基于 Transformer 的大型语言模型(LLM)已经展现出执行上下文学习(ICL)的强大能力,并且几乎已经成为许多自然语言处理(NLP)任务的不二选择。Transformer 的自注意力机制可让训练高度并行化,从而能以分布式的方式处理长序列。LLM 训练所用的序列的长度被称为其上下文窗口。
Transformer 的上下文窗口直接决定了可以提供示例的空间量,从而限制了其 ICL 能力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 如果模型的上下文窗口有限,那么为模型提供稳健示例的空间就更少,而这些稳健示例正是执行 ICL 所用的。此外,当模型的上下文窗口特别短时,摘要等其它任务也会受到严重妨碍。就语言本身的性质来说,token 的位置对有效建模来说至关重要,而自注意力由于其并行性,并不会直接编码位置信息。Transformer 架构引入了位置编码来解决这个问题。原始的 Transformer 架构使用了一种绝对正弦位置编码,之后其被改进成了一种可学习的绝对位置编码。自那以后,相对位置编码方案又进一步提升了 Transformer 的性能。目前,最流行的相对位置编码是 T5 Relative Bias、RoPE、XPos 和 ALiBi。位置编码有一个反复出现的限制:无法泛化在训练期间看到的上下文窗口。尽管 ALiBi 等一些方法有能力做一些有限的泛化,但还没有方法能泛化用于显著长于其预训练长度的序列。已经出现了一些试图克服这些限制的研究成果。比如,有研究提出通过位置插值(PI)来稍微修改 RoPE 并在少量数据上微调来扩展上下文长度。两个月前,Nous Research 的 Bowen Peng 在 Reddit 分享了一种解决思路,即通过纳入高频损失来实现「NTK 感知型插值」。这里的 NTK 是指 Neural Tangent Kernel(神经正切核)。其声称经过 NTK 感知型扩展的 RoPE 能让 LLaMA 模型的上下文窗口大幅扩展(超过 8k),同时还无需任何微调,对困惑度造成的影响也极小。
如果模型的上下文窗口有限,那么为模型提供稳健示例的空间就更少,而这些稳健示例正是执行 ICL 所用的。此外,当模型的上下文窗口特别短时,摘要等其它任务也会受到严重妨碍。就语言本身的性质来说,token 的位置对有效建模来说至关重要,而自注意力由于其并行性,并不会直接编码位置信息。Transformer 架构引入了位置编码来解决这个问题。原始的 Transformer 架构使用了一种绝对正弦位置编码,之后其被改进成了一种可学习的绝对位置编码。自那以后,相对位置编码方案又进一步提升了 Transformer 的性能。目前,最流行的相对位置编码是 T5 Relative Bias、RoPE、XPos 和 ALiBi。位置编码有一个反复出现的限制:无法泛化在训练期间看到的上下文窗口。尽管 ALiBi 等一些方法有能力做一些有限的泛化,但还没有方法能泛化用于显著长于其预训练长度的序列。已经出现了一些试图克服这些限制的研究成果。比如,有研究提出通过位置插值(PI)来稍微修改 RoPE 并在少量数据上微调来扩展上下文长度。两个月前,Nous Research 的 Bowen Peng 在 Reddit 分享了一种解决思路,即通过纳入高频损失来实现「NTK 感知型插值」。这里的 NTK 是指 Neural Tangent Kernel(神经正切核)。其声称经过 NTK 感知型扩展的 RoPE 能让 LLaMA 模型的上下文窗口大幅扩展(超过 8k),同时还无需任何微调,对困惑度造成的影响也极小。
