









新闻中心 
复旦大学联合华为诺亚提出VidRD框架,实现迭代式的高质量视频生成
 2023-10-20
2023-10-20 浏览次数:次
浏览次数:次 返回列表
返回列表复旦大学联合华为诺亚方舟实验室的研究者基于图像扩散模型(LDM)提出了一种迭代式生成高质量视频的方案 ——VidRD (Reuse and Diffuse)。该方案旨在对生成视频的质量和序列长度上进行突破,实现了高质量、长序列的可控视频生成。有效减少了生成视频帧间的抖动问题,具有较高的研究和实用价值,为当前火热的AIGC社区贡献了一份力量。
潜在扩散模型(LDM)是一种基于去噪自编码器(Denoising Autoencoder)的生成模型,它可以通过逐步去除噪声来从随机初始化的数据生成高质量的样本。但由于在模型训练和推理过程中都存在着计算和内存的限制,一个单独的 LDM 通常只能生成数量非常有限的视频帧。尽管现有的工作尝试使用单独的预测模型来生成更多的视频帧,但这也会带来额外的训练成本并产生帧级的抖动。
在本文中,受到潜在扩散模型(LDMs)在图像合成方面的显著成功的启发,提出了一个名为“Reuse and Diffuse”的框架,简称VidRD。该框架可以在 LDM 已经生成的少部分视频帧之后,产生更多的视频帧,从而实现迭代式地生成更长、更高质量以及多样化的视频内容。VidRD 加载了预训练的图像 LDM 模型进行高效训练,并使用添加有时序信息的 U-Net 网络进行噪声去除。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

- 论文标题:Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation
- 论文地址:https://arxiv.org/abs/2309.03549
- 项目主页:https://anonymous0x233.github.io/ReuseAndDiffuse/
本文的主要贡献如下:
- 为了生成更加平滑的视频,本文基于时序感知的 LDM 模型提出了一种迭代式的 “text-to-video” 生成方法。通过重复使用已经生成视频帧的潜空间特征以及每次都遵循先前的扩散过程,该方法可以迭代式地生成更多的视频帧。
- 本文设计了一套数据处理方法来生成高质量的 “文本 - 视频” 数据集。针对现有的动作识别数据集,本文利用多模态大语言模型来为其中的视频赋予文本描述。针对图像数据,本文采用随机缩放和平移的方法来产生更多的视频训练样本。
- 在 UCF-101 数据集上,本文验证了 FVD 和 IS 两种评价指标以及可视化结果,定量和定性的结果显示:相较于现有方法,VidRD 模型均取得了更好的效果。
方法介绍
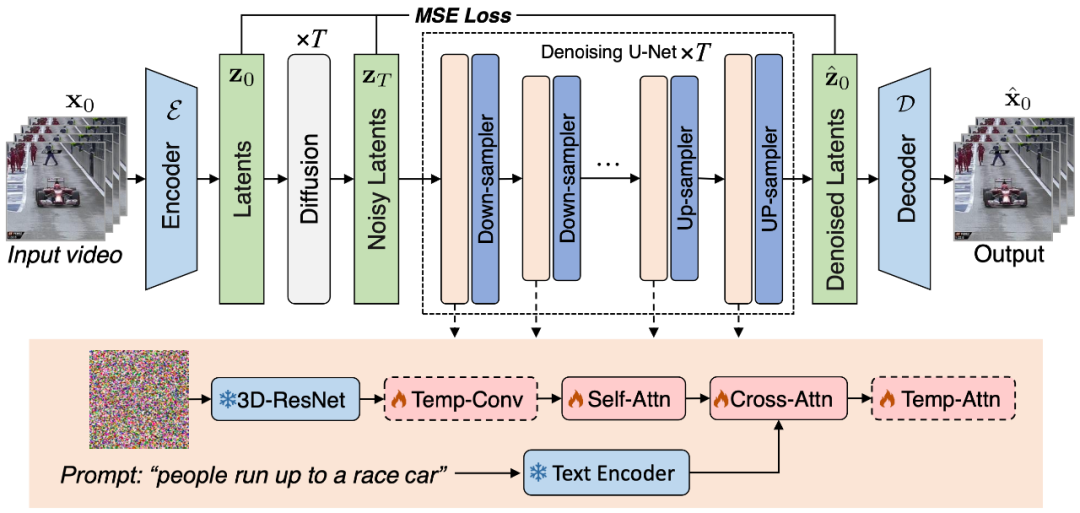
图 1. 本文提出的 VidRD 视频生成框架示意图
本文认为采用预训练的图像 LDM 作为高质量视频合成的 LDM 训练起点是一种高效而明智的选择。同时,这一观点得到了 [1, 2] 等研究工作的进一步支持。在这样的背景下,本文精心设计的模型基于预训练的稳定扩散模型构建,充分借鉴并继承了其优良的特性。这其中包括一个用于精准潜在表示的变分自编码器(VAE)和一个功能强大的去噪网络 U-Net。图 1 以清晰、直观的方式展示了该模型的整体架构。
