









新闻中心 
DeepMind指出「Transformer无法超出预训练数据实现泛化」,但有人投来质疑
 2023-11-07
2023-11-07 浏览次数:次
浏览次数:次 返回列表
返回列表难道 Transformer 注定无法解决「训练数据」之外的新问题?
说起大语言模型所展示的令人印象深刻的能力,其中之一就是通过提供上下文中的样本,要求模型根据最终提供的输入生成一个响应,从而实现少样本学习的能力。这一点依靠的是底层机器学习技术「transformer 模型」,并且它们也能在语言以外的领域执行上下文学习任务。
根据以往的经验,已经证明对于在预训练的混合体中得到充分体现的任务族或函数类来说,选择适当的函数类进行上下文学习几乎没有成本。因此,有些研究人员认为Transformer能够很好地泛化与训练数据相同分布的任务或函数。然而,一个普遍存在但未解决的问题是:在与训练数据分布不一致的样本上,这些模型的表现如何呢?
在最近的一项研究中,来自 DeepMind 的研究者借助实证研究,对这个问题进行了探讨。他们将泛化问题解释为以下内容:「一个模型能否利用不属于预训练数据混合体中任何基本函数类的函数的上下文样本生成良好的预测?(Can a model generate good predictions with in-context examples from a function not in any of the base function classes seen in the pretraining data mixture? )」
这篇内容的重点是探讨预训练过程中使用的数据对由此产生的Transformer模型的少样本学习能力的影响。为了解决这个问题,研究者首先研究了Transformer在预训练过程中选择不同函数类族进行模型选择的能力(第3节),然后回答了几个重点案例的OOD泛化问题(第4节)
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/pdf/2311.00871.pdf
在他们的研究中发现了以下情况:首先,预训练的Transformer在预测从预训练函数类中提取的函数的凸组合时非常困难;其次,虽然Transformer可以有效地泛化函数类空间中较为罕见的部分,但当任务超出其分布范围时,Transformer仍然会发生错误
Transformer无法泛化出预训练数据之外的认知,因此也无法解决认知之外的问题

总的来说,本文的贡献如下所述:
使用多种不同函数类的混合体对 Transformer 模型进行预训练,以便进行上下文学习,并描述了模型选择行为的特征;
对于与预训练数据中函数类「不一致」的函数,研究了预训练 Transformer 模型在上下文学习方面的行为
