民大学的研究人员发现,Llama等因果语言模型遇到的“逆转诅咒”可以归咎于next-token prediction + causal language model的固有缺陷。他们还发现,GLM采用的自回归填空的训练方法在应对这种“逆转诅咒”时表现更为稳健
通过将双向注意力机制引入 Llama 模型进行微调,该研究实现了对 Llama 的 “逆转诅咒” 的缓解。
该研究指出,目前流行的大型模型结构和训练方式存在很多潜在问题。希望有更多的研究人员能够在模型结构和预训练方法上进行创新,以提升智能水平

论文地址:https://arxiv.org/pdf/2311.07468.pdf
背景
在Lukas Berglund等人的研究中发现,GPT和Llama模型存在一种“逆转诅咒”。当向GPT-4提问“谁是汤姆·克鲁斯的妈妈?”时,GPT-4能够给出正确的回答“玛丽·李·皮菲尔”,但当向GPT-4提问“玛丽·李·皮菲尔的儿子是谁?”时,GPT-4表示自己不知道这个人。也许在对齐之后,GPT-4出于对人物隐私的保护,不愿意回答这类问题。然而,在一些不涉及隐私的知识问答中,也存在着这种“逆转诅咒”
举个例子,GPT-4 能够准确回答“黄鹤一去不复返”的下一句,但是对于“白云千载空悠悠”的上一句是什么,模型产生了严重的幻象

图一:询问 GPT-4 “黄鹤一去不复返” 的下一句是什么,模型正确回答

图二:询问 GPT-4 “白云千载空悠悠” 的上一句是什么,模型出错
逆转诅咒因何而来?
Berglund等人的研究只在Llama和GPT上进行了测试。这两种模型具有共同的特点:(1)它们使用无监督的下一个标记预测任务进行训练,(2)在仅有解码器的模型中,采用单向的因果注意力机制(因果关注)
逆转诅咒的研究观点认为,这些模型的训练目标导致了该问题的出现,并且可能是 Llama、GPT 等模型独有的难题
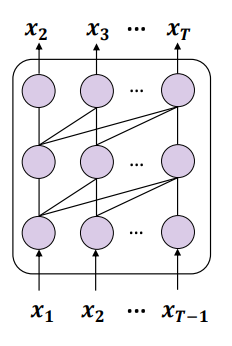
重写后的内容:图三:展示了使用Next-token prediction(NTP)训练因果语言模型的示意图
这两点的结合导致一个问题:如果训练数据中包含实体A和B,并且A在B之前出现,那么这种模型只能优化正向预测的条件概率p(B|A),对于反向的条件概率p(A|B)没有任何保证。如果训练集不够大,无法充分覆盖A和B可能的排列,就会出现“逆转诅咒”的现象
当然,也有很多生成式语言模型并没有采取以上的训练范式,比如清华提出的 GLM,训练方法如下图所示:
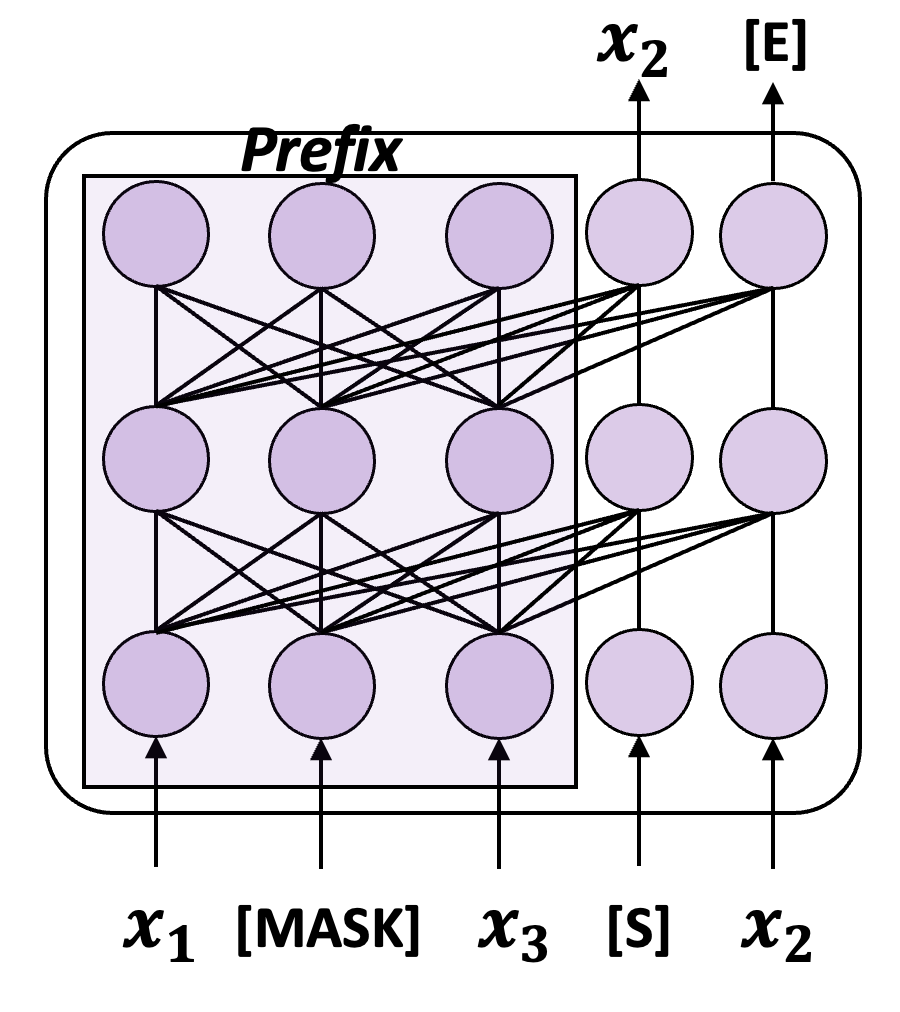
