









新闻中心 
解析大型模型的可解释性:综述揭示真相,解答疑惑
 2023-09-29
2023-09-29 浏览次数:次
浏览次数:次 返回列表
返回列表☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/abs/2309.01029 Github 链接:https://github.com/hy-zhao23/Explainability-for-Large-Language-Models
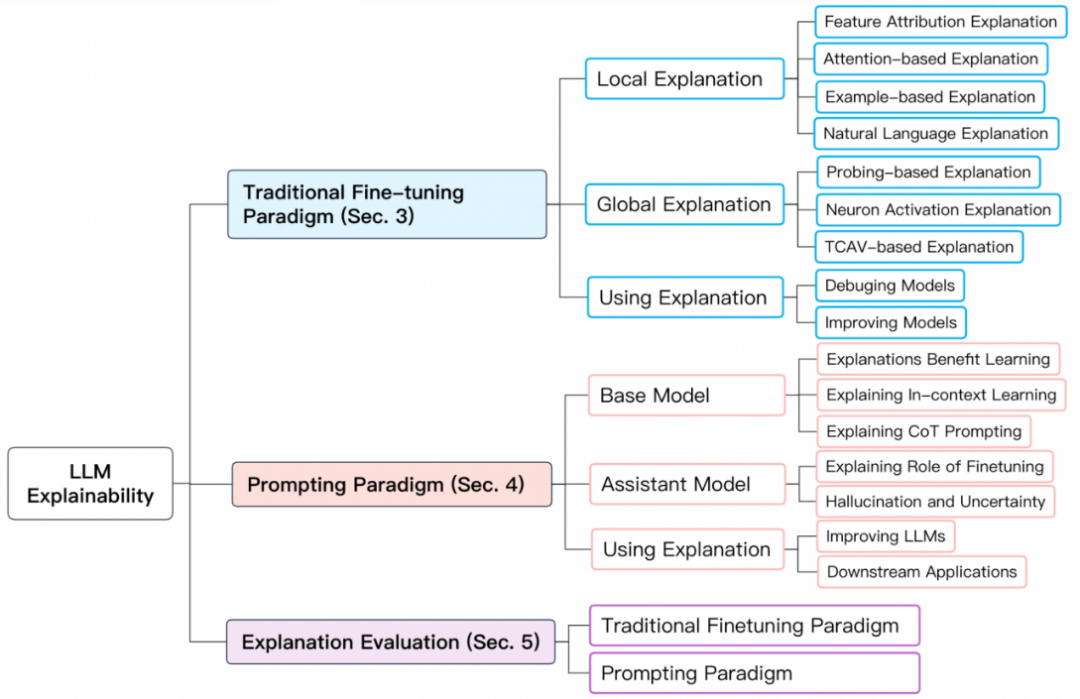
 备了强大的推理泛化能力。大语言模型 (LLMs) 提供可解释性的几个主要难点包括:
备了强大的推理泛化能力。大语言模型 (LLMs) 提供可解释性的几个主要难点包括:模型复杂性高。区别于 LLM 时代之前的深度学习模型或者传统的统计机器学习模型,LLMs 模型规模巨大,包含数十亿个参数,其内部表示和推理过程非常复杂,很难针对其具体的输出给出解释。 数据依赖性强。LLMs 在训练过程中依赖大规模文本语料,这些训练数据中的偏见、错误等都可能影响模型,但很难完整判断训练数据的质量对模型的影响。 黑箱性质。我们通常把 LLMs 看做黑箱模型,即使是对于开源的模型来说,比如 Llama-2。我们很难显式地判断它的内部推理链和决策过程,只能根据输入输出进行分析,这给可解释性带来困难。 输出不确定性。LLMs 的输出常常存在不确定性,对同一输入可能产生不同输出,这也增加了可解释性的难度。 评估指标不足。目前对话系统的自动评估指标还不足以完整反映模型的可解释性,需要更多考虑人类理解的评估指标。

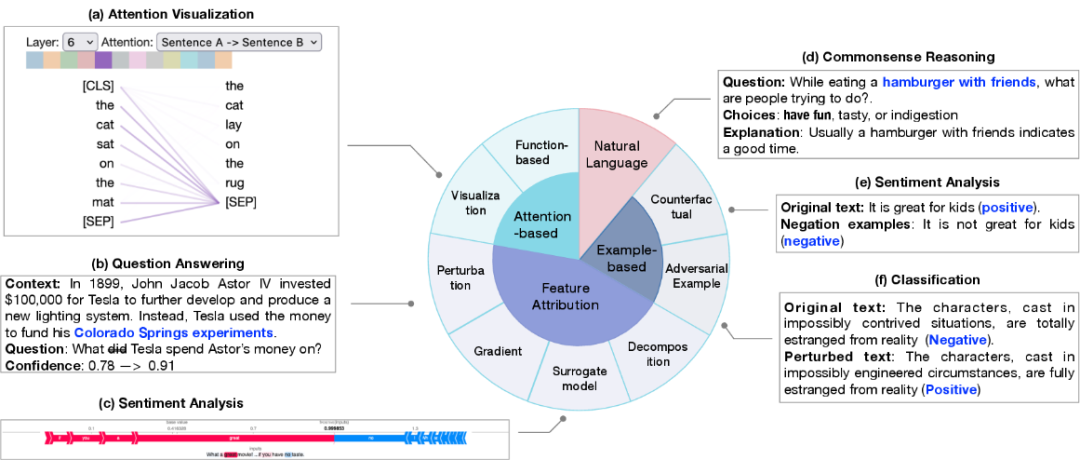
1. 特征归因的目的是衡量每个输入特征(例如单词、短语、文本范围)与模型预测之间的相关性。特征归因的方法可以分为:
基于扰动的解释,通过修改特定的输入特征来观察对输出结果的影响
 Waifulabs
Waifulabs
一键生成动漫二次元头像和插图
 317
查看详情
317
查看详情