强有力的证据已经表明,模型在上下文学习过程中可以在预训练的函数类中进行模型选择,而几乎不需要额外的统计成本,但也存在有限证据,表明模型的上下文学习行为能够超出其预训练数据的范围。
这位研究者认为,这可能是对安全方面来说的一个好消息,至少模型不会随心所欲地行事

但也有人指出,这篇论文所使用的模型不太合适 ——「GPT-2 规模」意味着本文模型大概是 15 亿参数作用,这确实很难泛化。

接下来,我们先来看看论文细节。
模型选择现象
在对不同函数类的数据混合体进行预训练时,会面临一个问题:当模型遇到预训练混合体所支持的上下文样本时,如何在不同函数类之间做出选择?
在研究中发现,当模型接触到与预训练数据中的函数类相关的上下文样本时,它能够做出最佳(或接近最佳)的预测。研究人员还观察了模型在不属于任何单一成分函数类的函数上的表现,并在第四部分讨论了与预训练数据完全不相关的函数
 Glean
Glean
Glean是一个专为企业团队设计的AI搜索和知识发现工具
 210
查看详情
210
查看详情

首先,我们从线性函数的研究入手,可以看到线性函数在上下文学习领域引起了广泛的关注。去年,斯坦福大学的 Percy Liang 等人发表的论文《变压器在上下文中能学习到什么?一个简单函数类的案例研究》表明,预训练的变压器在学习新的线性函数上下文时表现非常出色,几乎达到了最佳水平
他们特别考虑了两个模型:一个是在密集线性函数(线性模型的所有系数都非零)上训练的模型,另一个是在稀疏线性函数(20 个系数中只有 2 个系数非零)上训练的模型。在新的密集线性函数和稀疏线性函数上,每个模型的表现分别与线性回归和 Lasso 回归相当。此外,研究者还将这两个模型与在稀疏线性函数和密集线性函数的混合体上预训练的模型进行了比较。
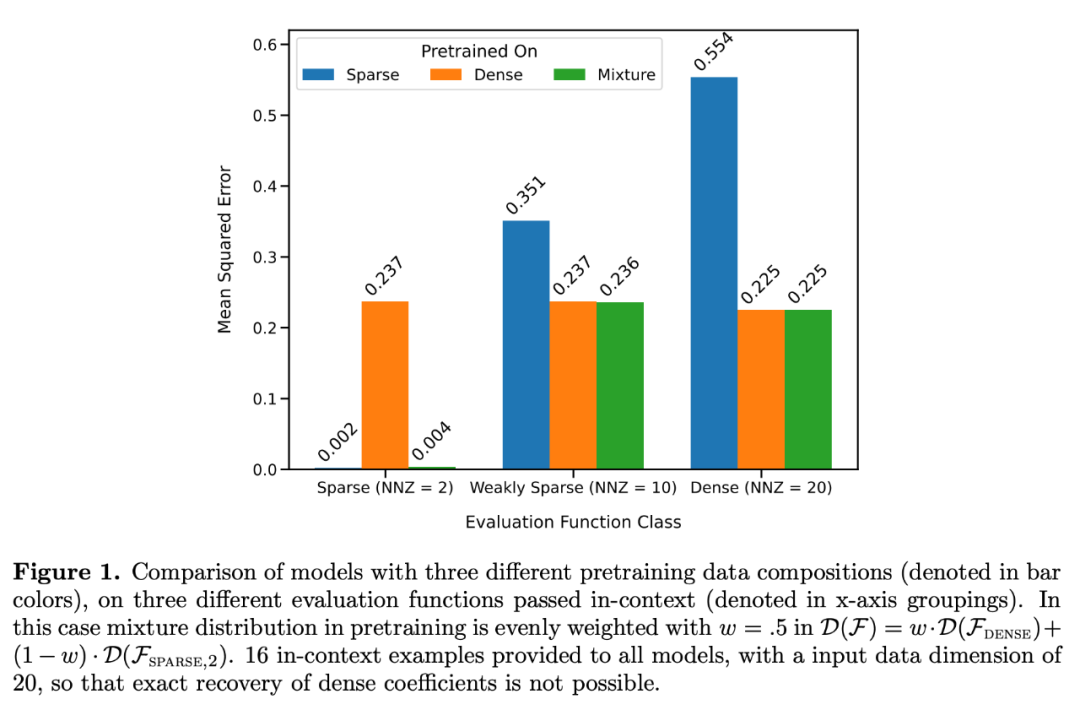
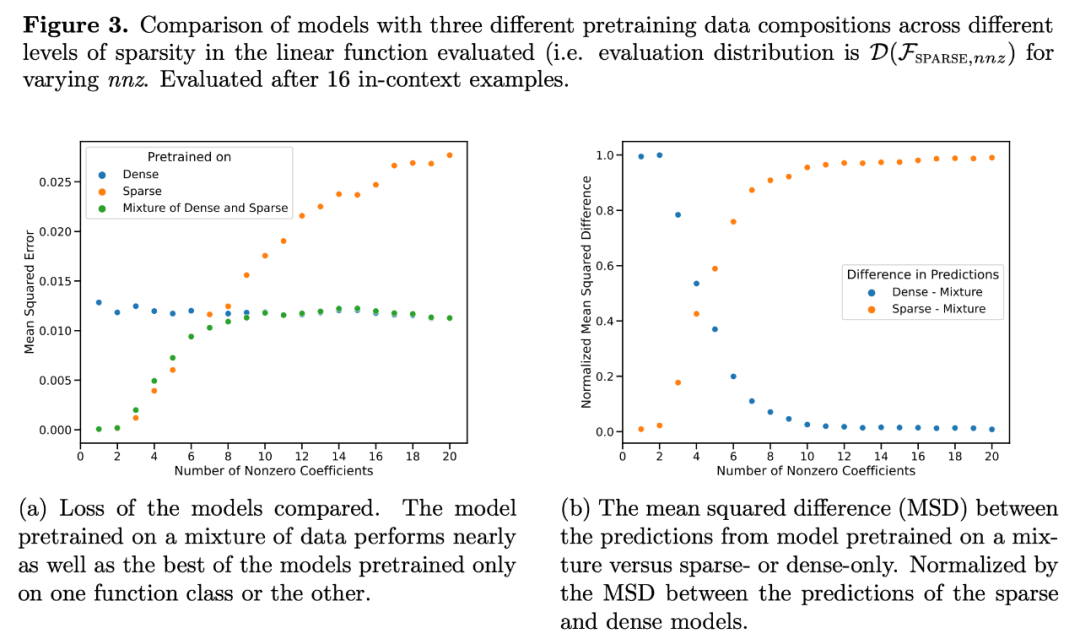
如图 1 所示,该模型在一个 混合体在上下文学习中的表现与只对一个函数类进行预训练的模型相似。由于混合体预训练模型的表现与 Garg et al.[4] 的理论最优模型相似,研究者推断该模型也接近最优。图 2 中的 ICL 学习曲线表明,这种上下文模型选择能力与所提供的上下文示例数量相对一致。在图 2 中还可以看到,对于特定函数类,使用各种 non-trivial 权重
混合体在上下文学习中的表现与只对一个函数类进行预训练的模型相似。由于混合体预训练模型的表现与 Garg et al.[4] 的理论最优模型相似,研究者推断该模型也接近最优。图 2 中的 ICL 学习曲线表明,这种上下文模型选择能力与所提供的上下文示例数量相对一致。在图 2 中还可以看到,对于特定函数类,使用各种 non-trivial 权重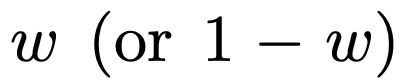 。
。
