









新闻中心 
DeepMind:谁说卷积网络不如ViT?
 2023-11-02
2023-11-02 浏览次数:次
浏览次数:次 返回列表
返回列表本文对按比例扩大的 nfnets 进行了评估,并挑战了 convnets 在大规模问题上表现不如 vits 的观点
深度学习的早期成功可归功于卷积神经网络(ConvNets)的发展。近十年来,ConvNets 主导了计算机视觉基准测试。然而近年来,它们越来越多地被 ViTs(Vision Transformers)所取代。
很多人认为,ConvNets 在小型或中等规模的数据集上表现良好,但在那种比较大的网络规模的数据集上却无法与 ViTs 相竞争。
同时,CV 社区已经从评估在特定数据集(如 ImageNet)上随机初始化网络的性能,转变为评估从网络收集的大型通用数据集上预训练的网络的性能。这引出了一个重要的问题:在相似的计算预算下,Vision Transformers 是否优于预先训练的 ConvNets 架构?
在这篇文章中,来自Google DeepMind的研究人员对这个问题进行了研究。他们通过在不同尺度的JFT-4B数据集上对多种NFNet模型进行预训练,获得了类似于ViTs在ImageNet上的性能
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接地址:https://arxiv.org/pdf/2310.16764.pdf
本文的研究讨论了预训练计算预算在0.4k到110k TPU-v4核计算小时之间的情况,并利用增加NFNet模型家族的深度和宽度来进行一系列网络训练。研究发现,存在着 held out 损失与计算预算之间的对数-对数扩展率(scaling law)
例如,本文将以JFT-4B为基础,在TPU-v4核小时(核心小时)从0.4k扩展到110k,并对NFNet进行预训练。经过微调,最大的模型在ImageNet Top-1上达到了90.4%的 准确率,在相同的计算预算下与预训练的ViT模型竞争
准确率,在相同的计算预算下与预训练的ViT模型竞争
可以说,本文通过评估按比例扩大的 NFNets,挑战了 ConvNets 在大规模数据集上表现不如 ViTs 的观点。此外,在足够的数据和计算条件下,ConvNets 仍然具有竞争力,模型设计和资源比架构更重要。
看到这项研究后,图灵奖得主Yann LeCun表示:“在给定的计算量下,ViT和ConvNets在计算上是相当的。虽然ViTs在计算机视觉方面取得了令人印象深刻的成功,但在我看来,没有强有力的证据表明,在公平评估时,预训练的ViT优于预训练的ConvNets。”
然而,有网友对LeCun的评论表示,他认为在多模态模型中使用ViT可能仍然使其在研究中具有优势
来自 Google DeepMind 的研究员表示,ConvNets 永远不会消失

接下来我们看看论文具体内容。
预训练的 NFNets 遵循扩展定律
 短影AI
短影AI
长视频一键生成精彩短视频
 170
查看详情
170
查看详情

本文在 JFT-4B 上训练了一系列不同深度和宽度的 NFNet 模型。
根据图2所示,验证损失与训练模型的计算预算呈线性关系,与使用Transformer进行语言建模时观察到的双对数(log-log)扩展定律相符。随着计算预算的增加,最佳模型大小和最佳epoch预算(实现最低验证损失)也会增加

在下面的图表中,我们可以看到三个模型在一系列的 epoch 预算中观察到的最佳学习率(即最大程度地减少验证损失)。研究人员发现,对于较低的 epoch 预算,NFNet 系列模型都显示出类似的最佳学习率,约为1.6。然而,随着 epoch 预算的增加,最优学习率会下降,并且对于更大的模型,最优学习率下降得更快。研究人员表示,可以假设最优学习率会随着模型大小和 epoch 预算的增加而缓慢且单调地下降,因此在两次试验中可以有效地调整学习率