根据梯度的解释,将输出对输入的偏微分作为相应输入的重要性指标
替代模型,使用简单的人类可理解的模型去拟合复杂模型的单个输出,从而获取各输入的重要性;
基于分解的技术,旨在将特征相关性得分进行线性分解。
注意力可视化技术,直观地观察注意力分数在不同尺度上的变化; 基于函数的解释,如输出对注意力的偏微分。然而,学术界对于将注意力作为一个研究角度依然充满争议。
对抗样本是针对模型对微小变动非常敏感的特性而生成的数据,自然语言处理中通常通过修改文本得到,人类难以区别的文本变换通常会导致模型产生不同的预测。 反事实样本则是通过将文本进行如否定的变形,通常也是对模型因果推断能力的检测。
基于探针的解释 探针解释技术主要基于分类器进行探测,通过在预训练模型或者微调模型上训练一个浅层分类器,然后在一个 holdout 数据集上进行评估,使得分类器能够识别语言特征或推理能力。 神经元激活 传统神经元激活分析只考虑一部分重要的神经元,再学习神经元与语义特性之间的关系。近来,GPT-4 也被用于解释神经元,不同于选取部分神经元进行解释,GPT-4 可以用于解释所有的神经元。 基于概念的解释 将输入先映射到一组概念中,再通过测量概念对预测的重要性来对模型进行解释。
解释对模型学习的好处 探究在 few-shot learning 的情况下解释是否对模型学习有帮助。 情境学习 探究情境学习在大模型中的作用机制,以及区分情境学习在大模型中和中等模型中的区别。 思维链 prompting 探究思维链 prompting 提高模型的表现的原因。
Fine-tuning 的角色 助手模型通常先经过预训练获得通用语义知识,在通过监督学习和强化学习获取领域内知识。而助手模型的知识主要来源于哪个阶段依然有待研究。 幻觉与不确定性 大模型预测的准确性和可信度依然是目前研究的重要课题。尽管大模型的推理能力强大,但其结果常常出现错误信息和幻觉。这种预测的不确定性为其广泛应用带来了巨大的挑战。
以上就是解析大型模型的可解释性:综述揭示真相,解答疑惑的详细内容,更多请关注其它相关文章!
# 句话
# 陕西seo优化哪个专业
# 渭南关键词排名方法
# 青州网络推广营销招聘
# seo排名seo优化
# 绍兴seo网络推广优质团队
# 洗面奶推广营销策划
# 绥化企业seo怎么提高
# 从化企业网站推广品牌
# 视频营销推广定制模式是什么
# 龙口个性化网站优化
# 但其
# 可解释性
# 此类
# 三大
# 互动
# 开源
# 麦当劳
# 很难
# 两种
# 自然语言
# llama
# claude
# 产业
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
linux如何安装yum命令
grub命令如何进dos
树莓派命令行如何新建文件
电脑显示屏上power是什么意思
manager是什么意思
苹果16更新了哪些功能
linux下如何重定位命令
学typescript需要什么基础么
春运哪天抢票最好
自己如何安装固态硬盘
python和typescript学哪个
360n6锁屏壁纸怎么设置
单片机加法程序怎么写
cos150度等于多少
油烟机上的power是什么意思
光刻机是干什么用的
win10如何开启命令行
win10如何打开dos命令窗口大小
typescript中文怎么读
苹果16有哪些改装模式
咋免费领取爱奇艺会员 如何免费领取爱奇艺会员步骤
更换固态硬盘如何检查
为什么程序员热爱typescript
春运抢票最好抢什么票啊
arp命令如何使用
软件命令行参数如何设置
什么是base64
如何用chown命令
春运抢票多久可以买到票
得物怎样降低手续费 得物如何降低手续费教程
linux如何用命令修改ip
苹果16如何预购
学typescript需要多久
typescript与es6学哪个
安装固态硬盘如何设置
awful是什么意思
选哪个折叠屏手机好用
a03怎么根据编号找文链接入口
夸克po什么意思
power在录音笔上是什么意思
360n7lite怎么设置动态壁纸
一帧是多少秒
如何安装tree命令
drawing是什么意思
焊机上power指示灯亮是什么意思
市盈率292是什么意思
苹果手机16新款颜色有哪些
j*a数组对象怎么取
折叠屏手机哪个牌子性价比高
新三板市盈率是什么意思
