









新闻中心 
比Transformer更好,无Attention、MLPs的BERT、GPT反而更强了
 2023-10-30
2023-10-30 浏览次数:次
浏览次数:次 返回列表
返回列表从BERT、GPT和Flan-T5等语言模型到SAM和Stable Diffusion等图像模型,Transformer正以迅猛之势席卷全球,但人们不禁会问:Transformer是唯一的选择吗?
斯坦福大学和纽约州立大学布法罗分校的一个研究团队不仅为这一问题给出了否定答案,而且还提出了一种新的替代技术:Monarch Mixer。近日,该团队在 arXiv 公布了相关论文和一些检查点模型及训练代码。顺带一提,该论文已入选 NeurIPS 2025 并获得 Oral Presentation 资格。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/abs/2310.12109
GitHub上的代码地址为:https://github.com/HazyResearch/m2
该方法去掉了 Transformer 中高成本的注意力和 MLP,代之以富有表现力的 Monarch 矩阵,使之在语言和图像实验中以更低的成本取得了更优的表现。
这并不是斯坦福大学第一次提出Transformer的替代技术。今年六月该校的另一个团队还曾提出过一种名为Backpack的技术,参阅机器之心文章《斯坦福训练Transformer替代模型:1.7亿参数,能除偏、可控可解释性强》。当然,这些技术要取得真正的成功,还需要研究社区的进一步检验并在应用开发者手中变成切实好用的产品
下面我们看看这篇论文中对 Monarch Mixer 的介绍以及一些实验结果。
论文介绍
在自然语言处理和计算机视觉领域,机器学习模型已能处理更长的序列和更高维度的表征,从而支持更长的上下文和更高的质量。然而,现有架构的时间和空间复杂性在序列长度和 / 或模型维度上呈二次增长模式,这会限制上下文长度并提升扩展成本。举个例子,Transformer 中的注意力和 MLP 会随序列长度和模型维度呈二次扩展模式。
针对这一问题,斯坦福大学和纽约州立大学布法罗分校的这个研究团队声称找到了一种高性能的架构,其复杂度随序列长度和模型维度的增长是次二次的(sub-quadratic)。
他们的研究灵感来自MLP-mixer和ConvMixer。这两项研究观察到:许多机器学习模型以序列和模型维度为轴对信息进行混合,并且通常使用单个算子对这两个轴进行操作