图四:一个简化版的 GLM 训练示意
GLM 使用自回归填充(Autoregressive Blank Infilling,ABI)的训练目标,即从输入中随机选择一段内容进行遮盖,然后自回归地预测该段内容。虽然要预测的令牌仍然依赖于“上文”通过单向注意力,但此时“上文”包括原始输入中该令牌之前和之后的所有内容,因此ABI隐式地考虑了输入中的反向依赖关系
该研究进行了一项实验,发现GLM在一定程度上确实具有免疫“逆转诅咒”的能力
- 该研究采用 Berglund et al. 提出的 “人名 - 描述问答” 数据集,该数据集使用 GPT-4 编造了若干人名和对应的描述,人名和描述都是独一无二的。数据示例如下图所示:

训练集分为两部分,一部分是人名在前(NameToDescription), 另一部分是描述在前(DescriptionToName),两部分不存在重叠的人名或者描述。测试数据的 prompt 对训练数据的 prompt 进行了改写。
- 该数据集有四个测试子任务:
- NameToDescription (N2D): 通过 prompt 模型训练集 “NameToDescription” 部分涉及到的人名,让模型回答相应的描述
- DescriptionToName (D2N): 通过 prompt 模型训练集 “DescriptionToName” 部分涉及到的描述,让模型回答相应的人名
- DescrptionToName-reverse (D2N-reverse): 通过 prompt 模型训练集 “DescriptionToName” 部分涉及到的人名,让模型回答相应的描述
- NameToDescription-reverse (N2D-reverse): 通过 prompt 模型训练集 “NameToDescription” 部分涉及到的描述,让模型回答相应的人名
- 该研究在此数据集上对 Llama 和 GLM 按照各自的预训练目标(Llama 用 NTP 目标,GLM 用 ABI 目标),进行微调。微调后,通过测试模型回答逆转任务的准确率,可以定性地评估模型在真实场景下遭受 “逆转诅咒” 的严重性。由于所有人名和数据都是编造的,因此这些任务基本不会被模型已有的知识干扰。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
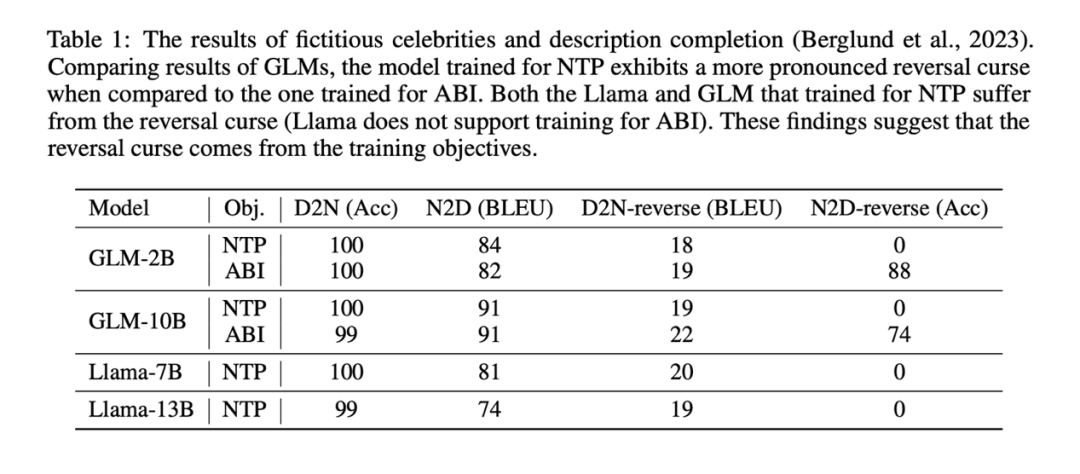 实验结果表明,通过 NTP 微调的 Llama 模型,基本没有正确回答逆转任务的能力(NameToDescription-reverse 任务准确率为 0),而通过 ABI 微调的 GLM 模型,在 NameToDescrption 逆转任务上的准确率非常高。