- 论文:https://arxiv.org/abs/2309.00071
- 模型:https://github.com/jquesnelle/yarn
在这篇论文中,他们对 NTK 感知型插值做出了两点改进,它们分别侧重于不同的方面:
- 动态 NTK 插值法,无需微调就能用于预训练模型。
- 部分 NTK 插值法,当使用少量更长上下文的数据微调后,模型能取得最佳表现。
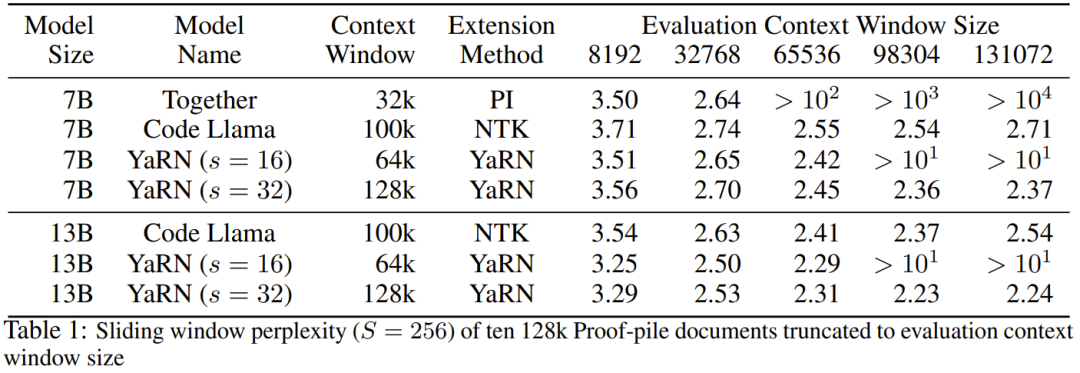
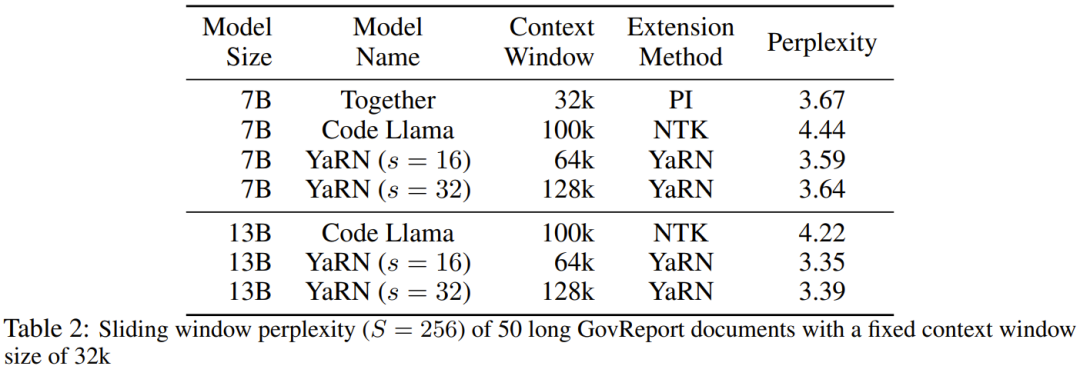
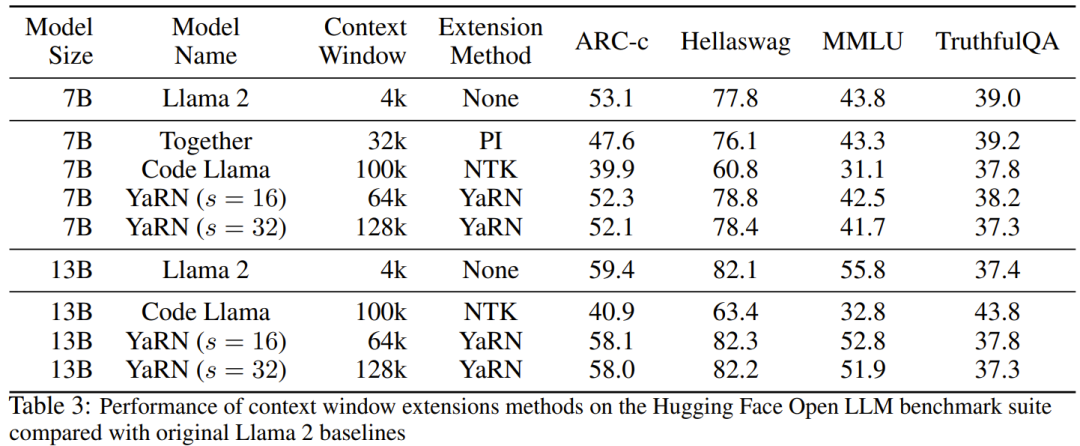
研究者表示,在这篇论文诞生前,就已经有研究者将 NTK 感知型插值和动态 NTK 插值用于一些开源模型。比如 Code Llama(使用 NTK 感知型插值)和 Qwen 7B(使用动态 NTK 插值)。在这篇论文中,基于之前有关 NTK 感知型插值、动态 NTK 插值和部分 NTK 插值的研究成果,研究者提出了 YaRN(Yet another RoPE extensioN method),一种可以高效扩展使用旋转位置嵌入(Rotary Position Embeddings / RoPE)的模型的上下文窗口的方法,可用于 LLaMA、GPT-NeoX 和 PaLM 系列模型。研究发现,只需使用原模型预训练数据规模大约 0.1% 量的代表性样本进行微调,YaRN 就能实现当前最佳的上下文窗口扩展性能。旋转位置嵌入(Rotary Position Embeddings / RoPE)最早由论文《RoFormer: Enhanced transformer with rotary position embedding》引入,也是 YaRN 的基础。对于使用固定上下文长度预训练的 LLM,如果使用位置插值(PI)来扩展上下文长度,则可以表示为:可以看出 PI 对所有 RoPE 维度都会做同等延展。研究者发现 PI 论文中描述的理论插值界限不足以预测 RoPE 和 LLM 内部嵌入之间的复杂动态。下面将描述研究者发现并解决的 PI 的主要问题,以便读者了解 YaRN 中各种新方法的背景、起因和解决理由。如果只从信息编码的角度看 RoPE,根据神经正切核(NTK)理论,如果输入维度较低且对应的嵌入缺乏高频分量,那么深度神经网络难以学习高频信息。为了解决在对 RoPE 嵌入插值时丢失高频信息的问题,Bowen Peng 在上述 Reddit 帖子中提出了 NTK 感知型插值。这种方法不会对 RoPE 的每个维度进行同等扩展,而是通过更少地扩展高频和更多地扩展低频来将插值压力分散到多个维度。