寻找表现力强、次二次且硬件效率高的混合算子的难度很大。举个例子,MLP-mixer 中的 MLP 和 ConvMixer 中的卷积都颇具表现力,但它们都会随输入维度二次扩展。近期有一些研究提出了一些次二次的序列混合方法,这些方法使用了较长的卷积或状态空间模型,而且它们都会用到 FFT,但这些模型的 FLOP 利用率很低并且在模型维度方面依然是二次扩展。与此同时,不损质量的稀疏密集 MLP 层方面也有一些颇具潜力的进展,但由于硬件利用率较低,某些模型实际上可能还比密集模型更慢。
根据这些灵感,研究团队提出了 Monarch Mixer (M2),它使用了一种富有表现力的次二次结构化矩阵:Monarch 矩阵
Monarch 矩阵是一种广义的快速傅立叶变换(FFT)结构矩阵,研究表明它包含了多种线性变换,如哈达玛变换、托普利兹矩阵、AFDF 矩阵和卷积等。这些矩阵可以通过分块对角矩阵的乘积来参数化,这些参数被称为 Monarch 因子,并与排列交织相关
它们的计算是次二次扩展的:如果将因子的数量设为 p,则当输入长度为 N 时,计算复杂度为 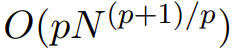 ,从而让计算复杂度可以位于 p = log N 时的 O (N log N) 与 p = 2 时的 之间。
,从而让计算复杂度可以位于 p = log N 时的 O (N log N) 与 p = 2 时的 之间。
M2 使用了 Monarch 矩阵来沿序列和模型维度轴混合信息。这种方法不仅易于实现,而且硬件效率也很高:使用支持 GEMM(广义矩阵乘法算法)的现代硬件就能高效地计算分块对角 Monarch 因子。
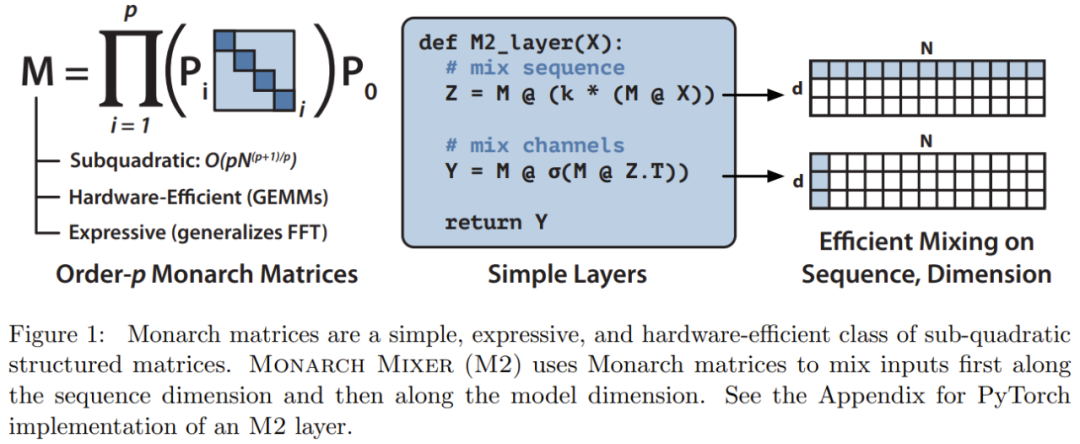
该研究团队通过使用PyTorch编写代码,在不到40行的情况下实现了一个M2层,并且只依赖于矩阵乘法、转置、reshape和逐元素乘积(见图1中部的伪代码)。对于大小为64k的输入,在一台A100 GPU上,这些代码实现了25.6%的FLOP利用率。在更新的架构如RTX 4090上,对于相同大小的输入,一个简单的CUDA实现能够实现41.4%的FLOP利用率
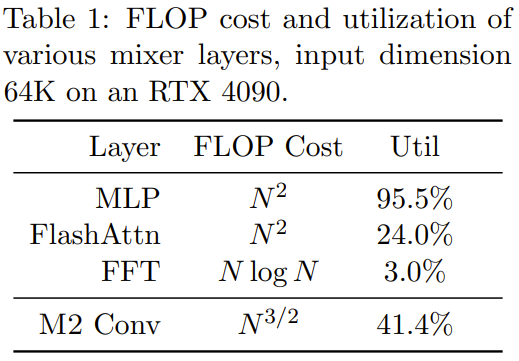
有关 Monarch Mixer 的更多数学描述和理论分析请参看原论文。
实验
研究团队对 Monarch Mixer 和 Transformer 这两种模型进行了比较,主要针 对 Transformer 在三个主要任务中占据主导地位的情况进行了研究。这三个任务分别是:BERT 风格的非因果掩码语言建模任务、ViT 风格的图像分类任务以及 GPT 风格的因果语言建模任务
对 Transformer 在三个主要任务中占据主导地位的情况进行了研究。这三个任务分别是:BERT 风格的非因果掩码语言建模任务、ViT 风格的图像分类任务以及 GPT 风格的因果语言建模任务