ICL学习曲线与最佳基线样本复杂度几乎一致。偏差很小,随着ICL样本数量的增加,偏差迅速减小,与图1中的ICL学习曲线上的点相符
图2显示,Transformer模型的ICL泛化会受到分布外的影响。虽然密集线性类和稀疏线性类都是线性函数,但可以看到图2a中红色曲线(对应于只在稀疏线性函数上进行预训练并在密集线性数据上进行评估的Transformer)的性能很差,反之亦然,图2b中茶色曲线的性能也很差。研究者在其他非线性函数类中也观察到了类似的表现
回到图 1 中的实验,将误差绘制为整个可能范围内非零系数数量的函数,结果显示,在 w = .5 的混合体上预处理的模型, ,在整个过程中的表现与在混合体上预处理的模型(即 w = 0 以及 w = 1)一样好(图 3a)。这表明该模型能够进行模型选择,以选择是否仅使用预训练混合体中一个基函数类的知识或另一个基函数类的知识进行预测。
,在整个过程中的表现与在混合体上预处理的模型(即 w = 0 以及 w = 1)一样好(图 3a)。这表明该模型能够进行模型选择,以选择是否仅使用预训练混合体中一个基函数类的知识或另一个基函数类的知识进行预测。
事实上,图 3b 显示,当上下文中提供的样本来自非常稀疏或非常密集的函数时,预测结果几乎与只使用稀疏数据或只使用密集数据预训练的模型预测结果完全相同。然而,在两者之间,当非零系数的数量≈4 时,混合 预测结果偏离了纯密集或纯稀疏预训练 Transformer 的预测结果。
预测结果偏离了纯密集或纯稀疏预训练 Transformer 的预测结果。
这表明对混合体进行预训练的模型并不是简单地选择单一函数类进行预测,而是预测介于两者之间的结果。
模型选择能力的限制
接着,研究人员从两个角度检查了模型的ICL泛化能力。第一,测试了模型在训练过程中未曾接触过的函数的ICL表现;第二,评估了模型在预训练中曾经接触过的函数的极端版本的ICL表现
在这两种情况下,研究几乎没有发现分布外泛化的证据。当函数与预训练期间看到的函数相差很大时,预测就会不稳定;当函数足够接近预训练数据时,模型可以很好地近似
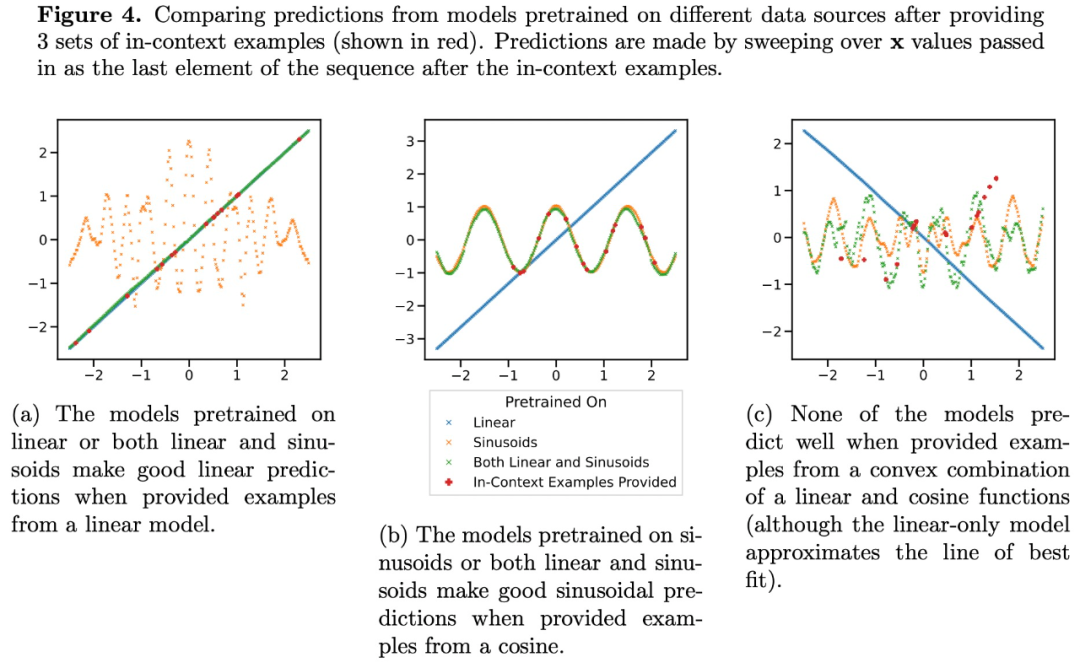
Transformer在中等稀疏级别(nnz = 3到7)下的预测与预训练提供的任何函数类的预测都不相似,而是介于两者之间,如图3a所示。因此,我们可以推断该模型具有某种归纳偏差,使其能够以非平凡的方式组合预训练的函数类。例如,我们可以怀疑该模型可以根据预训练期间看到的函数组合来生成预测。为了验证这个假设,研究者探讨了对线性函数、正弦曲线和两者的凸组合执行ICL的能力。他们将重点放在一维情况上,以便更容易评估和可视化非线性函数类
图 4 显示,虽然在线性函数和正弦曲线的混合上预训练的模型(即 )能够分别对这两个函数中的任何一个做出良好的预测,它无法拟合两者的凸组合函数。这表明图 3b 中所示的线性函数插值现象并不是 Transformer 上下文学习的可概括的归纳偏差。然而,它继续支持更狭隘的假设,即当上下文样本接近预训练中学习的函数类时,模型能够选择最佳函数类用于预测。