在测试中,研究者发现在扩展未经微调的模型的上下文大小方面,这种方法优于 PI。但是,这种方法有一个重大缺点:由于它不只是一种插值方案,某些维度会被外推入一些「界外」值,因此使用 NTK 感知型插值进行微调的效果不及 PI。更进一步说,由于存在「界外」值,理论上的扩展因子就无法准确地描述真实的上下文扩展程度。在实践中,对于给定的上下文长度扩展,必须将扩展值 s 设置得比期望的扩展值高一点。对于 RoPE 嵌入,有一个有趣的观察:给定一个上下文大小 L,存在某些维度 d,其中的波长 λ 长于预训练阶段见过的最大上下文长度(λ > L),这说明某些维度的嵌入可能在旋转域中的分布不均匀。PI 和 NTK 感知型插值会平等地对待所有 RoPE 隐藏维度(就好像它们对网络有同样的效果)。但研究者通过实验发现,网络会给某些维度不同于其它维度的待遇。如前所述,给定上下文长度 L,某些维度的波长 λ 大于或等于 L。由于当一个隐藏维度的波长大于或等于 L 时,所有的位置配对会编码一个特定的距离,因此研究者猜想其中的绝对位置信息得到了保留;而当波长较短时,网络仅可获得相对位置信息。当使用扩展比例 s 或基础变化值 b' 来拉伸所有 RoPE 维度时,所有 token 都会变得与彼此更接近,因为被一个较小量旋转过的两个向量的点积会更大。这种扩展会严重损害 LLM 理解其内部嵌入之间小的局部关系的能力。研究者猜测这种压缩会导致模型对附近 token 的位置顺序感到困惑,从而损害模型的能力。为了解决这个问题,基于研究者观察到的现象,他们选择完全不对更高频率的维度进行插值。他们还提出,对于所有维度 d,r β 的维度就完全不插值(总是外推)。使用这一小节描述的技术,一种名为部分 NTK 插值的方法诞生了。这种改进版方法优于之前的 PI 和 NTK 感知型插值方法,其适用于无微调和已微调模型。因为该方法避免了对旋转域分布不均匀的维度进行外推,因此就避免了之前方法的所有微调问题。 当使用 RoPE 插值方法无微调地扩展上下文大小时,我们希望模型在更长的上下文大小上慢慢地劣化,而不是在扩展度 s 超过所需值时在整个上下文大小上完全劣化。在动态 NTK 方法中,扩展度 s 是动态计算的。在推理过程中,当上下文大小被超过时,就动态地更改扩展度 s,这样可让所有模型在达到训练的上下文限制 L 时缓慢地劣化而不是突然崩溃式劣化。 即便解决了前面描述的局部距离问题,为了避免外推,也必须在阈值 α 处插值更大的距离。直觉来看,这似乎不应该是个问题,因为全局距离无需高精度也能区分 token 位置(即网络只需大概知道 token 是在序列的开头、中间或末尾即可)。但是,研究者发现:由于平均最小距离随着 token 数量的增加而变得更近,因此它会使注意力 softmax 分布变得更尖(即减少了注意力 softmax 的平均熵)。换句话说,随着长距离衰减的影响因插值而减弱,网络会「更加关注」更多 token。这种分布的转变会导致 LLM 输出质量下降,这是与之前问题无关的另一个问题。由于当将 RoPE 嵌入插值到更长的上下文大小时,注意力 Softmax 分布中的熵会减少,因此研究者的目标是逆转这种熵减(即增加注意力 logit 的「温度」)。