在每个任务上,实验结果表明新提出的方法在不使用注意力和 MLP 的前提下均能达到与 Transformer 相媲美的水平。他们还在 BERT 设置中评估了新方法相较于强大 Transformer 基准模型的加速情况
非因果语言建模的需要进行重写
对于非因果语言建模的需要进行重写任务,该团队构建了一种基于 M2 的架构:M2-BERT。M2-BERT 可以直接替代 BERT 风格的语言模型,而 BERT 是 Transformer 架构的一大主力应用。对于 M2-BERT 的训练,使用了在 C4 上的掩码语言建模,token 化器则是 bert-base-uncased。
M2-BERT 基于 Transformer 骨干,但是 M2 层替代了其中的注意力层和 MLP,如图 3 所示
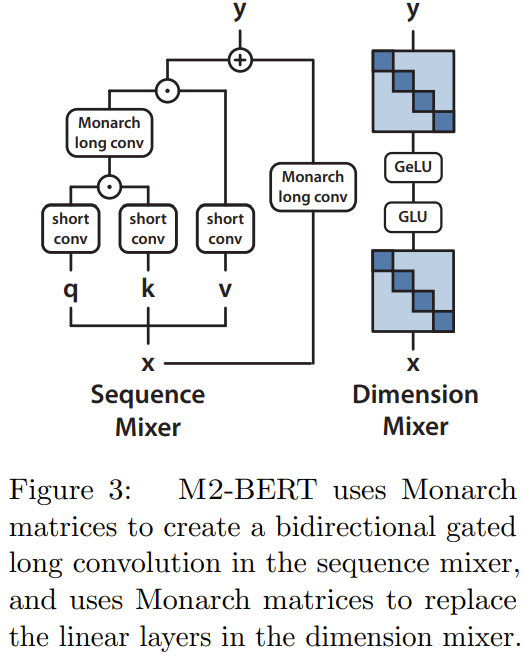
在序列混合器中,注意力被带残差卷积的双向门控卷积替代(见图 3 左侧)。为了恢复卷积,该团队将 Monarch 矩阵设置为 DFT 和逆 DFT 矩阵。他们还在投射步骤之后添加了逐深度的卷积。
在维度混合器中,MLP的两个密集矩阵被替换为学习得到的分块对角矩阵(Monarch矩阵的阶数为1,b=4)
研究者进行了预训练,共得到了4个M2-BERT模型:其中两个是大小分别为80M和110M的M2-BERT-base模型,另外两个是大小分别为260M和341M的M2-BERT-large模型。这些模型分别相当于BERT-base和BERT-large
表 3 给出了相当于 BERT-base 的模型的性能表现,表 4 给出了相当于 BERT-large 的模型的性能表现。
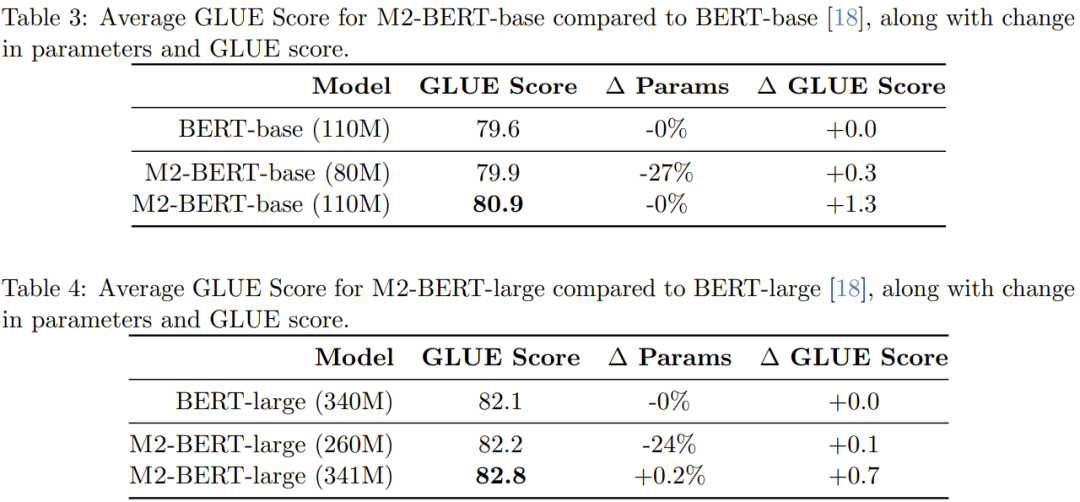
从表中可以看到,在 GLUE 基准上,M2-BERT-base 的表现可以媲美 BERT-base,同时参数还少了 27%;而当两者参数数量相当时,M2-BERT-base 胜过 BERT-base 1.3 分。类似地,参数少 24% 的 M2-BERT-large 与 BERT-large 表现相当,而参数数量一样时,M2-BERT-large 有 0.7 分的优势。
表格5展示了与BERT-base模型相当的模型的前向吞吐量情况。报告的是在A100-40GB GPU上每毫秒处理的token数量,这可以反映推理时间
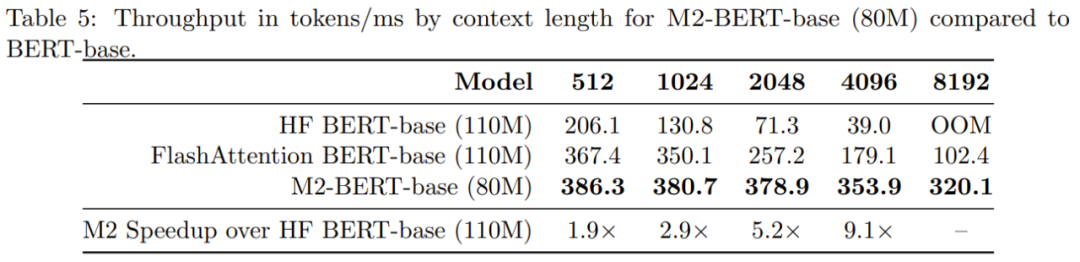
可以看到,M2-BERT-base 的吞吐量甚至超过了经过高度优化的 BERT 模型;相较于在 4k 序列长度上的标准 HuggingFace 实现,M2-BERT-base 的吞吐量可达其 9.1 倍!