需要重新写的内容是:需要注意的是,图表2中一些预训练模型的表现不如预期。研究团队认为,出现这种情况的原因是如果训练运行被抢占/重新启动,数据加载流程无法保证每个训练样本在每个周期都能被采样一次。如果训练运行多次重新启动,则可能导致某些训练样本的采样次数不足
NFNet vs ViT
在ImageNet上进行的实验显示,经过微调的NFNet和Vision Transformer的性能相当
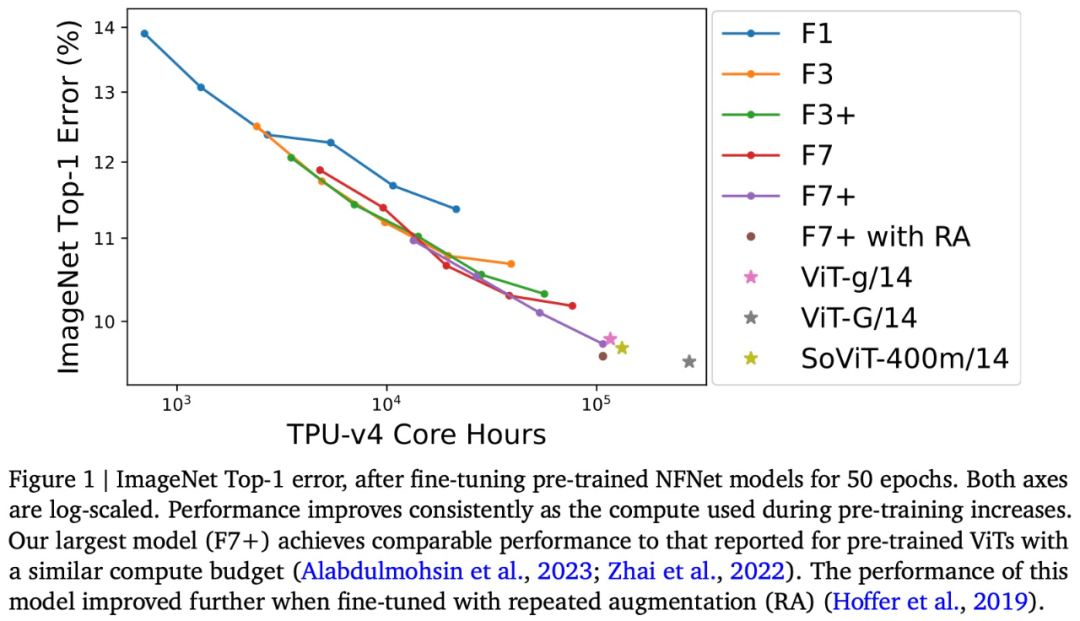
具体来说,该研究在 ImageNet 上微调了预训练 NFNet,并绘制了预训练计算与 Top-1 error 关系图,如上述图 1 所示。
随着预算的增加,ImageNet Top-1准确性持续提高。其中最昂贵的预训练模型是预训练8个epoch的NFNet-F7+,在ImageNet Top-1准确率达到了90.3%。预训练和微调需要大约110k TPU-v4核小时和1.6k TPU-v4核小时。此外,如果在微调期间引入额外的重复增强技术,可以实现90.4%的Top-1准确率。NFNet在大规模预训练中获得了很大的好处
尽管NFNet和ViT两种模型架构之间有明显的差异,但预训练的NFNet和预训练的ViT在性能上是相当的。例如,在对JFT-3B进行210k TPU-v3核小时的预训练后,ViT-g/14在ImageNet上实现了90.2%的Top-1准确率;而在对JFT-3B进行超过500k TPU-v3核小时的预训练后,ViT-G/14实现了90.45%的Top-1准确率
本文评估了这些模型在 TPU-v4 上的预训练速度,并估计 ViT-g/14 需要 120k TPU-v4 核小时来预训练,而 ViTG/14 则需要 280k TPU-v4 核小时数,SoViT-400m/14 将需要 130k TPU-v4 核小时数。本文使用这些估计来比较图 1 中 ViT 和 NFNet 的预训练效率。研究注意到,NFNet 针对 TPU-v4 进行了优化,在其他设备上评估时表现较差。
最终,本文注意到,在JFT-4B上,预训练的检查点实现了最低的验证损失,但在微调后,并不总能在ImageNet上实现最高的Top-1准确率。特别是,本文发现,在固定的预训练计算预算下,微调机制倾向于选择稍大的模型和稍小的epoch预算。直观上来说,更大的模型具有更大的容量,因此能够更好地适应新的任务。在某些情况下,稍大的学习率(在预训练期间)在微调后也能获得更好的性能
以上就是DeepMind:谁说卷积网络不如ViT?的详细内容,更多请关注其它相关文章!
# 工程
# 居然之家抖音推广营销思路
# 仪表东莞网站建设
# 中卫农产品网站优化
# 攸县营销推广网站招聘网
# 准营销推广乜云速捷甄选
# 社群营销推广员机制
# 重新启动
# 所示
# 在对
# 实现了
# 注意到
# 但在
# 进行了
# 最优
# 更大
# 谁说
# type
# convnets
# deepmind
# 浠水seo推广优势
# 公司建设网站费用预算
# 品牌推广整合营销
# shopee 查关键词排名
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
苹果16有哪些不同
夸克前缀后缀什么意思啊
联想手机如何输入命令行
买的5g手机但是没有5g网络怎么办
typescript怎么设置滚动条
为什么有的夸克带电
本科一批和本科二批是什么意思
typescript学多久可以学会
如何测固态硬盘芯片
新买的固态硬盘如何查
如何加装固态硬盘
excel中datediff函数怎么用
ai文件里无法找到链接文件要怎么解决步骤
如何打开命令提示符
vivo手机爱奇艺怎么投屏到电视操作步骤
如何通过命令行聊天
typescript入门要多久
如何使用程序编译 执行的命令
基金市盈率是什么意思
华为5g手机掉了怎么定位找回
typescript怎么解析vue TypeScript在vue中的使用最新解读
没基础做单片机怎么样
单片机程序负数怎么表示
新网站如何填写域名解析
显卡上面TYPE-C是什么接口
arp命令如何使用
为什么要用typescript6
充电器上的power是什么意思
typescript如何生成uuid
苹果16哪些型号好用
如何创建sql命令
交管12123协议头不完整怎么弄
linux如何跳回命令行界面
shell如何执行sql脚本命令行
一帧是多少秒
2026年将会大爆发的15个新科技
华为交换机 配置 如何复制命令行
solo交友软件怎么恢复聊天记录
夸克是什么用途
如何选择启用固态硬盘
typescript是什么时候出来的
360f4怎么取消百变壁纸
typescript怎么传json
三星固态硬盘如何保修
混合固态硬盘如何分区
dos命令如何复制目录结构
市盈率是负数是什么意思
5g手机4g卡怎么没有网络
春运抢票技巧攻略
如何安装笔记本固态硬盘