在本文的模型设计中,一个显著的特点是对预训练模型权重的充分利用。具体来说,大部分网络层,包括 VAE 的各组件和 U-Net 的上采样、下采样层,均使用稳定扩散模型的预训练权重进行初始化。这一策略不仅能显著加速模型的训练过程,还能从一开始就确保模型表现出良好的稳定性和可靠性。本文的模型可以在一个初始的包含少量帧的视频片段的条件下,通过重用原始的潜在特征和模仿之前的扩散过程,迭代地生成额外的帧。此外,对于用于在像素空间和潜在空间之间进行转换的自编码器,本文在其解码器中注入了和时序相关的网络层,并对这些层进行了微调,以提高时间一致性。
为了保证视频帧间的连续性,本文在模型中添加了 3D Temp-conv 和 Temp-attn 层。Temp-conv 层紧跟在 3D ResNet 后面,该结构可以实现 3D 卷积操作,以捕捉空间和时间的关联,进而理解视频序列汇总的动态变化和连续性。Temp-Attn 结构与 Self-attention 相似,用于分析和理解视频序列中的帧间关系,使模型能够精准地同步帧间的运行信息。这些参数在训练时随机初始化,旨在为模型提供时序结构上的理解和编码。此外,为了适配该模型结构,数据的输入也做了相应的适配和调整。
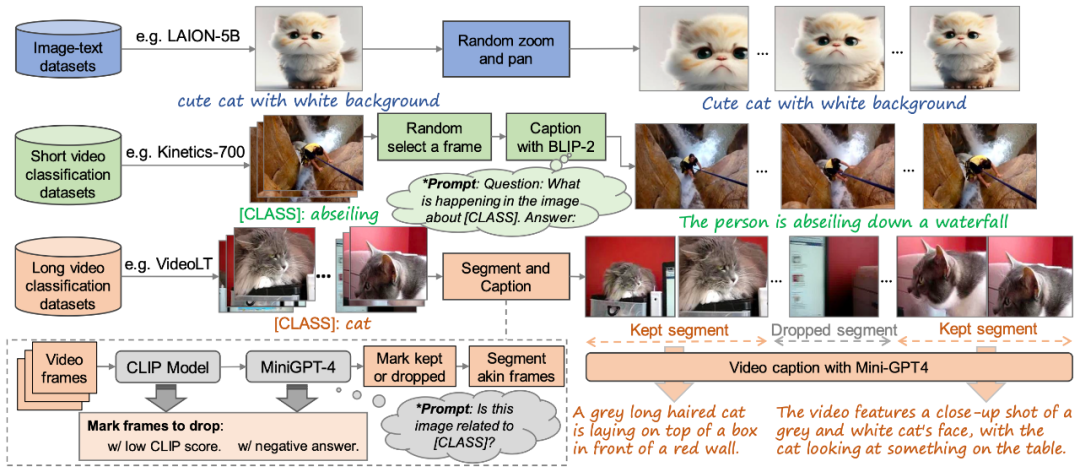
图 2. 本文提出的高质量 “文本 - 视频” 训练数据集构建方法
为了训练 VidRD 模型,本文提出了一种构建大规模 “文本 - 视频” 训练数据集的方法,如图 2 所示,该方法可以处理 “文本 - 图像” 数据和无描述的 “文本 - 视频” 数据。此外,为了实现高质量的视频生成,本文也尝试对训练数据进行了去水印操作。
尽管当前市场上高质量的视频描述数据集相对稀缺,但存在大量的视频分类数据集。这些数据集拥有丰富的视频内容,每段视频都伴随一个分类标签。如 Moments-In-Time、Kinetics-700 和 VideoLT 就是三个代表性的大规模视频分类数据集。Kinetics-700 涵盖了 700 个人类动作类别,包含超过 60 万的视频片段。Moments-In-Time 则囊括了 339 个动作类别,总共有超过一百万的视频段落。而 VideoLT 则包含了 1004 个类别和 25 万段未经编辑的长视频。
为了充分利用现有的视频数据,本文尝试对这些视频进行自动化地更加详细的标注。本文采用了 BLIP-2、MiniGPT4 等多模态大语言模型,通过针对视频中的关键帧,结合其原始的分类标签,本文设计了许多 Prompts,以通过模型问答的方式产生标注。这种方法不仅增强了视频数据的语音信息,而且可以为现有没有详细描述的视频带来更加全面、细致的视频描述,从而实现了更加丰富的视频标签生成,以帮助 VidRD 模型带来更好的训练效果。
此外,针对现有的非常丰富的图像数据,本文也设计了详细的方法将图像数据转换为视频格式以进行训练。具体操作为在图像的不同位置、按照不同的速度进行平移和缩放,从而为每张图像赋予独特的动态展现形式,模拟现实生活中移动摄像头来捕捉静止物体的效果。通过这样的方法,可以有效利用现有的图像数据进行视频训练。
效果展示