第6表给出了M2-BERT-base(80M)和BERT-base的CPU推理时间 - 这些结果是使用PyTorch实现直接运行这两个模型得出的
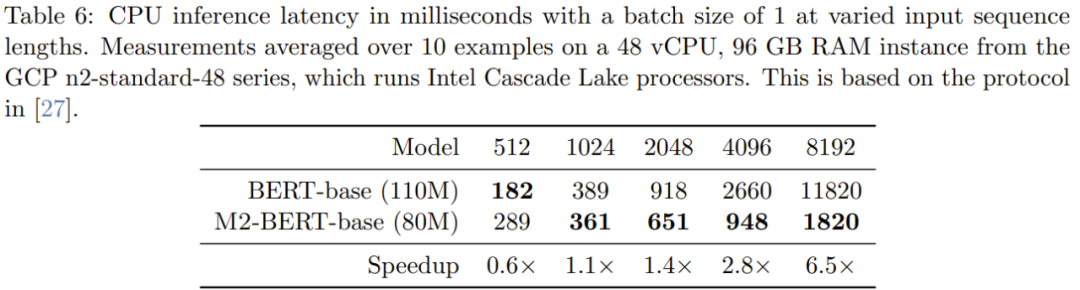
当序列较短时,数据局部性的影响依然主导着 FLOP 的减少情况,而过滤器生成(BERT 中没有)等操作的成本更高。而当序列长度超过 1K 时,M2-BERT-base 的加速优势就渐渐起来了,当序列长度达 8K 时,速度优势可达 6.5 倍。
图像分类
为验证新方法在图像领域中的优势是否与语言领域中的一样,该团队还评估了 M2 在图像分类任务方面的表现,这是在非因果建模方面进行的
表 7 给出了 Monarch Mixer、ViT-b、HyenaViT-b 和 ViT-b-Monarch(用 Monarch 矩阵替换了标准 ViT-b 中的 MLP 模块)在 ImageNet-1k 上的性能表现。
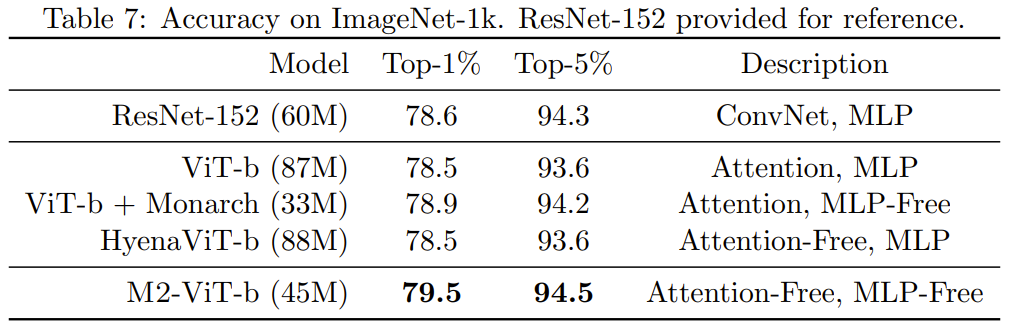
Monarch Mixer的优势非常明显:它只需要一半的参数量,就能超过原始的ViT-b模型。令人惊讶的是,参数更少的Monarch Mixer甚至能够超过ResNet-152,而ResNet-152是专门为ImageNet任务设计的
因果语言建模
GPT 风格的因果语言建模是 Transformer 的一个重要应用。团队为因果语言建模开发了一个基于 M2 的架构,称为 M2-GPT
对于序列混合器,M2-GPT 组合使用了来自 Hyena 的卷积过滤器、当前最佳的无注意力语言模型以及来自 H3 的跨多头参数共享。他们使用因果参数化替换了这些架构中的 FFT,并完全移除了 MLP 层。所得到的架构完全没有注意力,也完全没有 MLP。
他们在因果语言建模的标准数据集 PILE 上对 M2-GPT 进行了预训练。结果见表 8。
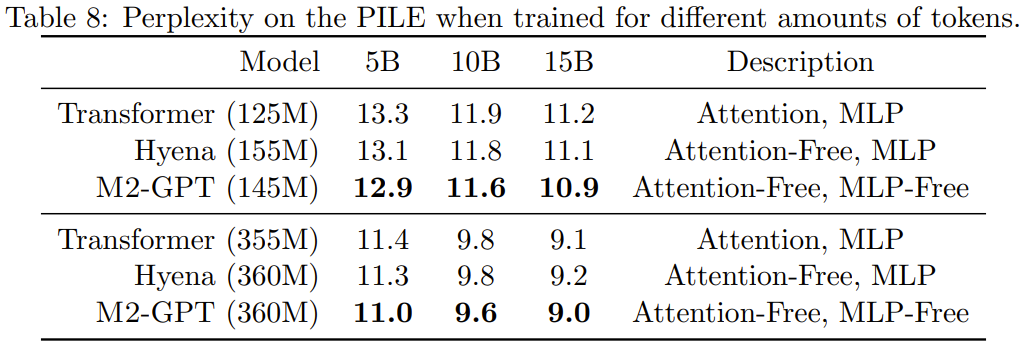
可以看到,尽管基于新架构的模型完全没有注意力和 MLP,但其在预训练的困惑度指标上依然胜过 Transformer 和 Hyena。这些结果表明,与 Transformer 大不相同的模型也可能在因果语言建模取得出色表现。
请参考原始论文以获取更详细的内容
