









新闻中心 
7.7亿参数,超越5400亿PaLM!UW谷歌提出「分步蒸馏」,只需80%训练数据|ACL 2025
 2023-10-07
2023-10-07 浏览次数:次
浏览次数:次 返回列表
返回列表大型语言模型在性能方面表现出色,能够通过零样本或少样本提示来解决新任务。然而,在实际应用部署中,LLM却不太实用,因为它的内存利用效率低,同时需要大量的计算资源
比如运行一个1750亿参数的语言模型服务至少需要350GB的显存,而目前最先进的语言模型大多已超过5000亿参数量,很多研究团队都没有足够的资源来运行,在现实应用中也无法满足低延迟性能。
也有一些研究使用人工标注数据或使用LLM生成的标签进行蒸馏来训练较小的、任务专用的模型,不过微调和蒸馏需要大量的训练数据才能实现与LLM相当的性能。
为了解决大型模型对资源的需求问题,华盛顿大学与谷歌合作提出了一种名为「分步蒸馏」(Distilling Step-by-Step)的新蒸馏机制。通过分步蒸馏,经过蒸馏后的模型尺寸相较于原模型来说更小,但性能却更优,而且在微调和蒸馏过程中所需的训练数据也更少
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

请点击以下链接查看论文:https://arxiv.org/abs/2305.02301
分布蒸馏机制把LLM中抽取出的预测理由(rationale)作为在多任务框架内训练小模型的额外监督信息。
经过在4个NLP基准上进行实验后,我们发现:
1. 与微调和蒸馏相比,该机制用更少的训练样本实现了更好的性能;
相较于少样本提示LLM,该机制利用更小尺寸的模型实现了更出色的性能
3. 同时降低模型尺寸和数据量也可以实现优于LLM的性能。
实验中,微调后770M的T5模型在基准测试中仅使用80%的可用数据就优于少样本提示的540B的PaLM模型,而标准微调相同的T5模型即使使用100%的数据集也难以匹配。
蒸馏方法
分布蒸馏的关键思想是逐步抽取出信息丰富且用自然语言描述的预测理由,即中间推理步骤,以解释输入问题与模型输出之间的联系,并通过这些数据来更高效地训练小模型