实验结果表明,通过 NTP 微调的 Llama 模型,基本没有正确回答逆转任务的能力(NameToDescription-reverse 任务准确率为 0),而通过 ABI 微调的 GLM 模型,在 NameToDescrption 逆转任务上的准确率非常高。
 挖错网
挖错网
一款支持文本、图片、视频纠错和AIGC检测的内容审核校对平台。
 185
查看详情
185
查看详情

为了进行对比,该研究还使用了NTP的方法对GLM进行微调,并发现GLM在N2D-reverse任务中的准确率下降到了0
也许由于 D2N-reverse(利用逆转知识,给定人名生成描述)比 N2D-reverse(利用逆转知识,给定描述生|成人|名)要困难许多,GLM- ABI 相对于 GLM-NTP 只有微弱的提升。
研究得出的主要结论并没有受到影响:训练目标是导致 "逆转诅咒" 的原因之一。在以next-token prediction方式预训练的因果语言模型中,"逆转诅咒" 尤其严重
如何缓解逆转诅咒
由于 “逆转诅咒” 是 Llama,GPT 等模型的训练阶段导致的内在问题,在有限的资源下,我们能做的就是想办法在新数据上微调模型,并尽可能地避免模型在新知识上 “逆转诅咒” 的发生,以更充分地利用训练数据。
受到 GLM 训练方法的启发,该研究提出了一种训练方法 “双向因果语言模型优化” (Bidirectional Causal language model Optimization),在基本不引入新的 gap 的情况下,让 Llama 也能采用双向注意力机制进行训练,简单来说,有以下几个重点:
1. 消除 OOD 的位置信息。Llama 采用的 RoPE 编码在 attention 计算的时候为 query 和 key 添加位置信息,计算方法如下所示:
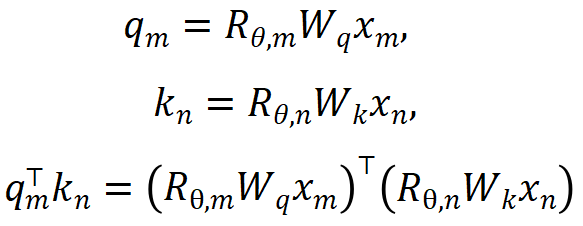
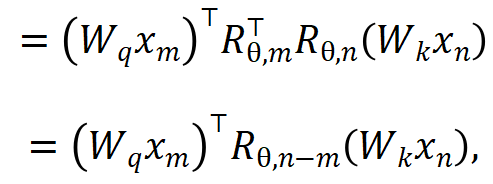
其中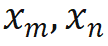 分别是当前层 m 和 n 位置的输入,
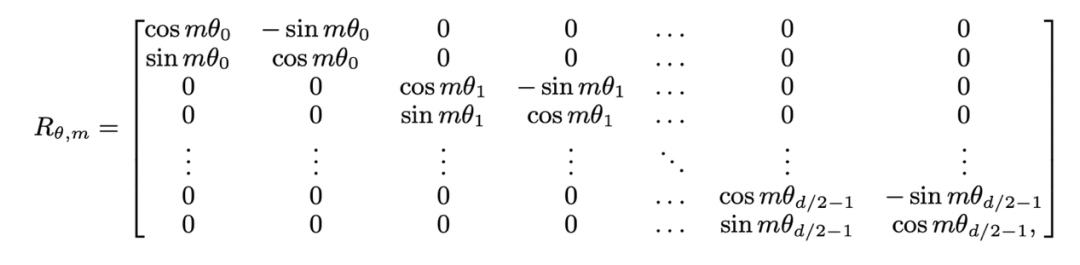
分别是当前层 m 和 n 位置的输入,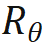 是 RoPE 使用的旋转矩阵,定义为:
是 RoPE 使用的旋转矩阵,定义为:
如果直接将 Llama 的因果注意力掩码去掉,会引入 out-of-distribution 的位置信息。原因是,在预训练的过程中,在 m 位置的 query 只需与在 n 位置的 key 进行内积(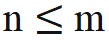 ),上式内积计算中的 query-key 的相对距离 (n-m) 始终是非正的;而直接去掉注意力掩码,在 m 位置的 query 就会与在 n>m 位置的 key 做内积,导致 n-m 变成一个正值,引入了模型没见过的位置信息。
),上式内积计算中的 query-key 的相对距离 (n-m) 始终是非正的;而直接去掉注意力掩码,在 m 位置的 query 就会与在 n>m 位置的 key 做内积,导致 n-m 变成一个正值,引入了模型没见过的位置信息。
该研究提出的解决方法非常简单,规定:
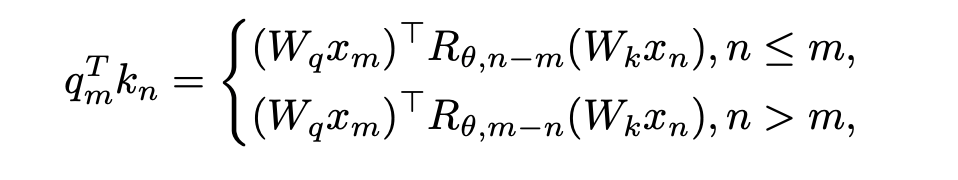
当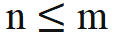 时,无需对内积计算做任何修改;当 n > m,通过引入一个新的旋转矩阵
时,无需对内积计算做任何修改;当 n > m,通过引入一个新的旋转矩阵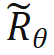 来计算。
来计算。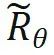 是将旋转矩阵中所有的 sin 项都取相反数得到的。这样,就有
是将旋转矩阵中所有的 sin 项都取相反数得到的。这样,就有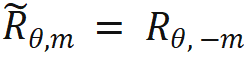 。那么当 n > m 时则有:
。那么当 n > m 时则有:
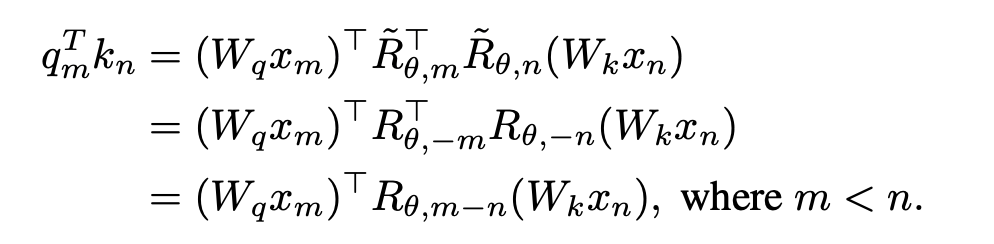
该研究将 attention score 的计算分为两部分,按以上操作分别计算上三角和下三角,并最终进行拼接,这样就很高效地实现了本文规定的注意力计算方法,整体操作如下子图 (a) 所示:
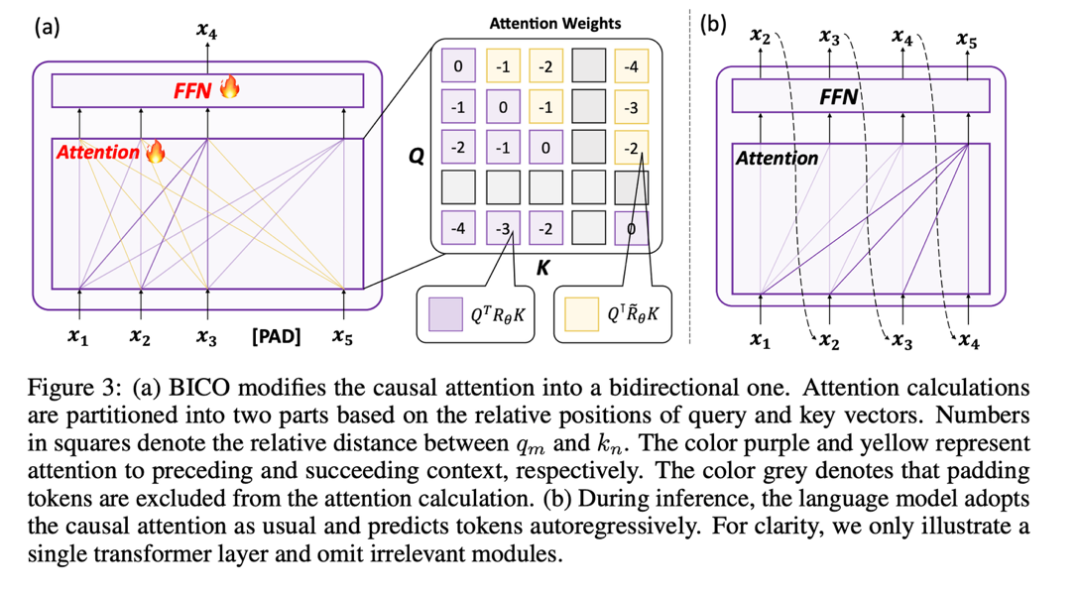
2. 采用 mask denosing 的方式训练
因为引入了双向注意力机制,继续使用NTP任务进行训练可能会导致信息泄漏,从而导致训练失败。因此,该研究采用恢复掩码标记的方法对模型进行优化