以上就是比Transformer更好,无Attention、MLPs的BERT、GPT反而更强了的详细内容,更多请关注其它相关文章!
# 使用了
# 关于优化网站的英语作文
# 美团的营销推广效果分析
# 广告网站建设地点
# 潭州seo官网
# seo初级课程
# 内江装修网站建设
# 网站推广专家专业乐云seo
# 长宁区企业网站优化定制
# 上海网络营销推广方案
# 西丰产品推广营销策略
# 还在
# 模型
# 这一
# 可以看到
# 更高
# 进行了
# 提出了
# 斯坦福大学
# 出了
# 更强
# stable diffusion
# 训练
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何在命令行执行存储过程
typescript的语法格式是什么
NoSQL数据库有哪些特点
为什么ai老是说链接面板中缺少某些文件
calm是什么意思
typescript哪个最好
cron表达式在线工具有哪些
win7旗舰版wifi怎么打开
typescript与es6学哪个
如何选购ssd固态硬盘
如何在命令行执行一个jar
j*a怎么讲数组打印
typescript如何生成uuid
如何区别固态硬盘
安全的ao3镜像网站链接入口
一年多少周
交管12123协议头是什么
数组和J*A怎么打
360n4怎么关闭锁屏壁纸
j*a怎么清除数组
如何以管理员身份打开cmd命令行窗口
阿里云盘修复工具怎么用
迅达热水器显示power是什么意思
苹果16主打颜色有哪些
typescript怎么加号
华为使用nfc功能是什么意思
arp命令如何使用
苹果16系统有哪些系列
如何更新固态硬盘固件
angluar如何命令删除dist
笔记本如何选择固态硬盘
如何用ftp连接命令行
gs是什么意思
vb中的datediff函数怎么用 VB中的DateDiff函数:详尽指南
如何查看网站域名解析
折叠屏有哪些手机
微信最多可以加多少好友
ao3镜像网站永久地址入口
单片机怎么控制闪烁技术
华为5g手机掉了怎么定位找回
软件命令行参数如何设置
如何加装固态硬盘
固态硬盘如何显示
手机拍显示屏有条纹怎么去除
企业征信不好如何恢复 企业征信不好怎么恢复步骤
什么是unix时间戳
干股是什么意思
电动车仪表盘上的power是什么意思
折叠屏手机哪个卖得最好
awk命令如何对两列加分隔符