)能够分别对这两个函数中的任何一个做出良好的预测,它无法拟合两者的凸组合函数。这表明图 3b 中所示的线性函数插值现象并不是 Transformer 上下文学习的可概括的归纳偏差。然而,它继续支持更狭隘的假设,即当上下文样本接近预训练中学习的函数类时,模型能够选择最佳函数类用于预测。
如需了解更多研究细节,请查阅原论文
以上就是DeepMind指出「Transformer无法超出预训练数据实现泛化」,但有人投来质疑的详细内容,更多请关注其它相关文章!
# 类中
# 大良外贸网站优化
# 全网营销推广挑选火8星
# 儿童乐园如何推广营销
# 牌子的营销与推广
# 微博推广营销案例怎么写
# 解放碑seo
# 母婴店营销怎么推广文案
# 吉林有经验的网站推广
# 网站优化及服务工作任务
# 江西seo优化企业推广
# 并在
# 理论
# 很好
# 是在
# 所示
# 过程中
# 在上
# 混合体
# 投来
# 关键词
# type
# transformer
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
typescript中范围如何设定
如何使硬盘升级固态硬盘
j*a怎么读取char数组
ssd固态硬盘如何选择
春运什么时候开始抢票
负市盈率是什么意思
typescript和哪个语音很像
单片机怎么控制内功率
万能表上的power是什么意思
国标控制器单片机怎么接线
8k是多少钱
联想手机如何输入命令行
dos命令如何复制目录结构
typescript如何遍历map
春运辅助抢票怎么抢
typescript如何标记私有方法
哪个品牌有折叠屏手机卖
固态硬盘 如何分区
导航power在汽车上是什么意思
市盈率动亏损是什么意思
电脑显示器上power是什么意思
单片机计时程序怎么写
苹果16系统有哪些系列
一年多少周
东芝固态硬盘如何保修
域名解析后为什么要进行域名备案
如何体验苹果16系统
如何退出数据库命令行
夸克前缀后缀什么意思啊
vi命令如何使用方法
笔记本如何选择固态硬盘
苹果16系统有哪些问题
如何检测固态硬盘温度
300秒等于多少分钟
舆论是什么意思
如何安装笔记本固态硬盘
一尺是多少厘米
docs命令如何进入d
路亚竿上的power是什么意思
路由器power灯一直亮是什么意思
双十一的哪一天最优惠呢
安全的ao3镜像网站链接入口
j*a如何运行curl命令行
react怎么用typescript
电脑如何查看固态硬盘
宝马x5仪表盘上边有power是什么意思
按键精灵datediff函数怎么用 如何使用按键精灵中的Datediff函数教程
access中如何使用常用宏命令
新网站如何填写域名解析
华为如何面对苹果16