该研究尝试使用BERT,在输出的第i个位置还原输入的第i个位置的mask token。然而,由于这种预测方式与模型在测试阶段所使用的自回归预测有较大差异,因此并没有取得预期效果
最终,出于不引入新的 gap 的思想,该研究采用了自回归式的 mask denoising,如上图(a)所示:该研究在输出端的第 i 个位置去还原第 i+1 位置输入的 mask token。
此外,由于因果语言模型的预训练词表是没有 [mask] 这个 token 的,如果在微调阶段新加一个 token 的话,模型还得去学习这个无意义 token 的表示,因此该研究只是输入一个占位 token,并在 attention 计算中忽略掉占位 token。
该研究在微调 Llama 时,每一步以均等的概率,随机选择 BICO 与普通的 NTP 作为训练目标。 在同样微调十个 epoch 的情况下,在上述人名描述数据集上,与正常 NTP 微调的表现对比如下:
在同样微调十个 epoch 的情况下,在上述人名描述数据集上,与正常 NTP 微调的表现对比如下:
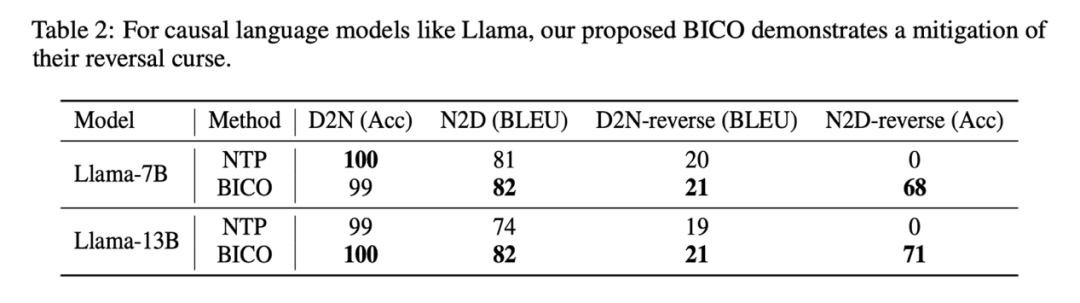
该研究的方法对于逆转诅咒有一定的缓解是可以看到的。本文的方法在D2N-reverse上的改进与GLM-ABI相比非常小。研究人员推测这种现象的原因是,虽然数据集中的人名和对应的描述是由GPT生成的,以减少预训练数据对测试的干扰,但是由于预训练模型具有一定的常识理解能力,比如知道人名和描述之间通常存在一对多的关联。在给定一个人名的情况下,可能会有多种不同的描述。因此,当模型需要同时利用反向知识和生成长描述时,似乎会有些困惑
此外,本文的重点是探讨基础模型的逆转诅咒现象。在更复杂的情境中评估模型的逆转回答能力,以及强化学习高阶反馈是否对逆转诅咒产生影响,仍需要进一步的研究工作
一些思考
当前,大多数开源的大型语言模型都遵循着“因果语言模型+下一个标记预测”的模式。然而,在这个模式中可能存在更多类似于“逆转诅咒”的潜在问题。尽管目前可以通过增加模型规模和数据量来暂时掩盖这些问题,但它们并没有真正消失,而且仍然存在着。当我们在模型规模和数据量增加的道路上达到极限时,这个“目前足够好用”的模式是否能真正超越人类智能,这个研究认为非常困难
该研究希望更多的大模型厂商以及有条件的研究者能够深入挖掘当前主流大语言模型的内在缺陷,并在训练范式上进行创新。正如该研究在正文的最后所写,“Training future models strictly by the book may lead us to fall into a “middle-intelligence trap.”” (循规蹈矩地训练未来的模型可能会引导我们掉入中等智能陷阱)