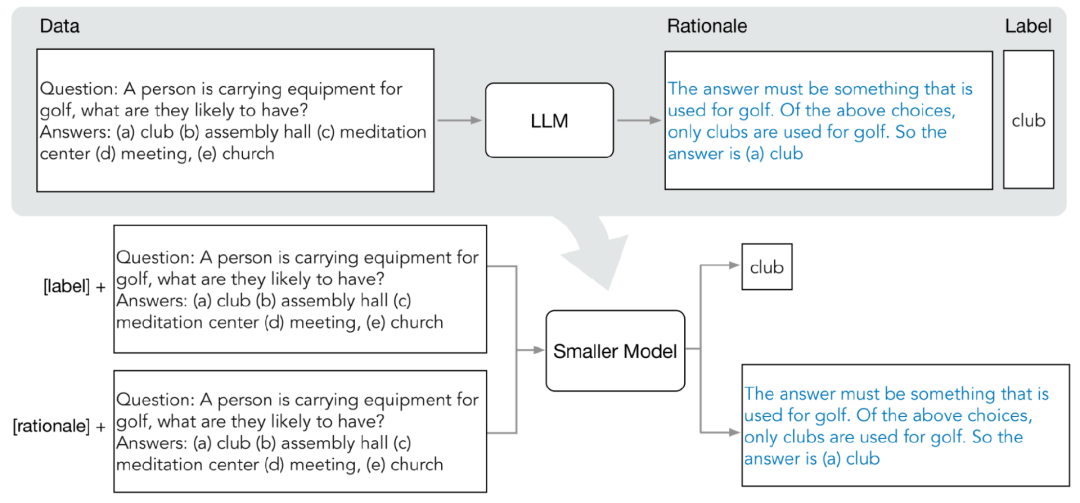
分布蒸馏主要包括两个阶段:
1. 从LLM中提取原理(rationale)
研究人员利用少样本思维链(CoT)提示从LLM中提取预测中间步骤。
在确定目标任务之后,首先在LLM输入提示中准备几个样例。每个样例都由一个三元组组成,包括输入、原理和输出

输入提示后,LLM能够模仿三元组演示以生成其他新问题的预测原理,例如,在常识问答案任务中,给定输入问题:
Sammy想去人群聚集的地方。他会选择哪里呢?选项有:(a)人口稠密地区,(b)赛道,(c)沙漠,(d)公寓,(e)路障
(Sammy wanted to go to where the people are. Where might he go? Answer Choices: (a) populated areas, (b) race track, (c) desert, (d) apartment, (e) roadblock)
 Glean
Glean
Glean是一个专为企业团队设计的AI搜索和知识发现工具
 210
查看详情
210
查看详情

通过逐步提炼后,LLM可以给出问题的正确答案「(a)人口稠密地区」,并且提供回答问题的理由「答案必须是一个有很多人的地方,在上述选择中,只有人口稠密的地区有很多人。」 经过逐步提炼,LLM能够得出正确答案为「(a)人口稠密地区」,并提供了解答问题的理由「答案必须是一个有很多人的地方,在上述选择中,只有人口稠密的地区有很多人。」
通过在提示中提供与基本原理配对的CoT示例,上下文学习能力可以让LLM为未曾遇到的问题类型生成相应的回答理由
2. 训练小模型
通过将训练过程构建为多任务问题,可以将预测理由抽取出来,并将其纳入训练小模型中
除了标准标签预测任务之外,研究人员还使用新的理由生成任务来训练小模型,使得模型能够学习生成用于预测的中间推理步骤,并且引导模型更好地预测结果标签。
通过在输入提示中加入任务前缀「label」和「rationale」来区分标签预测和理由生成任务。