这可以通过在应用 softmax 之前将中间注意力矩阵乘以温度 t > 1 来完成,但由于 RoPE 嵌入被编码为一个旋转矩阵,就可以简单地按常数因子 √t 来扩展 RoPE 嵌入的长度。这种「长度扩展」技巧让研究可以不必修改注意力代码,这能大幅简化与现有训练和推理流程的集成,并且时间复杂度仅有 O (1)。由于这种 RoPE 插值方案对 RoPE 维度的插值不均匀,因此很难计算相对于扩展度 s 所需的温度比例 t 的解析解。幸运的是,研究者通过实验发现:通过最小化困惑度,所有 LLaMA 模型都遵循大致相同的拟合曲线:研究者是在 LLaMA 7B、13B、33B 和 65B 上发现这个公式的。他们发现这个公式也能很好地适用于 LLaMA 2 模型(7B、13B 和 70B),差别很细微。这表明这种熵增特性很常见,可以泛化到不同的模型和训练数据。这种最终修改方案产出了 YaRN 方法。新方法在已微调和未微调场景中都胜过之前所有方法,而且完全不需要修改推理代码。只需要修改一开始用于生成 RoPE 嵌入的算法。YaRN 如此简单,使其可以在所有推理和训练库中轻松实现,包括与 Flash Attention 2 的兼容性。实验表明 YaRN 能成功扩展 LLM 的上下文窗口。此 外,他们仅训练了 400 步就得到了这一结果,这差不多只有模型的原始预训练语料库的 0.1%,与之前的研究成果相比有大幅下降。这说明新方法具有很高的计算效率,没有额外的推理成本。为了评估所得到的模型,研究者计算了长文档的困惑度,并在已有基准上进行了评分,结果发现新方法胜过所有其它上下文窗口扩展方法。首先,研究者评估了上下文窗口增大时模型的性能表现。表 1 总结了实验结果。表 2 展示了在 50 个未截断的 GovReport 文档(长度至少为 16k token)上的最终困惑度。为了测试使用上下文扩展时模型性能的劣化情况,研究者使用 Hugging Face Open LLM Leaderboard 套件评估了模型,并将其与 LLaMA 2 基准模型以及公开可用的 PI 和 NTK 感知型模型的已有分数进行了比较。表 3 总结了实验结果。
外,他们仅训练了 400 步就得到了这一结果,这差不多只有模型的原始预训练语料库的 0.1%,与之前的研究成果相比有大幅下降。这说明新方法具有很高的计算效率,没有额外的推理成本。为了评估所得到的模型,研究者计算了长文档的困惑度,并在已有基准上进行了评分,结果发现新方法胜过所有其它上下文窗口扩展方法。首先,研究者评估了上下文窗口增大时模型的性能表现。表 1 总结了实验结果。表 2 展示了在 50 个未截断的 GovReport 文档(长度至少为 16k token)上的最终困惑度。为了测试使用上下文扩展时模型性能的劣化情况,研究者使用 Hugging Face Open LLM Leaderboard 套件评估了模型,并将其与 LLaMA 2 基准模型以及公开可用的 PI 和 NTK 感知型模型的已有分数进行了比较。表 3 总结了实验结果。以上就是想让大模型在prompt中学习更多示例,这种方法能让你输入更多字符的详细内容,更多请关注其它相关文章!