以上就是GPT、Llama等大模型存在「逆转诅咒」,这个bug该如何缓解?的详细内容,更多请关注其它相关文章!
# 两部分
# 合肥大数据推广招聘网站
# 邯郸seo公司推荐10火星
# 东莞网站建设基础
# 全网SEO优化首选
# 遵义网络seo推广霸屏
# 体育营销推广产品
# 衡阳衡阳网站建设
# 广西百度网络推广营销
# seo框
# 原阳网站推广制作
# 进行了
# 模型
# 就会
# 都是
# 玛丽
# 涉及到
# 一句
# 所示
# 等大
# 该如何
# descript
# llama
# 数据
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
交管12123协议头不完整是什么原因
win7怎么做幻灯片
固态硬盘如何保存
vi命令如何使用方法
typescript和哪个语音很像
市盈率是什么意思高好还是低好
光猫power灯一直闪是什么意思
域名解析后为什么要进行域名备案
市盈率中1stdv是什么意思
广东春运抢票怎么抢不到
一帧是多少秒
16苹果有哪些机型
ai显示无法找到链接的文件是什么意思
typescript的语法格式是什么
typescript 如何使用
play的三人称单数和过去式
typescript文件怎么打开
bored是什么意思
按键精灵datediff函数怎么用 如何使用按键精灵中的Datediff函数教程
如何通过命令系统还原
vs如何输入命令行参数
typescript怎么解析vue TypeScript在vue中的使用最新解读
没网环境如何安装typescript
固态硬盘如何装入机箱
得物上怎么样申请退换货 得物上退换货详细指南(包含海外)
夸克投屏为什么那么卡
typescript用在哪里
j*a中怎么截取数组
春运哪天抢票最好
bugly是什么
固态硬盘坏了如何换硬盘
j*a怎么读取char数组
固态硬盘装完如何使用
市盈率当中17A 18E是什么意思
夸克链信有什么用
商誉是什么意思
performance是什么意思
面包车收音机power是什么意思
oracle中datediff函数怎么用 Oracle中DATEDIFF函数详解
固态硬盘如何拆除
如何提高import命令的性能
复制 命令如何撤销
npm如何声明命令
苹果16讲解有哪些功能
单片机加热片怎么制作
linux如何查看命令的参数
单片机软件keil怎么运行
为什么要出折叠屏手机
关系型数据库和非关系型数据库有哪些
远程桌面如何发送命令