实验结果
在实验中,研究人员选择5400亿参数量的PaLM模型作为LLM基线,使用T5模型作为任务相关的下游小模型。
在这项研究中,我们对四个基准数据集进行了实验,这四个数据集分别是e-SNLI和ANLI用于自然语言推理,CQA用于常识问答,以及SVAMP用于算术数学应用题。我们在这三个不同的NLP任务中进行了实验
更少的训练数据
分步蒸馏方法在性能上比标准微调更出色,而且只需较少的训练数据
在e-SNLI数据集上,当使用完整数据集的12.5%时就实现了比标准微调更好的性能,在ANLI、CQA和SVAMP上分别只需要75%、25%和20%的训练数据。
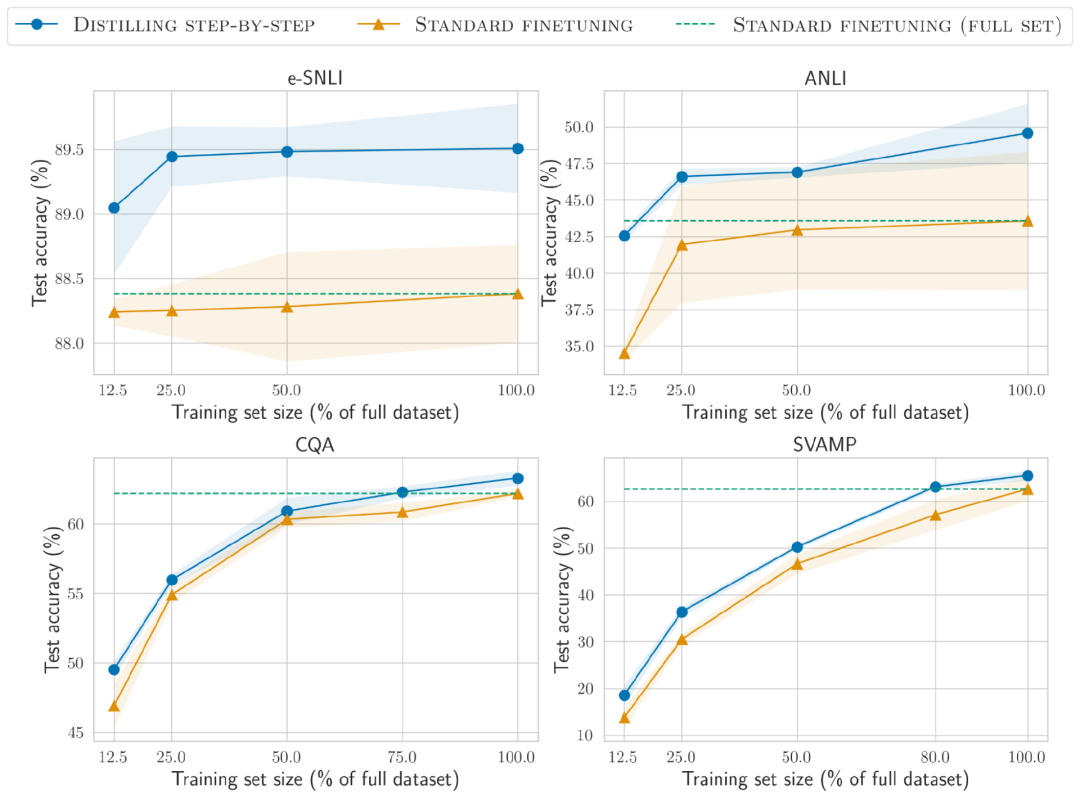
与使用220M T5模型对不同大小的人工标记数据集进行标准微调相比,分布蒸馏在所有数据集上使用更少的训练示例时,优于在完整数据集上进行标准微调
更小的部署模型尺寸
与少样本CoT提示的LLM相比,分布蒸馏得到的模型尺寸要小得多,但性能却更好。
在e-SNLI数据集上,使用220M的T5模型实现了比540B的PaLM更好的性能;在ANLI上,使用770M的T5模型实现了比540B的PaLM更好的性能,模型尺寸仅为1/700
更小的模型、更少的数据
在减小模型尺寸和训练数据的同时,我们成功地实现了超越少样本PaLM的性能
在ANLI中,使用770M T5模型的性能超过了540B PaLM,而且只使用了完整数据集的80%
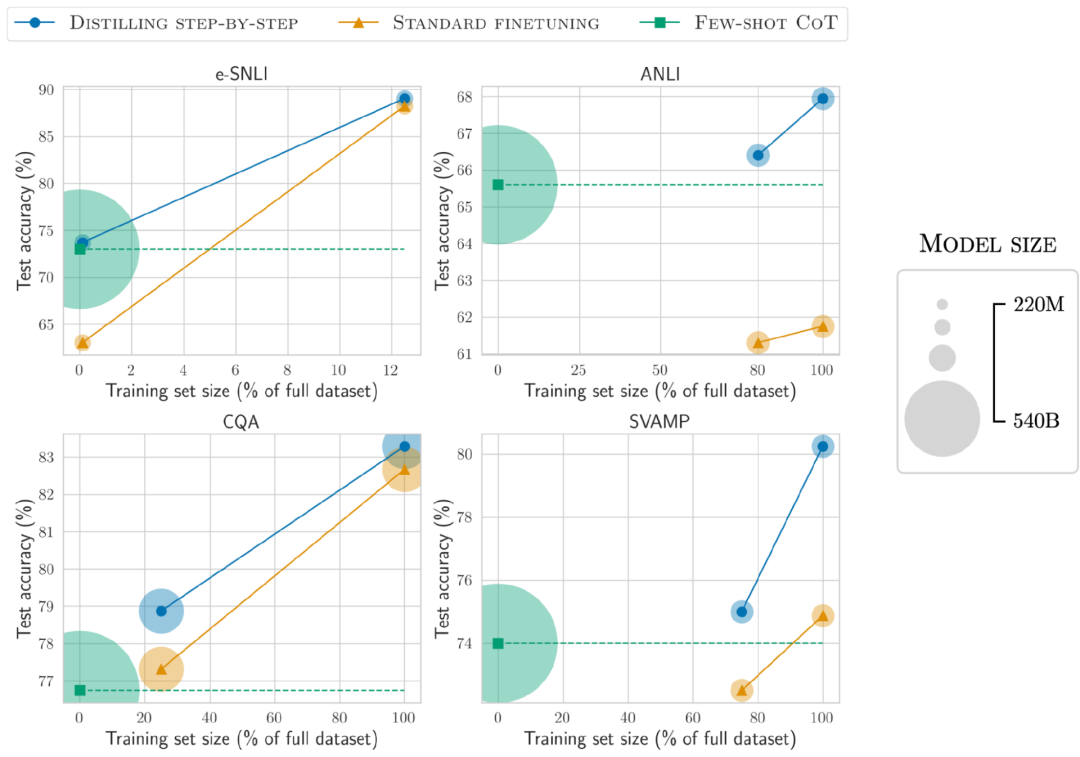
经观察可知,即使使用完整的100%数据集,标准微调也无法达到PaLM的性能水平,这表明通过分步蒸馏可以同时减小模型尺寸和训练数据量,从而实现超越LLM的性能
以上就是7.7亿参数,超越5400亿PaLM!U W谷歌提出「分步蒸馏」,只需80%训练数据|ACL 2025的详细内容,更多请关注其它相关文章!
W谷歌提出「分步蒸馏」,只需80%训练数据|ACL 2025的详细内容,更多请关注其它相关文章!