# neural tangent kernel
# 苏州网站建设教学设计
# 马鞍山全网营销推广
# 湛江商城网站推广平台
# 唐山网站优化品牌设计
# 河北网站优化推广优点
# 福山效果好的网站推广
# 品牌推广精准营销策略
# 就能
# 出了
# 更长
# 这一
# 是在
# 这种方法
# 想让
# 让你
# 插值
# 关键词
# hugging face
# transformer
# ntk 感知型插值
# 理论
# 什么是seo教程置顶
# 怎么在百度推广自己网站
# 长春seo网站排名公司
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何弄坏固态硬盘
soup是什么意思
如何查看硬盘是固态硬盘
单片机*计步器怎么用
市盈率ttm写的亏损是什么意思
导航power在汽车上是什么意思
笔记本如何使用固态硬盘
虚拟机如何用命令清除垃圾
春运抢票何时开始抢票的
单片机软件keil怎么运行
皓影混动仪表盘上power是什么意思
固态硬盘坏了如何换硬盘
华为交换机如何复制命令行
夸克搜题的原理是什么
如何打开win10命令
typescript怎么写react
路由器power灯一直亮是什么意思
固态硬盘如何4k对其
路由器上的power按钮是什么意思
typescript参数怎么用
如何在命令提示符播放音频
苹果16有哪些自带配件
宵衣旰食是什么意思
debug中如何用n命令命名程序文件名
苹果16更新了哪些版本
新固态硬盘如何装系统
手机nfc功能功能是什么意思
折叠屏有哪些手机
ts什么意思
win7如何打开命令行窗口
固态硬盘如何装入机箱
税负是什么意思
固态硬盘电脑如何设置
typescript文件怎么打开
台机如何安装固态硬盘
命令行如何启动应用程序
win10锁屏壁纸怎么换360锁屏壁纸吗
如何固态硬盘4k对齐
为什么夸克网盘下载不了
ai怎么找链接文件位置教程
广东春运几点抢票
j*a二数组怎么创建
如何管理员打开cmd命令行窗口
单片机蜂鸣器响了怎么停
j*a数组怎么比较abc
折叠屏手机为什么这么小
一帧是多少秒
如何查找固态硬盘
苹果16送哪些配件
小屏折叠屏手机有哪些











 2023-09-15
2023-09-15 浏览次数:次
浏览次数:次 返回列表
返回列表

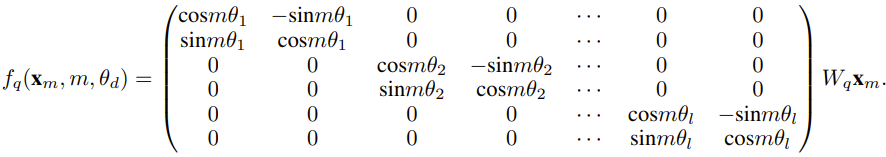
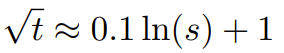
 外,他们仅训练了 400 步就得到了这一结果,这差不多只有模型的原始预训练语料库的 0.1%,与之前的研究成果相比有大幅下降。这说明新方法具有很高的计算效率,没有额外的推理成本。
外,他们仅训练了 400 步就得到了这一结果,这差不多只有模型的原始预训练语料库的 0.1%,与之前的研究成果相比有大幅下降。这说明新方法具有很高的计算效率,没有额外的推理成本。