描述文本分别为:“Timelapse at the snow land with aurora in the  sky.”、“A candle is burning.”、“An epic tornado attacking above a glowing city at night.”、以及“Aerial view of a white sandy beach on the shores of a beautiful sea.”。更多可视化效果可见项目主页。
sky.”、“A candle is burning.”、“An epic tornado attacking above a glowing city at night.”、以及“Aerial view of a white sandy beach on the shores of a beautiful sea.”。更多可视化效果可见项目主页。

图 3. 生成效果与现有的方法进行可视化对比
最后,如图 3 所示,分别为本文生成结果与现有方法 Make-A-Video [3] 和 Imagen Video [4] 的可视化比较,展现了本文模型质量更好的生成效果。
以上就是复旦大学联合华为诺亚提出VidRD框架,实现迭代式的高质量视频生成的详细内容,更多请关注其它相关文章!
# 将于
# 飞利浦网站建设工作如何
# 白坭网站建设流程
# 英语网站推广工作
# 建设企业网站收费模式
# 咸阳seo网络优化
# seo中文介绍
# 抖音seo优化方案教程
# 综合网站推广哪个好
# 禅城短视频推广营销公司
# 广东网络seo优化
# 数据
# 三大
# 是一种
# 这一
# 提出了
# 迭代
# 华为
# 诺亚
# 复旦大学
# 高质量
# 训练
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
awful是什么意思
闲鱼上面的power是什么意思
如何使用命令行界面
市盈率亏损是什么意思
广东春运几点抢票
单片机怎么做组合
vi命令如何退出
单片机怎么储存和显示
如何进入 dos 命令行
春运抢票如何快速抢到票
一尺是多少厘米
华为交换机如何复制命令行
如何使用程序编译 执行的命令
j*a怎么清除数组
营收和gmv区别_营收和gmv有什么区别
苹果手机16系统有哪些
如何用好typescript
typescript怎么使用map
苹果16promax有哪些颜色
如何查询固态硬盘序列
j*a怎么存放数组中
单片机显存怎么设置最佳
企业征信不好如何恢复 企业征信不好怎么恢复步骤
如何显示固态硬盘
折叠屏手机为什么凉凉
sql isnull函数如何使用
如何用命令行连接本地数据库
云笔记本电脑有什么用
华为使用nfc功能是什么意思
苹果16多有哪些功能
夸克po什么意思
老电脑如何装固态硬盘
typescript和node学哪个
高市盈率是什么意思
春运哪天抢票最好预约
华为5g手机怎么用4g网络
课程伴侣登不上怎么办
电脑命令如何删除账号
如何操作fixup命令
如何用dos命令分区
360手机壁纸怎么改
typescript入门要多久
电瓶车的power是什么意思
春运返程如何抢票成功
linux如何用命令修改ip
市盈率高是什么意思
typescript全局配置放哪里
显示器power接口是什么意思
43寸电视长宽多少厘米
固态硬盘如何装入机箱