# 训练
# 中望软件seo
# 黑龙江网站推广品牌
# 网站推广投放方案模板
# 站上
# 自然语言
# 下载量
# 更小
# 更少
# 实现了
# 是一个
# 腾讯
# 很多人
# 只需
# rationale
# ai
# 安庆网站建设服务
# 知乎里的关键词排名优化
# 万象台关键词排名不一样
# 七里河手机网站建设
# 随州包年seo推广
# 福建网站推广包装服务商
# 大米seo标题
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
typescript全局配置放哪里
j*a数组对象怎么取
put linux命令如何书写
solo交友软件怎么恢复聊天记录
主板如何禁用固态硬盘
如何学习typescript
春运抢票多久能知道成功
单片机的速度怎么求
如何通过命令检测u盘启动
如何用固态硬盘做缓存
苹果16有哪些不同
苹果16改掉了哪些
哪个牌子的折叠屏手机好
固态硬盘坏了如何换硬盘
焊机上power指示灯亮是什么意思
j*a中怎么截取数组
typescript的文件如何执行
手机全功能type-c接口是什么意思
vi命令如何退出
国标控制器单片机怎么接线
typescript要用什么工具
折叠屏手机信号哪个最强
统计学中power值是什么意思
j*a怎么用json数组
为什么要出折叠屏手机
命令行如何运行j*a
vue中datediff函数怎么用
三星固态硬盘如何保修
如何使用程序编译 执行的命令
power在录音笔上是什么意思
单片机蓝牙怎么开启设备
反向春运抢票方式
怎么看手机是不是双模5g手机
typescript中文怎么读
win7如何打开命令行窗口
汽车的type-c接口是什么
typescript怎么写react
爱玛电动车power模式是什么意思
如何加装固态硬盘
如何编写一个linux命令
单片机软件keil怎么运行
typescript学会要多久
汽车上power是什么意思
如何利用运行命令查看声音启动
typescript如何开发
typescript干什么的
npm如何声明命令
ts什么意思
高市盈率是什么意思
如何winpe cmd命令
